M2M-100, 영어 데이터 없이 100개 언어 번역
기존 영어 중심 번역 AI 보다 우수...BLEU 메트릭스 10점 높아
역번역으로 소스 적은 언어 데이터 보충
모델 병렬 처리로 대규모 모델 훈련, 총 154억개 매개변수 사용
세계 최초로 영어 데이터 없이 100개 언어를 번역할 수 있는 AI가 등장했다. 페이스북은 영어 데이터를 사용하지 않고 100개 언어를 번역하는 단일 대규모 다국어 기계 번역(MMT) 모델 M2M-100을 개발했다고 19일(현지시각) 공식 블로그에 발표했다.
연구진은 새로운 언어 식별 기술을 사용해 다양한 언어 소스에서 질높은 데이터를 마이닝했다. 브리지 마이닝과 ccAligned , ccMatrix , LASER을 이용해 100개 언어에 대한 75억개 문장을 수집해 데이터셋을 구축했다. M2M-100은 총 2200개 언어쌍을 학습했고 이는 기존 영어 중심 다국어 모델보다 10배 많은 양이다.
비슷한 계열 내 언어들의 정보를 공유하면서 리소소가 부족한 언어 번역과 이전에 모델이 접해본 적 없는 언어를 번역하는 제로샷 번역도 가능해졌다.
단일 모델이 다양한 언어와 스크립트 정보를 수집하기 위해 모델 용량을 확장하고 언어별 매개 변수도 추가했다. 언어별 약 30억개, 총 154억개 매개변수를 모델에 포함했고 모델 병렬 처리로 기존 이중 언어 모델보다 2배 큰 모델을 훈련할 수 있었다.
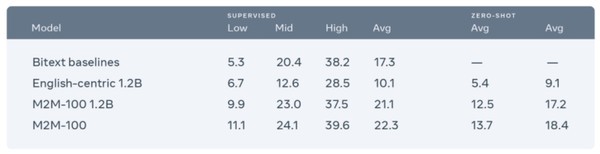
번역 능력도 기존 모델보다 우수한 것으로 검증됐다. 기계 번역 AI 수행 능력을 평가하는데 사용하는 지표인 BLEU 메트릭스를 적용한 결과 기존 영어 중심 모델보다 10점 높았고 이중 언어 모델과는 동일하게 나타났다.
데이터 마이닝을 위해 페이스북 연구진은 번역 모델 훈련을 위한 10억 규모 바이텍스트(bitext)문서 CCMatrix, 웹 상 대규모 언어 교차 자료 수집 툴인 CCAligned, 자연어 처리 모델의 제로 샷 전송을 수행하는 오픈 소스 툴킷 LASER 2.0을 사용했다.
데이터셋 구축 과정에서는 먼저 브리지 마이닝 전략(bridge mining strategy)을 사용해 지리·문화적 유사성에 따라 언어를 14개 계열로 나눴다. 통계적으로 번역 수요가 거의 없는 아이슬란드어-네팔어 또는 신 할라 어-자바어와 같은 언어쌍은 제외했다. 이후 다른 계열 언어를 연결하기 위해 각 그룹에서 1~3개 주요 언어를 골랐다. 가능한 모든 조합에 대한 훈련 데이터를 마이닝한 결과 75억개 문장 데이터를 얻었다.
소스가 적은 언어 데이터 보충을 위해서는 역번역 기술을 사용했다. 역번역은 단일언어모델 훈련으로 얻은 단일언어 데이터를 번역해 다른 언어에 대한 합성데이터를 만드는 기술이다. 중국어-프랑스어 번역 모델 훈련을 목표로 프랑스어를 중국어로 번역하는 모델을 훈련시키고 영어 데이터를 제외한 프랑스어 데이터만을 중국어 번역에 사용하는 식이다. 연구팀은 이 합성데이터를 마이닝 언어로 사용해 이전에 모델이 접한 적 없는 언어쌍 데이터를 만들 수 있었다.
단일 모델이 다양한 언어와 스크립트 정보를 수집하기 위해서는 모델 용량 확장이 필요했다. 모델 크기를 늘리기 위해 연구진은 트랜스포머 네트워크의 레이어 수와 각 레이어의 너비를 늘렸다. M2M-100 수행 능력을 떨어뜨리지 않으면서 크기를 키우기 위해 154억개 매개변수를 각기 다른 언어 그룹에 30억개씩 나눠 배치했다. 대규모 모델 훈련에는 파이토치(PyTorch) 툴인 페어스케일(Fairscale)로 모델을 병렬 처리했다.
페이스북 팀은 M2M-100 번역이 자연스러운지 판단하기 위해 원어민 평가를 진행했다. 영어를 제외한 20개 언어쌍 번역 결과물이 평가 대상으로 선정했다. 평가자들은 M2M-100이 기본적으로 충실하게 번역을 수행한다고 평가했다. 하지만 맥락상 의미가 중요한 속어 번역에 있어서는 단어 대 단어 번역 결과만 제시하는 한계를 보인다고 언급했다. 문장에서 콤마를 빼 본래 뜻을 바꾸는 것과 같이 문법에도 취약한 면이 있는 것으로 나타났다.
페이스북 데이터과학자 안젤라 판(Angela Fan)은 “아직 많은 언어에 대해 합리적인 번역을 하려면 개선이 필요하다. 코사어와 줄루어와 같은 아프리카어, 카탈로니아어, 브르타뉴어와 같은 유럽언어, 일로코와 세부아노와 같은 동남아시아어가 예시다. 이들 언어는 인터넷상 단일 언어 리소스도 드문 상황”이라고 전했다.
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com