페이스북 연구팀이 아스키 문자를 사용하는 롤플레잉 게임 넷핵으로 인공지능(AI) 모델을 교육, 테스트, 평가할 수 있다는 연구결과를 발표했다.

벤처비트는 25일(현지시간) 페이스북 연구팀이 강화학습 에이전트의 일반화 및 완성도 평가를 위한 연구 도구 '넷핵 학습환경'을 발표했다고 보도했다.
1987년에 탄생한 RPG 게임 넷핵은 아스키 문자로 한칸씩 대응해 게임그래픽을 표시하는 '로그라이크' 형식을 사용했다. 게임은 지하 던전 50개 이상을 내려가며 마법 부적을 회수하는 임무를 수행하는 게임이다. 수백 가지 아이템을 사용해 몬스터와 싸우면서 다른 플레이어와 협동해 나가는 방식으로 전개한다.
넷핵을 활용하면 AI의 일반화 과정에서 나타나는 문제를 찾을 수 있다. 현재 넷핵에서 작업중인 강화학습 에이젼트는 넷핵 게임 전체 중 일부에서 작동하고 있는데 이러한 도전 환경 속에서 강화학습 에이전트는 발전하기 위해 스스로 백지상태로 초기화하고 다시 학습 한다.
연구팀은 넷핵이 대규모 외부 자원을 포함하고 있어 이를 에이전트의 성능 향상에 활용할 것으로 기대하고 있다. 예를 들어 플레이어의 리플레이를 저장해 모델은 필요시 이를 불러들여 학습할 수 있다. 또한 공식 넷핵 가이드북, 넷핵 위키, 온라인 비디오 및 포럼 토론 등의 자료도 있다.
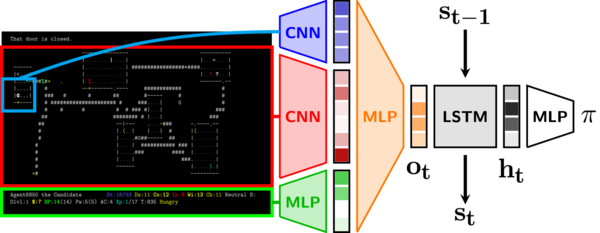
넷핵 학습 환경은 ▲오픈AI Gym API ▲벤치마크 과제 모음 ▲토치비스트, 임팔라의 파이토치 활용을 기초로 하는 강화학습 에이전트로 이뤄져 있다.
이 외에도 에이전트의 진행 상황을 측정하기 위해 특별히 설계된 7가지 벤치마크 작업은 다음과 같다.
- 계단 : 지하 감옥 내려 가기
- 세트 : 애완 동물 돌보기 (생전을 유지하고 지하 감옥으로 더 깊이 들어 가라)
- 독이 없는 음식을 찾아서 먹기
- 골드 : 던전 내내 골드 수집
- 스카우트 : 가능한 많은 던전 보기
- 점수 : 게임 내 점수 획득 (예 : 몬스터 처치, 내림차순, 금 수집)
- 오라클 : 중요한 랜드 마크 오라클에 도달하기 (던전에 4-9 레벨이 나타남)
넷핵은 현재 방법에서 가장 가까운 과제를 제시한다. 따라서 다른 까다로운 시뮬레이션 환경의 계산 비용이 들지 않는 장점이 있다.
또한 경량 아키텍처에서 돌아가며 차례대로 움직이는 아스키 아트 세계와 C언어로 만든 게임 엔진에서 다양한 복잡도를 잡아낸다. 가장 간단한 물리학을 제외한 모든 것을 버리고 픽셀 대신 심볼을 렌더링한다. 중요한 것은 역학 시뮬레이션 또는 관측 렌더링에 계산 리소스를 낭비하지 않고 모델이 빠르게 학습 할 수 있도록 하는 것이다.
따라서 넷핵 학습 환경에서는 강화학습 에이전트에게 충분한 경험을 제공, 결과가 나오기를 기다리는 대신 새로운 아이디어를 시험하는 데 시간을 할애할 수 있다.
실제로 클라우드에서 정교한 머신러닝 모델을 훈련하는 것은 엄청나게 비싸다. 최근 나온 보고서에 따르면 가짜 뉴스의 생성 및 검출을 모두 맞춘 미국 그로버 대학은 2주 과정 훈련에 25000달러를 지출했다. 오픈AI는 GPT-2 언어 모델 을 교육하기 위해 시간당 256달러, 구글은 11개의 자연어처리(NLP) 작업을 위해 양방향 트랜스포머 모델 BERT 교육에 6912달러를 투자했다.
반대로, 단일 고급 그래픽 카드는 토치비스트 프레임 워크를 사용해 AI 넷핵 에이전트를 하루에 수억 단계 씩 훈련시키기에 충분하다. 에이전트들은 현재 AI 기술이 달성 할 수있는 한계에 도전하고 있다. 이 과정에서 충분한 시간 내에 수십억 단계의 환경을 경험할 수 있다.
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com