3D 병렬처리 기술로 균형 유지···데이터·모델·파이프라인 병렬 교육
엔비디아 V100 하나로 130억개 변수 AI 교육···‘제로오프로드’ 제공
최첨단 기술 10배 규모 처리···컴퓨팅 부족한 연구원 손쉽게 AI훈련
마이크로소프트(MS)가 컴퓨터 하드웨어(HW)시스템에 지금보다 더 적은 그래픽칩(GPU)을 사용하면서도 수 조 개의 변수를 가진 초거대 인공지능(AI) 모델을 훈련시킬 수 있게 해주는 기술을 개발했다.
MS는 10일(현지시각) 자사의 오픈소스 딥러닝 최적화 라이브러리인 딥스피드(Deep Speed)를 업데이트해 더 적은 GPU를 사용한 HW로도 초거대 AI모델을 훈련시키는 성과를 거두었다고 발표했다.
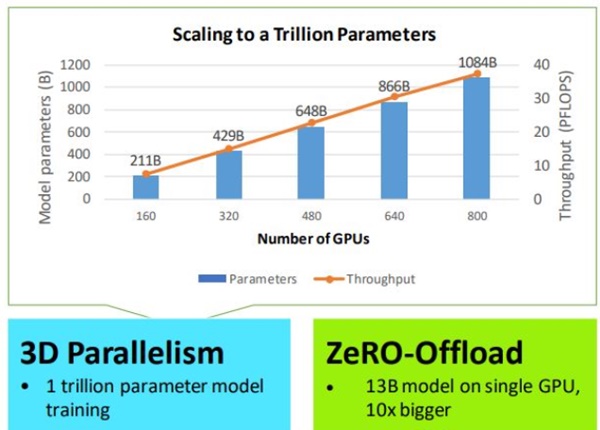
배경이 되는 양대 핵심 기술은 다양한 워크로드 요구사항에 적응하며 매우 큰 AI모델에 힘을 불어넣어주는 ‘3D병렬처리’ 기술, 그리고 엔비디아 V100 하나로 130억개 변수 AI를 교육하는 ‘제로-오프로드’ 기술이다.
딥스피드는 파이토치(PyTorch)를 위한 딥러닝 라이브러리로서 컴퓨팅 성능과 메모리 자원 사용을 줄이고 기존 컴퓨터 HW에서 더 나은 병렬처리로 대형 분산 AI모델을 훈련할 수 있도록 설계됐다. 딥스피드는 짧은 지연시간, 높은 처리량 훈련에 최적화돼 있다. 파이토치는 토치 라이브러리를 기반으로 하는 오픈소스 머신러닝 라이브러리로서 주로 페이스북의 AI 연구소에서 개발한 컴퓨터 비전, 자연어 처리 등에 사용된 무료 오픈소스 소프트웨어다.
MS는 수조 개의 매개변수를 포함하는 예측 AI 모델 훈련을 위한 새로운 접근방식을 도입했다. MS는 딥스피드 성능개선을 위해 ▲데이터 병렬 교육(훈련) ▲모델 병렬 교육 ▲파이프라인 병렬 교육 등 3가지 기술을 활용했다고 밝혔다. 최근 최고 관심주로 등극한 오픈AI사의 자연어 생성 AI모델 GPT-3는 1750억개의 매개 변수로 학습했다.
MS는 3D 병렬처리(3D parallelism)로 불리는 기술이 확장 효율성의 균형을 유지하면서 매우 큰 AI모델에 힘을 불어넣기 위해 다양한 워크로드 요구 사항에 적응하고 있다고 주장했다.
◆똑똑한 AI교육에 드는 엄청난 컴퓨팅 자원 문제 해결 실마리
수십억 개의 매개 변수를 가진 대규모 단일 AI 모델은 다양한 도전 영역에서 큰 발전을 이루었다. 그간 연구는 AI가 언어, 문법, 지식, 개념, 문맥의 뉘앙스를 흡수할 수 있기 때문에 좋은 성과를 낸다는 것을 보여준다. 이는 AI들이 연설을 요약할 수 있고, 라이브 게임 채팅에서 내용을 조절하고, 복잡한 법률 문서를 분류하고, 심지어 깃허브를 뒤져 코드를 생성할 수 있게 만들어 준다.
그러나 AI 모델을 훈련하려면 엄청난 컴퓨팅(계산) 자원이 필요하다. 지난 2018년 나온 오픈AI사의 분석에 따르면 2012년부터 2018년까지 최대 규모의 AI를 교육하는데 사용된 컴퓨팅 용량은 3.5개월마다 두배씩 늘면서 기간중 30만 배 이상 증가했다. 이는 2년마다 약 두배씩 칩의 집적도가 늘어난다는 무어 법칙의 속도를 크게 웃돈다.
1조개의 매개변수를 가진 모델을 교육하려면 최소한 400개의 엔비디아 A100 GPU(각각 40GB의 메모리를 가지고 있다.)의 조합된 메모리가 필요하다.
MS는 이러한 모델 교육을 마치는 데 50% 효율성으로 운영되는 4000개의 엔비디아 A100이 약 100일 동안 가동돼야 할 것으로 추산했다. 이는 MS가 오픈AI와 공동 설계한 AI 슈퍼컴퓨터와는 비교가 안 된다. 이 슈퍼컴에는 1만장 이상의 그래픽 카드가 포함돼 있지만 이같은 규모로도 높은 컴퓨팅 효율성을 달성하기 어려운 경향이 있다.
◆딥스피드는?
딥스피드는 4개의 파이프라인 단계 중 대형 모델들을 소형 구성품(레이어·계층)으로 나눈다.
각 파이프라인 단계 내의 계층들은 실제 훈련을 수행하는 네 명의 ‘작업자(worker)’사이에서 추가로 분할된다. 각 파이프라인은 두 개의 데이터 병렬 인스턴스에 걸쳐 복제되며, 작업자들은 다중 GPU 시스템에 매핑된다.
MS는 이것들과 다른 개선된 성능 덕분에, 1조 개의 변수 모델이 800개의 엔비디아 V100 GPU에 걸쳐 확장된다고 말했다.
또한 최신 딥스피드 버전은 GPU와 호스트 CPU 모두에서 컴퓨팅 및 메모리 리소스를 활용해 하나의 엔비디아 V100에서 최대 130억 개의 변수를 가진 AI모델을 교육할 수 있는 기술인 ‘제로-오프로드(ZeRO-Offload)’를 제공한다.
MS는 이 기술은 최첨단 기술의 10배 규모를 처리하면서 컴퓨팅 자원 부족에 시달리는 데이터 과학자들이 손쉽게 AI훈련을 할 수 있게 해 준다고 주장한다.
MS는 블로그에 올린 글에서 “이 [딥스피드의 이 새로운 기술]은 엄청난 컴퓨팅, 메모리, 통신 효율성을 제공하며, 수십억에서 수조개의 매개 변수를 가진 AI모델 훈련에 힘을 불어넣는다”고 설명했다. 또 “이 기술은 또한 매우 긴 입력 시퀀스를 허용하며, 단일 GPU, 수천 개의 GPU를 가진 하이엔드 클러스터, 또는 매우 느린 이더넷 망을 가진 로엔드 클러스터를 가진 하드웨어 시스템상에서 가동된다…우리는 계속해서 빠른 속도로 혁신해 가면서 딥러닝 훈련을 위한 속도와 규모의 경계를 밀어내고 있다”고 썼다.
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com