
인공지능 알고리즘 기술의 활용도가 높아지면서, 알고리즘에 기초한 의사결정이 공정한 것인지에 대한 문제제기가 종종 나타나고 있다. 알고리즘 공정성과 관련된 문제의식은 매우 다양한 맥락에서 나타날 수 있다. 대출이나 신용평가와 같은 금융 의사결정 과정에서도 논란이 발생할 수 있고, 배달 서비스 이용과정에서 라이더 배정이나 경로안내와 관련한 의사결정의 맥락에서도 논란이 발생할 수 있다. 실제로 알고리즘을 활용한 수많은 의사결정의 과정에서 공정성 개념을 둘러싼 논란이 발생할 가능성이 있다.
알고리즘 공정성 개념을 둘러싼 논란의 가능성을 명확하게 보여주는 중요한 사례 하나는 사법제도 특히 형사사법의 영역에서 찾을 수 있다. 미국에서는 이미 몇 년 전 법원을 통한 가석방 의사결정을 둘러싸고 논란이 발생한 바 있다. 이 논란은 재범확률을 계산하는 알고리즘이 인종별로 결과값에 매우 큰 차이를 보인다는 주장이 ‘프로 퍼블리카’라는 탐사매체를 통해 상세하게 보도되면서 불거졌다.
주장의 핵심은 다음의 표를 통해 볼 수 있다. ‘콤파스(COMPAS)’라는 예측 알고리즘을 이용하여 계산해 보니, 분석대상인 형사피고인 중에서 재범 가능성 높은 고위험군으로 예측되었지만 실제로 재범을 하지 않은 사람의 비율이 백인에 비해 흑인이 두 배 가까이 높은 것으로 나타났다(23.5% vs 44.9%). 반면에, 저위험군으로 예측되었지만 실제로 재범을 한 사람의 비율은 흑인에 비해 백인 훨씬 높은 것으로 나타났다(47.7% vs 28.0%).
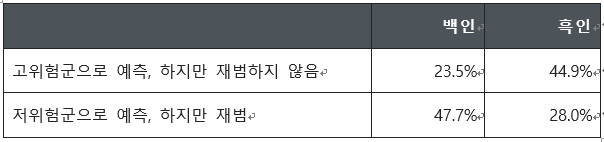
이러한 분석결과는 즉각적인 반향을 불러 일으켰다. 흑인은 실제로 재범을 할 가능성이 높지 않더라도 억울하게 고위험군으로 분류되는 경우가 적지 않고, 반면에 백인은 재범의 가능성이 높더라도 저위험군으로 분류되는 경우가 적지 않다는 결과를 보여주는 것이었기 때문이다. 알고리즘이 인종차별을 부추기는 것으로 비쳐지면서, 알고리즘을 활용하는 것 자체가 적절한 것인지에 관한 문제의식이 제기되었다.
이런 알고리즘을 어떻게 받아들여야 하는가? 이에 답을 하기 위해서는 알고리즘이 어떤 계산을 한 것인지 살펴볼 필요가 있다. 콤파스는 형사피고인의 재범가능성에 영향을 미칠 수 있는 여러 요소들을 고려하여, 개인별로 1에서 10 사이의 지표를 통해 계산결과를 보여준 것이다. 고려된 여러 요소 중에 인종은 포함되지 않았다. 제3의 연구자들이 계산해 보니, 이 지표는 실제로 재범가능성에 대한 상당히 정확한 예측을 제공하는 것으로 파악되었다. 그래프를 통해 볼 수 있는 것과 같이, 위험도 지표가 가장 낮은 그룹은 20% 수준의 재범확률을 보인 한편, 위험도 지표가 가장 높은 그룹은 80% 수준의 재범확률을 보인 것으로 나타났다.
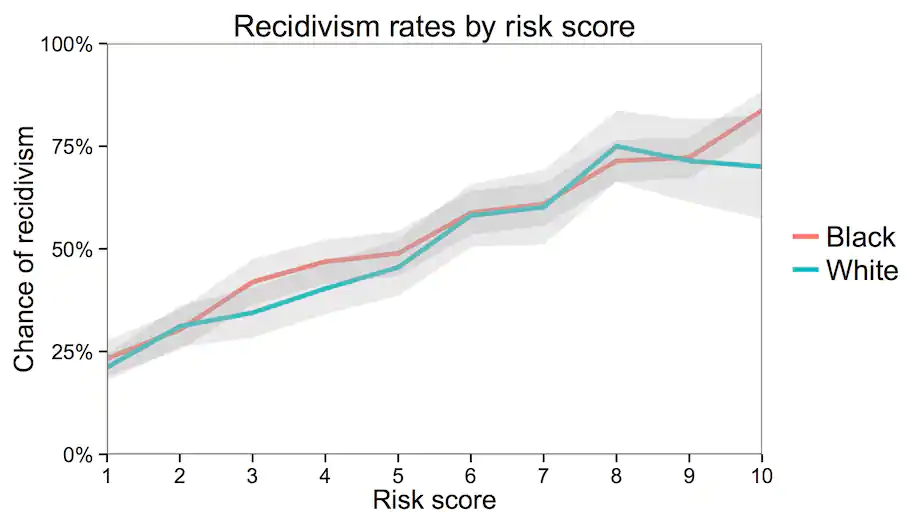
공정성 논란과 관련하여 이 그래프가 보여주는 중요한 시사점은 인종별로 재범확률에 큰 차이가 나타나지 않는다는 것이다. 예를 들어, 위험도 지표가 7로 평가된 사람들은 백인이건 흑인이건 모두 대략 60%의 재범확률을 보인다. 따라서 이 알고리즘은 재범확률을 고려하는 방식으로서 공정한 것이라는 평가가 가능하다. 재범가능성을 예측함에 있어 인종별 차이가 두드러지게 나타나지 않기 때문이다.
그렇다면 무엇이 문제인가? 프로 퍼블리카의 보도가 지적한 문제의식도 정당한 것이고, 그와 동시에 위의 그래프를 통한 설명도 정당한 것이다. 서로 차이가 나타나는 것은 두 설명이 애초에 서로 다른 공정성 개념을 전제한 것에 기인한다.
프로 퍼블리카가 분석한 결과는 인종별로 오류율에 커다란 차이가 있다는 것을 보여주는 것이다. 여기서의 오류율(equalized odds)은 통계적으로 재현율(true positive rate) 및 특이도(true negative rate)라고 부르는 개념을 측정한 뒤 평가한 것이다. 한편 위의 그래프를 통한 분석이 보여주는 것은 콤파스 알고리즘이 예측동등성(equal calibration) 기준을 만족한다는 것을 보여주는 것이다. 이는 통계적으로는 정밀도(positive predictive value)와 음성예측도(negative predictive value)를 계산하여 평가한다.
결국 이 사례가 보여주는 것은, 구체적으로 어떤 공정성 기준을 적용하여 인공지능 알고리즘을 평가하는지에 따라 매우 다른 결론이 도출될 수 있다는 것이다. ‘알고리즘은 공정해야 한다’고 외치는 것은 쉽다. 어려운 것은, 알고리즘이 활용되는 여러 다양한 맥락에서 각각 어떤 공정성 기준을 적용해야 할 것인지의 문제다. 앞으로의 연구와 논의는 이를 구체화하는 방향으로 진행되어야 한다.
* 이 글은 “한은소식” 2021년 8월호에 실린 것을 일부 수정한 것입니다.
고학수 서울대 교수, 한국인공지능법학회 회장 hsk@snu.ac.kr
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com