GUI상에서 다단계 명령어→행동 변환 위한 중요한 단계 실현
손 안대고 스마트폰 앱 말로 작동···시각장애자들에게도 유용

말로 스마트폰 앱을 작동시킬 수 있는 길이 열렸다. 시각 장애인뿐만 아니라 다른 작업을 하느라 모바일 기기를 터치하지 못하는 상황에 놓인 사용자도 음성으로 간편하게 모바일기기를 작동시킬 수 있게 됐다.
벤처비트는 10일(현지시간) 구글 연구진이 AI툴을 통해 모바일기기 사용자들이 자연어 명령으로 모바일 앱 동작을 실행시킬 수 있도록 하는 데 성공했다고 보도했다.
올해 컴퓨터언어학협회(ACL) 컨퍼런스에 접수된 연구논문에서 구글 연구진은 앱 조작 필요성을 완화하는 모델을 훈련시키기 위한 언어자료들(말뭉치)을 제안하고 있는데 이는 시각장애인에게도 유용할 것으로 기대된다.
구글 연구진은 생일 케이크를 굽는 레시피를 따르는 것처럼 사람들이 일련의 행동을 포함하는 과제를 완성하고 협력을 조정할 때, 서로에게 지시하는 것에 주목했다. 이들은 이를 염두에 두고 AI에이전트들이 유사한 상호작용을 도울 수 있도록 기준을 확립했다.
AI에이전트는 최대한의 보상을 얻기 위해 시행착오를 거치며 여러 번의 반복으로 가장 효율적인 길을 스스로 탐색하는 AI환경 속 시스템이다.
연구진은 이 에이전트들은 일련의 명령이 주어지면 앱이 한 화면에서 다른 화면으로 전환될 때 만들어지는 화면과 대화형 요소는 물론 일련의 앱 연속 동작을 이상적으로 예측할 수 있도록 했다.
구글 연구진은 논문에서 행동-구문 추출 단계(action-phrase extraction step)와 가르치는 단계(grounding step)로 구성된 2단계 솔루션을 설명하고 있다.
1단계인 행동-구문 추출은 트랜스포머(Transformer·번역)모델을 사용한 다단계 명령에서 작동(operation), 객체(object) 및 논점 설명(argument descriptions)을 식별한다. (모델 내의 ‘영역 참여(area attention)’ 모듈을 사용하면 설명을 풀어내기 위한 전반적인 명령 인접 단어 그룹에 참여할 수 있다.)
2단계인 교육(grounding)은 추출된 작업(operation)과 객체 설명(object descriptions)을 화면의 사용자인터페이스(UI) 객체와 일치시킨다. 여기에 또다시 트랜스포머(Transformer) 모델을 사용하는데 이는 맥락에 맞게 UI 객체를 표시하고(represent), 그들에게 객체설명을 교육(grounds)한다.
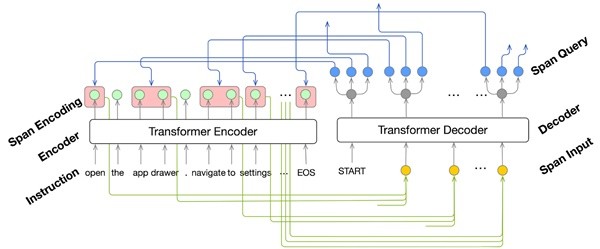
공동 저자들은 액션-구문 추출 및 AI 교육 모델을 훈련하고 평가하기 위한 다음과 같은 세 가지 새로운 데이터 세트를 개발했다.
첫 번째 것은 구글 픽셀폰의 작동 및 그에 상응하는 액션-스크린 시퀀스를 위한 187개의 다단계 영어 명령어를 포함하고 있다.
두 번째 것은 웹에서 나온 영어로 된 ‘어떻게(how-to)’ 명령어와 각 액션(action)을 설명하는 주석을 단 구절을 포함한다.
세 번째 것은 공용 안드로이드 UI 말뭉치를 통해 찾아낸 2만5000개 모바일 UI 화면에 걸쳐 있는 17만8000개의 UI 객체를 포함하는 UI 액션에 대한 29만5000개의 단일 단계 명령어가 포함돼 있다.
그들은 영역 참여 트랜스포머가 참조자료(ground-truth) 결과와 완전히 일치하는 스팬 시퀀스(span sequence)를 예측하는 데 있어서 85.56%의 정확도를 보였다고 보고했다.
한편, 어구 추출기와 교육 모델은 언어 명령을 끝단에서(end-to-end) 실행할 수 있는지를 매핑하는 좀더 더 어려운 작업에서도 참조자료 액션 시퀀스 일치도에서 모두 89.21%의 부분 정확도와 70.59%의 완전 정확도를 얻었다.
참조자료는 데이터세트의 형상,속성 등에 대한 정확성과 완성도를 검증할 때 현장검증을 대신할 수 있는 말그대로 정확성과 완성도를 참조하기 위한 자료다.
연구원들은 깃허브의 오픈 소스를 통해 이용할 수 있는 데이터 세트, 모델 및 결과는 모두 모바일 UI 액션에 자연어 명령어로 교육하는 어려운 문제를 해결하기 위한 중요한 첫 단추를 제공한다고 주장한다.
구글 검색 과학자인 양리는 블로그 포스트에서 “이 연구와 일반적인 언어교육은 다단계 명령어를 GUI상에서 액션으로 변환하기 위한 중요한 단계다”라고 썼다.
그는 “언어 인터페이스가 시각장애인에게 도움을 줄 UI 영역의 작업자동화를 성공적으로 적용할 수 있다면 접근성을 엄청나게 향상시킬 수 있다”면서 “이는 또한 손으로 다른 작업을 하면서 단말기에 접근할 수 없는 상황에서 중요하다”고 강조했다.
[관련기사] 아틀라스랩스, 통화를 문자로 전환해주는 AI 전화 ‘스위치’ 출시
[관련기사] AI 음성인식 서비스 20대 42%가 이용
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com