4대 클라우드 탑재 AI 가속기 중 97%가 엔비디아
엔비디아, A100 GPU로 1위 굳히기!
AMD, 아직은 부족한 성능…2022년 RDNA3로 역전 가능할까?

AI 가속기 시장은 병렬 연산에 특화된 GPU(그래픽처리유닛)가 지배한다고 해도 과언이 아니다. 더 정확하게 말하자면 엔비디아의 GPU가 전체 AI 가속기 시장을 압도하고 있다. 4대 클라우드에 사용되는 AI 가속기의 97%를 점유하고 있다.
최근 엔비디아의 GPU가 독점하고 있는 AI 가속기 시장에 AMD가 도전하고 나섰다. AMD는 새로운 아키텍처로 시장점유율 확대를 추진하는 GPU 생산 기업이다.
업계 관계자들은 엔비디아가 AI 가속기 시장을 개척하며 전체 시장을 독점했지만 경쟁 GPU 회사나 FPGA(field programmable gate array) 등 다른 프로세서 기반 가속기가 등장하면서 전체 시장 점유율의 변동이 있을 것으로 보고 있다.
다만 아직은 엔비디아가 구축한 시장이 탄탄해 시스템을 변화시킬 새로운 시스템이 나오지 않는 이상 변혁은 어려울 것으로 전망된다.
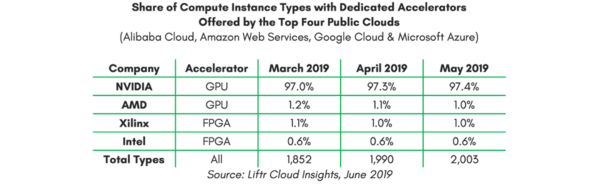
시장조사업체 리프터(Liftr)는 지난해 5월 아마존웹서비스(AWS), 마이크로소프트(MS) 애저, 구글 클라우드, 알리바바 클라우드 등 글로벌 4대 클라우드 데이터센터에서 사용하는 AI 가속기의 97.4%가 엔비디아 가속기라는 조사결과를 발표한 바 있다. AMD GPU는 1%, 자일링스 FPGA 1%, 알테라를 인수한 인텔의 FPGA가 0.6% 정도를 차지하는 수준이었다.
주도권 경쟁은 엔비디아 제품 사이에서 벌어지는 형국이다.
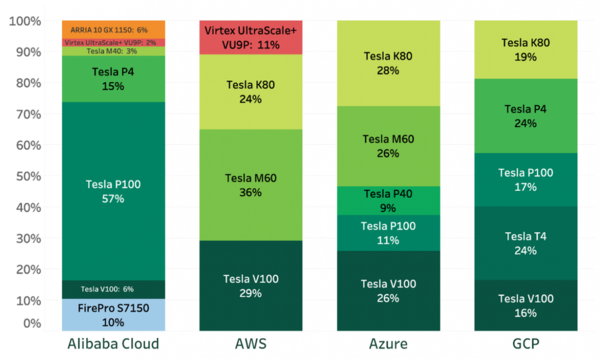
리프터에 따르면 AWS에는 테슬라 M60이 36%, 테슬라 V100이 29%, 테슬라 K80이 24%를 차지했다. 모두 엔비디아의 제품이다. 단 11% 정도가 자일링스의 버텍스 울트라스케일+ VU9P FPGA를 가속기로 사용했다.
MS 애저와 구글 클라우드는 전체가 엔비디아의 테슬라 GPU를 사용했다. 테슬라 K80, M60, P100, T4, V100 GPU가 주로 사용됐다.
중국의 알리바바 역시 엔비디아 GPU를 주로 사용했지만 가장 다양한 업체의 가속기를 채택했다. ▲AMD의 파이어프로 S7150 GPU를 10% ▲인텔 아리아 10 GX 1150 FPGA를 6% ▲자일링스 울트라스케일+ FPGA를 2% 사용했다.
◇엔비디아, 암페어 A100 GPU로 AI칩 시장 1위 굳히기
엔비디아는 지난 5월 새로운 암페어(Ampere) 아키텍처 기반의 A100 GPU를 공개했다. 기존 세대보다 높은 AI 가속 성능으로 AI칩 시장의 1위를 굳히겠다는 전략이다.
A100은 540억개의 트랜지스터를 집적한 것과 같은 성능을 지닌 GPU다. 최대 9.7테라플롭스(TF, 1초에 1조회 연산)의 FP64 연산 능력 등 기존 '볼타(Volta)' 기반의 V100과 비교해 20배 뛰어난 성능을 지녔다.
A100 GPU 8개로 구성한 DGX A100 서버는 5페타플롭스(PF, 1초에 1000조회 연산) 성능을 구현할 수 있다. 가격도 저렴하다. V100 기반 가속기 단가가 2000만달러인데 DGX A100은 300만 달러에 불과하다. 같은 값으로 수십~수백배의 효율을 낼 수 있는 셈이다.
엔비디아에 따르면 국제 슈퍼컴퓨터 컨퍼런스(ISC) 기준에 따르면 세계에서 가장 빠른 슈퍼컴퓨터 10대 가운데 8대가 탑재하고 있다. 또 DGX A100 서버 제조 기업은 이미 30여 개에 달한다. 이들 기업에 제작한 신형 서버는 올여름에 구매할 수 있다. 연말에는 20여 기업이 추가 제작할 전망이다.
◇AMD, RDNA3에 GPU 확장 기술 추가…엔비디아 추격 나서
GPU 시장에서 엔비디아와 라이벌 구도를 형성하고 있는 AMD도 혁신적인 GPU 기술로 AI 가속기 시장에서 영향력을 확대해 나가는 방안을 모색하는 것으로 알려졌다.
AMD는 AI용 가속기로 7나노 기반의 라데온 인스팅트 MI50과 MI60을 생산하고 있다. MI60은 331.46mm의 패키지에 132억개의 트랜지스터를 탑재했다. 최대 7.4TP FP64 연산 성능을 구현한다. 엔비디아가 공개한 A100보다 트랜지스터의 수는 약 1/4 수준이며, 연산 성능도 부족하다.
지난 8일 WCCF테크는 하드웨어 업계 관계자의 트윗을 인용하며 2022년에 출시 예정인 3세대 빅나비(Big Navi) GPU의 확장 기술에 대해 보도했다. AMD의 GPU 확장 기술이 가속기에도 적용되면 엔비디아의 독점 시장 체제를 무너뜨릴 수도 있을 것으로 전망된다.
WCCF테크에 따르면 RDNA3 아키텍처 기반의 3세대 빅 나비는 CPU에 사용되는 젠(Zen)2 아키텍처와 동일한 설계 방법론을 제공하며, AMD의 여러 GPU IP를 통합할 수 있다. AMD가 여러 개의 작은 GPU 노드를 함께 쌓아 더 큰 GPU를 만들 수 있다는 것이다.
여러 GPU 다이를 합쳐 더 큰 GPU를 만들면 더 높은 효율성과 처리량을 얻을 수 있다. 이렇게 하면 GPU 코어를 비약적으로 확장할 수 있다. 엔비디아의 최신 GPU와 코어수에서 맞설 수 있는 셈이다.
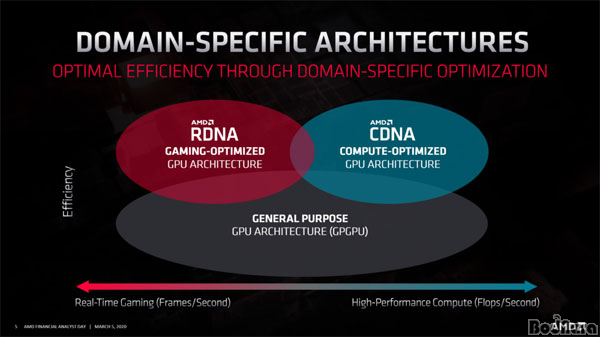
AMD는 RDNA2를 개발하며, GPU 아키텍처를 ▲게이밍용 RDNA ▲컴퓨팅용 CDNA ▲딥러닝에 사용되는 GPGPU(General-Purpose computing on GPU) 등으로 설계 방법을 구분했다. RDNA와 GPGPU의 설계방법이 다르지만, RDNA3의 코어 확장 기술이 AMD의 GPGPU용 가속기인 라데온 인스팅트의 차세대 모델에 충분히 적용될 가능성이 크다.
GPU 기반의 딥러닝 처리인 GPGPU 외에도 FPGA와 관련한 가속기 솔루션이 개발되고 있다. 자일링스, 인텔 알테라, 래티스반도체 등이 AI 관련 솔루션을 내놓고 있으나 아직은 GPGPU보다 성능을 높이기 어려운 상황이다.
새로운 알고리즘으로 성능을 높이는 FPGA보다는 코어 수를 늘려 성능을 높일 수 있는 GPGPU의 특성상, 한동안은 AI칩 시장은 엔비디아와 AMD와 같은 GPU 메이커들의 독주가 지속될 전망이다.
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com