업스테이지·네이버·KAIST·뉴욕대 주축으로 국내 AI 연구기관들 집합
하이퍼클로바와 같은 초거대 AI 모델 평가에 KLUE 필수
재배포·재가공 자유...기업 소속 연구자들도 영리적 활용 가능

5월 한 달, 국내에서 자연어 분야 인공지능(AI) 연구 성과가 대거 등장했다.
네이버는 지난 5월 한국어판 GPT-3라고 불리는 대규모 언어모델 ‘하이퍼클로바’를 발표했다. 같은 달 기업 대상 AI 컨설팅 스타트업 업스테이지에서는 한국어에 특화된 자연어이해(NLU) 평가 데이터셋 ‘KLUE(Korean Language Understanding Evaluation)’를 공개했다.
하이퍼클로바가 국내 대표적인 자연어생성(NLG) 모델이라면 KLUE는 해당 모델 성능을 평가할 수 있는 사실상 유일한 데이터셋이다. 언어를 사용하기 위해서는 먼저 언어 이해가 필요한 만큼 KLUE가 한국어 AI 연구에 가져올 파급력은 크다.
하이퍼클로바 이전에는 GPT-3, KLUE 이전에는 GLUE가 있었다. 오픈AI의 GPT-3가 있음에도 네이버가 하이퍼클로바를 개발한 이유는 한국어 적용이 어려웠기 때문이다. GPT-3가 학습한 언어 중 영어가 93%를 차지한다면, 하이퍼클로바에서는 학습 언어 97%가 한국어다.
KLUE가 등장한 계기도 유사하다. KLUE 이전에는 한국어 하나만을 대상으로 하는 NLU 평가 데이터셋이 사실상 부재하는 상황이었다. 대표적인 벤치마크로 GLUE가 먼저 개발됐지만 영어에만 활용 가능하다.
GLUE를 넘어서는 KLUE의 특징으로 접근성을 꼽을 수 있다. GLUE와 달리 KLUE는 CCL라이선스(크리에이티브 커먼즈 라이선스: 특정 조건에 따라 저작물 배포를 허용하는 저작권 라이선스)를 허용한다. CC-BY-SA 라이선스로 지정돼 있어 재배포, 재가공이 가능하다.
연구자들은 KLUE를 활용한 서로의 데이터셋을 공유해 연구에 참고할 수 있다. 유사한 데이터셋이 여러 개 만들어지는 낭비를 줄여 효율적으로 연구계가 성장하도록 돕는다.
영리적 활용도 허용하는 만큼 학계 이외 특정 기업 소속 연구원들도 자유롭게 사용 가능하다. 학계 이외 기업 참여도가 높은 AI 연구계 특성을 반영했다고 볼 수 있다.
KLUE를 사용할 수 있는 대상을 넓히는 동시에 제작단계에서도 여러 기관을 포용했다. 대규모 프로젝트를 7개월 만에 해낼 수 있었던 이유다. KLUE 프로젝트를 위해 국내 대표적인 AI 연구기관들과 더불어 해외 대학까지 한데 모였다.
업스테이지와 함께 네이버AI랩, KAIST, 뉴욕대는 공동주최기관으로서 프로젝트를 이끌었다. 연구기관으로 참여한 기업은 카카오엔터프라이즈, 스캐터랩, 뤼이드 3곳이다. 학계에서는 서울대, 연세대, 경희대, 서강대, 한밭대 5개교가 연구에 동참했다.
특정 기업이나 학교 소속과 관계없이 개인 단위로 참여한 연구자들도 상당수다. 국내 AI 연구를 리드하는 베테랑부터 논문을 처음 써보는 초보 연구자가 함께 프로젝트를 진행한 이례적인 사례이기도 하다. 이렇게 모여 KLUE 논문에 이름을 올린 연구자 수는 총 31명이다. 논문 분량은 무려 76페이지에 이른다.
기존에 각 기업과 학교서 AI 연구를 주도하는 대표적인 연구자들 대신 비교적 경험이 적은 연구자들이 제1저자에 이름을 올린 점도 주목할 만하다.
KLUE 논문의 공동 제1저자는 업스테이지 박성준, 문지형 엔지니어, 네이버 김성동 연구원, 서울대 조원익 박사과정 연구원이다. 하정우 네이버AI랩 연구소장, 오혜연 KAIST 교수, 조경현 뉴욕대 교수는 프로젝트 어드바이저 역할을 했다.
챗봇 이루다 사건으로 전국민이 주목하게 된 AI 윤리에도 주의를 기울였다. 차별·혐오 내용과 개인정보는 KLUE 주석 작업 과정에서 인간 담당자가 직접 처리했다.
◆한국어 특화 NLU 벤치마크 등장...8개 과제 평가 가능
KLUE는 한마디로 한국어 자연어이해(NLU) 모델 평가를 위한 데이터셋이다. NLU는 자연어처리(NLP)분야 핵심과제 2가지 중 하나다. 인간이 사용하는 자연어 문장을 기계가 이해할 수 있는 기술이다.
나머지 주요과제 하나는 자연어생성(NLG)으로, 기계가 문장을 생성하는 기술을 의미한다. 즉, NLU 없이는 NLG도 불가능하다.
오픈AI의 GPT-3나 네이버의 하이퍼클로바와 같이 AI계 최첨단 성과로 각광받는 초거대 AI는 모두 NLG다. KLUE 없이는 GPT-3, 하이퍼클로바 발전도 어렵다는 뜻이다.
KLUE는 한국어 NLU 능력을 평가할 수 있는 8가지(▲뉴스 헤드라인 분류 ▲문장 유사도 비교 ▲자연어 추론 ▲개체명 인식 ▲관계 추출 ▲형태소 및 의존 구문 분석 ▲기계 독해 이해 ▲대화 상태 추적) 문제 데이터로 구성됐다.
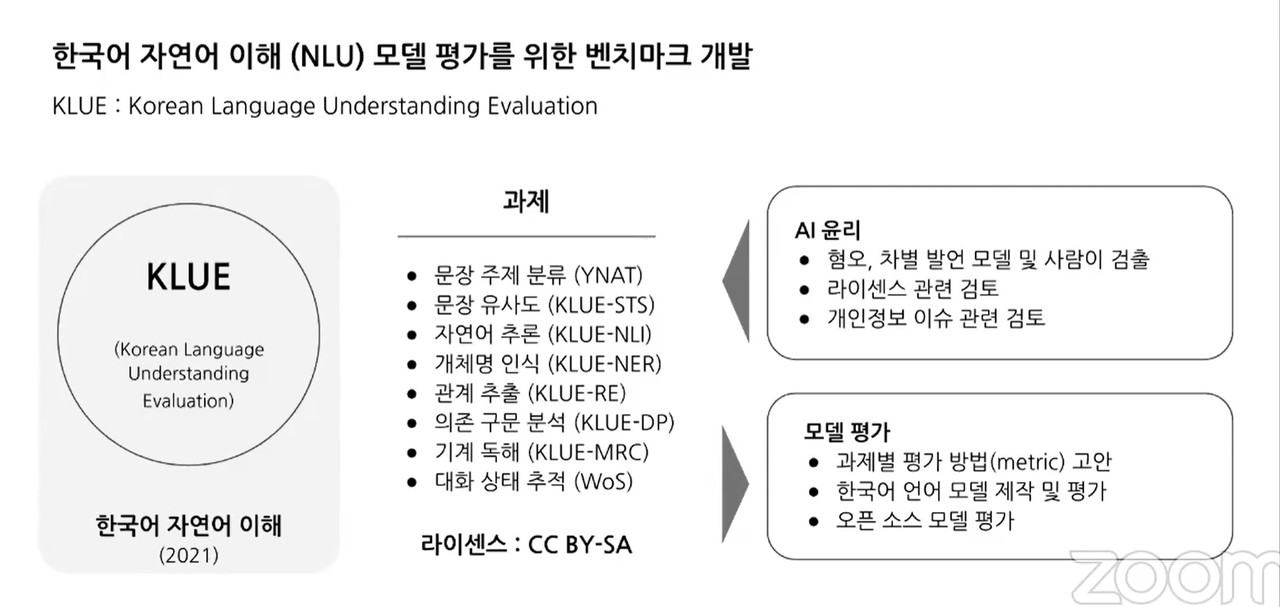
인간 언어가 다양한 요소를 지니는 만큼 각기 다른 평가 기준이 필요하다. 박성준 업스테이지 연구원은 최근 KLUE 성과를 소개하는 페이퍼 데이(KLUE Paper day)에서 “AI가 사람 언어를 얼마나 잘 이해하는지 평가하는 일은 단일 과제로는 어렵다. 사람도 마찬가지다. 다양한 과제를 통한 평가가 필요한 이유”라고 말했다.
기존 대표적인 NLU 벤치마크로 9개 분야 평가가 가능한 GLUE는 영어에만 적용 가능하다는 한계가 있었다. 이후 중국어(CLUE), 프랑스어(FLUE), 인도어(IndicGLUE), 인도네시아어(IndoNLU), 아랍어(ALUE) NLU 벤티마크가 등장했지만 한국어 버전은 없었다.
XGLUE, XTREME와 같은 다국어 벤치마크도 등장했지만 단일어보다 성능이 떨어졌다. 이와 같은 상황에서 KLUE가 등장하게 된 것이다.
KLUE라는 공정한 평가 체계를 수립함으로써 한국어 자연어 처리 연구는 가속화될 전망이다. 박성준 연구원은 “그간 벤치마크 부재로 인해 연구계에서는 유사한 한국어 언어모델이 다수 만들어졌다. 사전학습 모델들이 계속 재생산되는 낭비가 있었다”며 KLUE를 개발한 배경을 설명했다.
그는 “특정 과제를 어떤 모델이 가장 잘 수행하는지, 그 이유에 대해서도 파악할 수 있다. 결과적으로 한국어 자연어 이해 모델을 더 깊이 이해하고 개발할 수 있을 것”이라고 강조했다.
◆재배포·재가공·영리적 사용 가능...NLP 연구 가속화
최초의 한국어 NLU 벤치마크라는 점 다음으로 접근성을 대폭 확대한 것을 KLUE 특장점으로 꼽을 수 있다. KLUE는 CC-BY-SA 라이선스를 받아 재배포, 재가공, 영리적 사용까지 가능하다.
박성준 연구원은 “기존 한국어 데이터셋을 분석해보니 재배포, 재가공, 영리적 사용이 모두 가능한 것이 없었다. 벤치마크 제작 과정에서 라이선스와 접근성에 대해 심혈을 기울였다”고 전했다.

KLUE는 연구자들 간 데이터셋 공유를 허용해 자연어 연구계가 빠르게 성장하도록 돕는다. 기존 한국어 데이터셋 대부분에서는 연구자들에게 동의서를 받고 재배포를 금지했다.
재가공이 가능한 만큼 보다 고차원의 데이터셋을 제작하는 원동력이 되기도 한다. 박 연구원은 “처음 등장한 데이터셋에서는 생각지 못한 한계점이나 성과가 발생할 수 있다. KLUE를 기반 데이터셋으로 활용해 보다 어려운 데이터셋을 제작하면 생각보다 빨리 휴먼 퍼포먼스에 근접할 수 있을 것”이라고 말했다. LG CNS가 만든 AI학습용 표준데이터인 코쿼드(KorQuAD)는 재가공을 금지하는 상황이다.
기업 참여가 많은 AI 연구계 특성과 상용화 중요성을 고려해 영리적 활용도 허용한다. 기업 소속 연구자들도 KLUE를 사용할 수 있다는 의미다.
박성준 연구원은 “대학에서 개발한 데이터셋에 비영리적 활용만 가능하다는 조건이 걸려 기업 연구자들이 사용하지 못하는 경우가 많다. 자연어 연구에 뛰어든 다수 영리 기관 소속 연구자 참여를 유도하려 한다”고 전했다.
KLUE 라이선스에 대해 문지형 업스테이지 연구원은 “데이터셋 공개를 위해 CC BY-SA로 배포할 수 있는 주석 대상 말뭉치를 사용했다. 2차적 저작물인 KLUE는 CC BY-SA 4.0 라이센스로 배포했다”고 설명했다.
재배포는 허깅페이스(Huggingface)를 통해 가능하다. 재배포시 출처를 표시해야 하며 재가공으로 인한 변경이 있는 경우 공지해야 한다. 재가공된 데이터세트 또한 CC BY-SA 라이선스를 따라야 한다.
◆뉴스 기사부터 위키피디아까지 데이터 다양...구글·네이버·카카오가 컴퓨팅 담당
자유롭게 사용 가능한 양질의 데이터셋을 구축하기 위해 활용 데이터 선정 단계에서부터 저작권과 질, 양을 고려했다.
연구팀은 사용 가능한 데이터를 저작권 보호 대상이 아닌 저작물, 재가공·재배포·영리적 활용이 가능한 라이센스(CC BY, CC BY-SA, KOGL Type 1)를 가진 저작물로 나눴다. 한국경제신문과 아크로팬과는 별도 계약을 체결해 뉴스 기사 데이터를 제공받았다.
최종적으로 저작권 보호 대상이 아닌 데이터 중 연합 뉴스 헤드라인을 주석대상 코퍼스(Corpus, 말뭉치)로 선택했다. 이외 재가공·재배포·영리적 활용이 가능한 라이센스 보유 데이터로는 위키피디아, 위키뉴스, 위키트리, 정책브리핑, ParaKQC, 에어비앤비(Airbnb) 리뷰, NSMC를 사용했다.
사전학습 코퍼스로는 국립국어원 모두의 말뭉치와 같이 누구나 접근가능한 것만 사용했다. 사전학습 코퍼스 전체 규모는 62.65기가바이트, 473만개 문장, 65억토큰에 이른다.
대규모 프로젝트에 필수적인 컴퓨팅 인프라는 구글, 네이버, 카카오가 제공했다. 구글은 KLUE 프로젝트에 텐서플로우 리서치 클라우드(Tensorflow Research Cloud) TPU를 지원했다.
네이버 NSML GPU는 모델 개발과 파인튜닝, 각종 실험 분석에 활용됐다. 카카오엔터프라이즈는 브레인클라우드(BrainCloud) GPU 클라우드를 제공했다.
◆차별·혐오 내용과 개인정보 처리, 인간 검수자가 담당
자연어 모델에서 차별·혐오 발언 가능성과 개인정보 유출 우려는 대표적인 문제라고 할 수 있다. KLUE 벤치마크에서는 데이터 내 차별·혐오 내용과 개인정보 처리를 사람이 직접 담당했다.
1차적으로 한국어 혐오와 성차별 태깅 데이터로 학습한 유해성 분류기(Toxicity Classifier)를 사용해 초벌 작업을 진행했다. 이후 2차적으로 주석 과정에서 인간 담당자가 혐오·차별 내용을 직접 검수했다.
사전학습 데이터에 대해서는 모두의 말뭉치와 같이 누구나 접근가능한 코퍼스만 포함되는 만큼 별도 처리를 하지 않았다.

이에 대해 문지형 연구원은 “방대한 양의 사전학습 코퍼스 전부를 사람이 직접 전수 검사하는 것은 현재 기술로는 불가능에 가깝다. 어떤 특정 데이터셋이 유해 요소를 지니는지 판별하는 것도 어렵다”고 설명했다. 해당 부분은 향후 추가 연구에서 개선할 예정이다.
식별 가능한 개인정보는 먼저 규칙 기반 모델을 통해 제거했다. 이후 차별·혐오 내용과 마찬가지로 주석 과정에서 인간 작업자가 검수를 진행했다.
사전학습 코퍼스 내 개인정보는 규칙 기반 모델로 가명 처리했다. 비식별 처리한 데이터는 전화번호, 여권번호, 카드번호, 계좌번호 등이다. 사람 이름은 개체명 인식 과제에서 필요한 만큼 가명처리하지 않았다.
AI타임스 박성은 기자 sage@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com