인간이 알려주지 않아도 스스로 정의·규칙 파악하는 AI
언어, 시각 등 다양한 분야에 쓰이기 시작
학습 데이터 없이도 '자가발전'
"자기지도학습은 미래 먹거리이자,
Real AI로 가기 위한 필수 분야다"
-얀 르쿤 (2018 삼성AI포럼에서)
자기지도학습은 최소한의 데이터만으로 스스로 규칙을 찾아 분석하는 AI 기술이다. 사람이 별도로 지도하지 않아도, 기계가 스스로 대상을 인지하고 의미를 부여한다.
자기지도학습은 깊이성장 AI의 하나로, AI 스스로 학습 데이터에 없는 정의와 규칙을 찾아 분류, 의미를 부여한다.
먼저 대규모 데이터로 특징점을 학습한 후, 전이학습을 통해 목적에 부합하는 성능을 달성한다. 새로운 문제를 스스로 인지해 가설을 만들고 검증하는 등 주도적으로 문제를 해결하는 AI로 확장하는 게 목표이다.
즉, 최소한의 데이터만으로도 스스로 학습하여 발전하는 AI 기술.
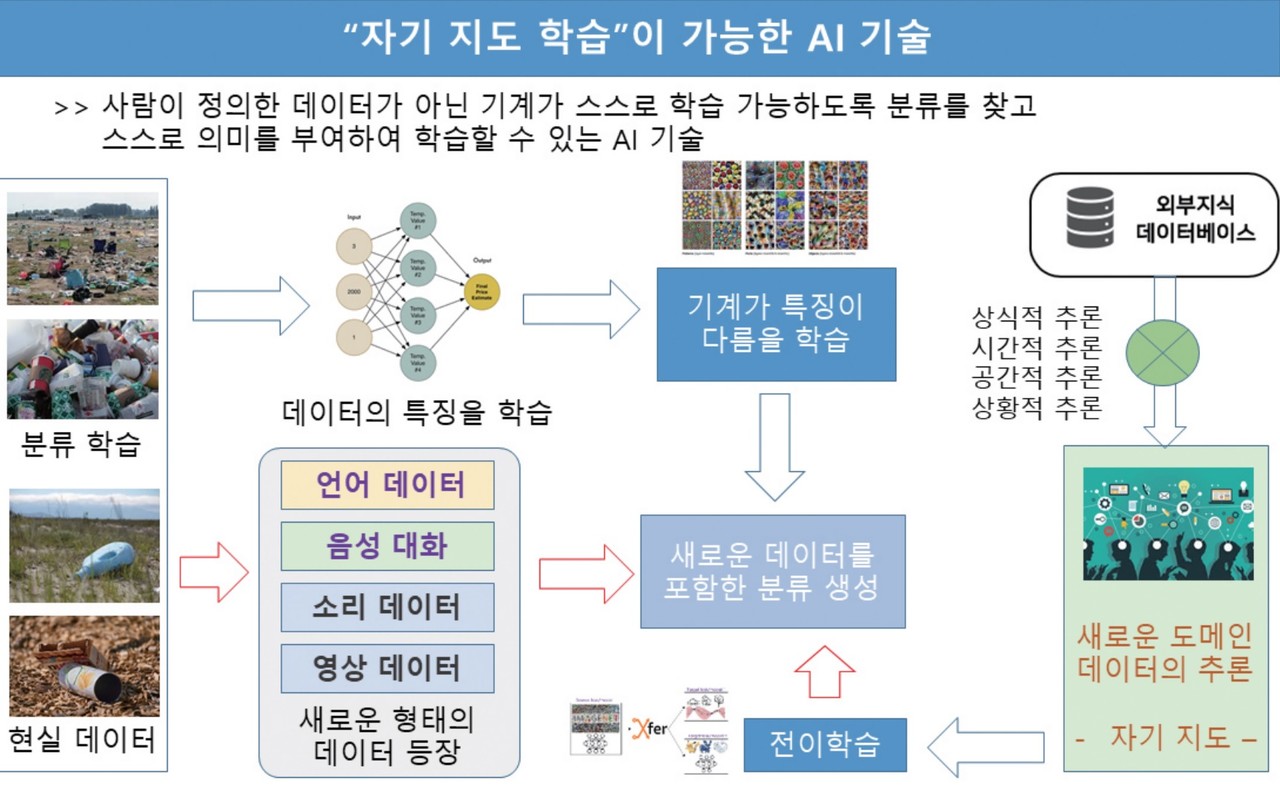
자기지도학습 단계는 ▲비지도 기반 특징점 학습 ▲시각적·상식적 추론 ▲도메인 확장 자기지도 학습 3단계로 나뉜다.
비지도 기반 특징점 학습(Unsupervised Feature Learning)은 대규모 데이터를 통해 특징적으로 서로 다른 내용을 학습하고 새로운 데이터를 분류하는 단계다. 이 단계에선 별도의 지도 없이도 데이터의 특이점 위주로 스스로 학습한다.
아직 연구 초기 단계이며, 주로 특정 도메인에서만 연구가 진행되고 있다. 기술 완성도는 60%(2020년 12월 기준).
시각적·상식적 추론(Reasoning from Commonsense)은 새로운 학습 대상에 대해 스스로 연결을 찾고 시각적·시간적·상황적 추론을 통해 지식 대상을 확장하는 단계다.
기술 완성도는 40%로, 특히 시각적 상식에 대한 연구는 아직 매우 초기 단계에 있어 더 많은 연구가 필요하다.
도메인 확장 자기지도 학습(Domain & Knowledge Transfer)은 이전 단계에서 확장한 지식 대상을 타 도메인으로 이동하거나, 지식 대상 자체를 변경해 학습·적용하는 단계다. 기술 완성도는 50%로, 현재는 일부분만 연구가 진행되고 있다.
◆기술 동향
자기지도학습 기술연구는 ▲새로운 학습데이터 정제 ▲자연어 학습 ▲이미지 복원 3개 분야에서 주로 이뤄지고 있다.
새로운 학습데이터 정제는 학습 데이터가 갖는 특징 정보를 군집화하고 이들의 부분 특징을 조합해 새로운 인식 대상으로 지정하는 기술이다.
기존 AI 학습에 흔히 사용되는 지도학습에서는 대규모 데이터 정제가 필요한데, 이는 많은 노력과 비용을 수반한다. 이때 자기지도학습을 학습데이터 정제에 활용하면 적은 노력·비용만으로도 많은 데이터를 정제하고 활용할 수 있다.
자연어 학습에서는 우선 수많은 무작위의 언어 데이터에서 단어나 문장 간 상관관계를 학습한다. 그 후, 오타가 있는 질문을 사람처럼 감내, 인식하고 형태를 가려낸다.
자연어 인식은 보통 어순이 바뀌거나 구조상 불완전한 문장이 있는 경우 제대로 이뤄지기 어려운데, 자기지도학습을 이용하면 이러한 비문법적 부분까지도 스스로 학습할 수 있다.
주로 목적에 따라 학습하지 않고, 언어 데이터를 대규모로 모아 스스로 특징을 먼저 학습한 후 목적에 맞게 재학습한다. 이는 기존 구문 분석 방법 대신 End-To-End 학습법을 사용하는 것이다.
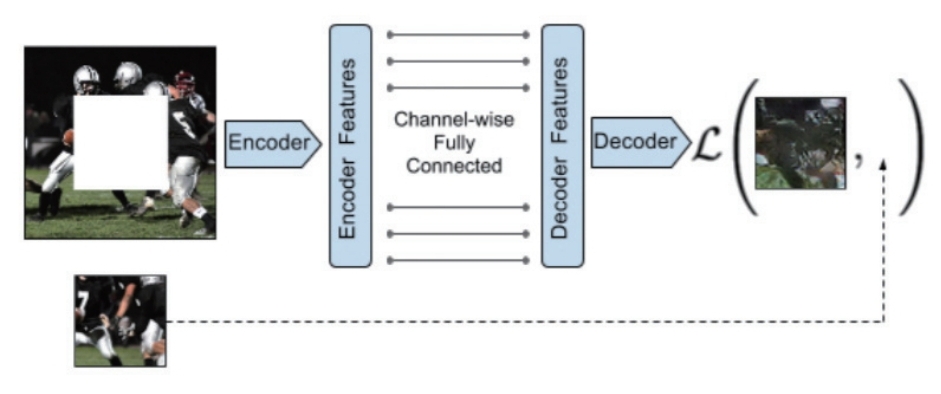
이미지 복원에서는 이미지 조각들이 가지는 연관성을 스스로 찾아 사람이 조각 간 상관관계를 지정하지 않아도 주변에 어울리는 것을 학습한다.
한 이미지를 여러 조각으로 나눠 섞었을 때, 각 조각 주위의 조각을 스스로 탐색할 수 있는데, 이는 손상된 사진 복원하거나 주변부의 특징과 어울리는 이미지·영상을 만드는 데 유용하다.
자기지도학습은 지도학습과 비슷한 경지에 이르렀다. 토론토대 교수 Geoffrey Hinton가 발표한 연구에서는 지도학습 수준에 근접한 성과를 냈다(‘SimCLR: Simple Framework for Contrastive Learning of Visual Representations’, 2020년 2월 발표)
자기지도학습 연구는 새로운 문제를 창의적으로 해결하는 자기주도적 AI 기술 개발을 목표로 하고 있다. 이를 위해 의도적 편향을 통한 학습데이터 생성, 학습데이터를 도메인 전이해 목적에 부합하는 학습데이터 생성, 가설・검증 가능한 베이즈 머신 개발과 같은 전략이 요구된다.
◆시장 동향
자기지도학습 연구는 2010년대 초반에 본격적으로 시작돼, 현재 연구 개발 단계에 있다. 상용화까진 시간이 더 소요될 예정이지만, 국내외 많은 IT 기업이 시장을 선점하고자 활발히 연구하고 있다.
자기지도학습은 주로 의료 산업, 자율주행 분야에 쓰인다.
로봇 수술 시 수술 대상의 깊이 정보를 알아내 더 정교한 수술을 가능케 하고, 신체 구조상 가려진 부분에 대한 추정을 할 수 있어 수술 능력 배양에 활용할 수 있다.
자율주행차에서는 장애물 및 거리 인지 분야에서 자기지도 학습 기술이 크게 활용되어, 자율주행차 산업 전체의 호황을 이끌고 있다.
이처럼 알려주지 않은 특징을 스스로 학습하는 과정을 이용해 비행 드론, 챗봇 등에서도 적용되고 있다.
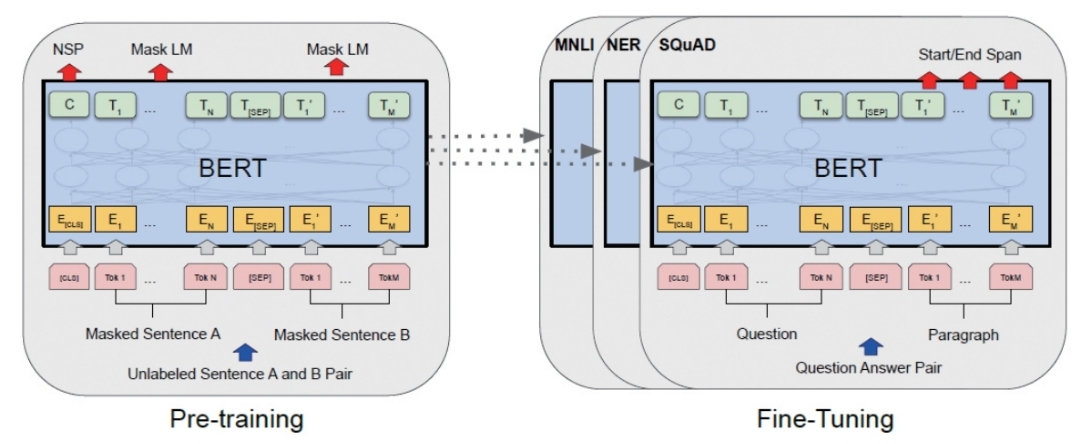
언어 모델에서는 대표적으로 구글이 2018년부터 연구 중인 'BERT'가 대표적이다.
BERT(Bidirectional Encoder Representations from Transformers)는 정답이 없는 데이터를 양방향으로 사전학습해 자연어를 처리한다.
BERT는 기존 RNN(순환 신경망) 중심의 기술이 지닌 거대화 어려움을 해소하면서 자연어 처리 분야 판도를 뒤집었다. 이는 거대화가 어려운 네트워크 구조에서 벗어나 트랜스포머(Transformer) 기반 모델을 사용해 거대한 모델을 사전학습・재학습할 수 있게 된 것.
BERT는 86.7의 성능을 확보, 타 모델에 비해 우수한 성능을 보였다(GLUE 데이터 평가). 네이버, 카카오, 아마존 등 국내외 다수의 IT 기업에서 BERT 방식을 응용해 챗봇을 연구하고 있다. 특히, 코로나19로 인해 비대면 소통이 증가하며 챗봇 수요도 급증하고 있다.
한편 국내에서는 ETRI의 '엑소브레인' 프로젝트로 한국어 모델 KorBERT가 구축 중에 있다. KorBERT는 자연어 질의응답기술을 목표로 하는 언어모델이다.
ETRI는 자연어의 문법과 의미를 분석해 기계가 이해하는 언어적 지식을 축적한 후, 문장으로 기술된 사용자 질문에 정답을 제공하는 연구를 진행하고 있다. 2013년부터 연구되어왔으며, KorBert기계 독해와 주제 분류에서 93% 이상의 정확도를 보이며, 한국어 성능이 구글 대비 4.5% 우수하다는 점이 주목된다.
영상 분야에서도 수많은 기업들이 연구 중이다.
EU의 옥스퍼드대에서 진행 중인 Seebibyte가 대표적이다. Seebibyte는 빅데이터의 영상 검색 프로젝트로, 자기지도학습 기법으로 얼굴의 구조, 표정 등을 함축하는 임베딩을 생성한다. 임베딩(Embedding)이란, 분리된 정보를 연속적으로 표현할 수 있게끔 하는 딥러닝(Deep Learning)의 기법.
국내에서도 영상 기술에 자기지도학습을 적용하는 연구가 진행 중이다. '딥뷰' 프로젝트에서 영상에서 보이지 않는 영역을 AI를 활용해 재구성・복원하는 기술을 개발했다. 텍스처 정보와 윤곽선만을도 얼굴 정보를 생성할 수 있고, 자동차 등의 대상을 쉽게 확장할 수 있다.
딥뷰는 앞서 언급된 엑소브레인을 진행 중인 ETRI에서 연구되고 있다.
◆발전 전망
자기지도학습의 단기적 전망의 핵심은 세부 도메인에 있다. 세부 도메인을 중심으로 특이점 학습 대상을 확대해 도메인의 한계를 극복하고, 세부 도메인별로 부족한 학습 데이터를 생성해 데이터 부족을 극복할 수 있다.
중기적(2023~2026년)으로는 비지도에 기반해 학습하고, 학습에서 오류를 스스로 피드백하는 걸 목표로 한다. 또한, 인간의 상식에 기반해 새로운 지식의 추론을 확대하고자 한다.
장기적(2027~2030년)으로는 완전한 비지도를 적용하고, 학습 데이터를 스스로 검증하며, 기존 상식들에서 새로운 상식을 창출하는 게 목표. 특히, '크로스 도메인'을 통해 스스로 성장할 수 있도록 할 전망이다.
인간의 의사소통, 사회문화적 규범에 기반한 상식은 어떻게 학습되는 것일까. 한정된 정보만으로 어떻게 새로운 지식을 추론하고, 개념을 이해하는 것일까.
AI가 인간의 배움을 배우는 것, 자기지도학습의 궁극적 방향이다.
"인공지능과 자연지능 연계 집중할 때" AI 기술청사진 연구 총괄 IITP 박상욱 팀장
[특별기획] 인공지능 기술 청사진 2030 연재순서 표
AI타임스 박성은ㆍ최명현 기자 sage@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com