배경훈 원장, 'LG AI Talk Concert – The Best of 2021'서 발표
"모델 크기는 오픈 AI 넘었고 현재 3000억개 파라미터 학습 중"
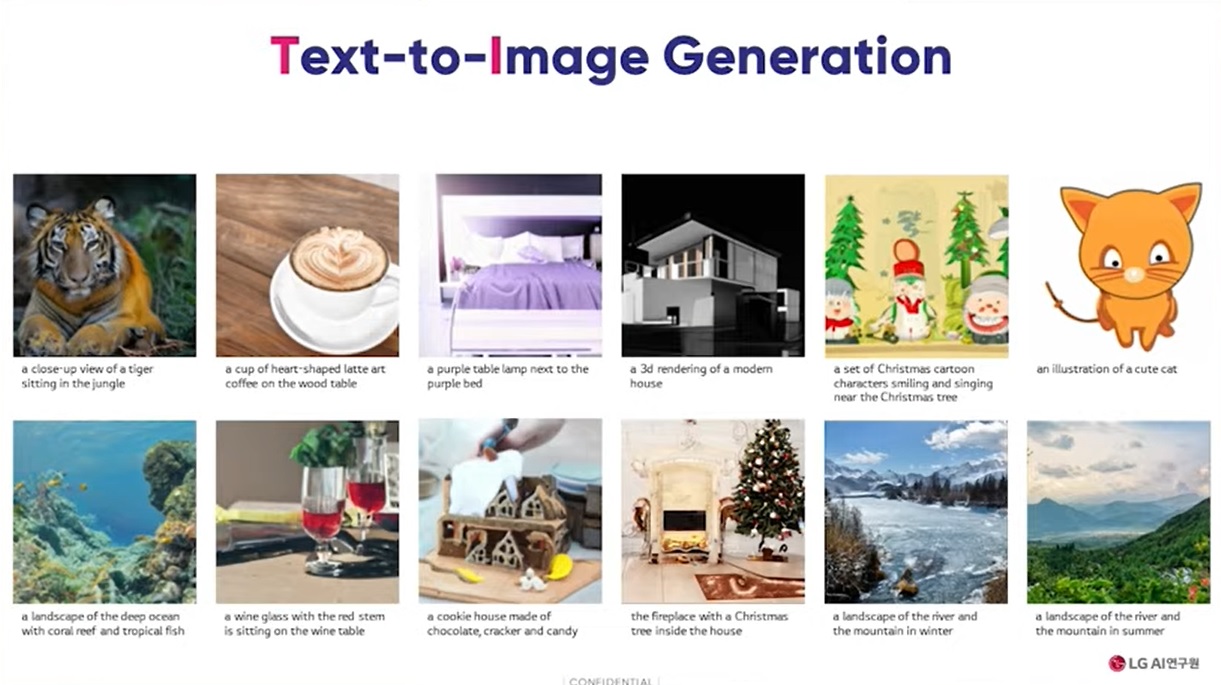
오픈AI DALL·E도 하지 못한 언어-이미지 양방향 생성 성공

LG가 개발한 초거대 인공지능(AI) '엑사원(EXAONE, Expert AI for everyone)'이 공식적으로 모습을 드러냈다.
LG AI 연구원은 14일 'LG AI Talk Concert – The Best of 2021'을 열고 자사 초거대 AI 연구 성과를 공개했다.
초거대 AI 성능과 보통 비례하는 모델 크기를 먼저 살펴보면 대표적인 초거대 AI인 오픈AI GPT-3를 넘는 수준이다. 배경훈 LG AI 연구원장은 이날 행사에서 "엑사원은 1750억개 파라미터 학습을 끝내고 현재 3000억개 파라미터 학습을 진행 중"이라고 밝혔다.
여타 초거대 AI와 차별화되는 점은 데이터에서 나온다. 엑사원은 네이버와 카카오의 초거대 AI와 달리 초기 개발 시점부터 한국어와 영어 데이터를 함께 학습했다. 한국어 특화 모델 개발부터 시작한 여타 국내 기업들과는 다른 전략이다. 여러 언어를 학습했지만 주로 영어에서 좋은 성능을 보이는 GPT-3와 같은 해외 기업의 초거대 AI와도 차별화된다.
배경훈 원장은 "LG가 보유한 전문데이터 등을 사용해 한국어와 영어 두 언어 특징을 동시에 학습했다"고 강조했다.
가장 주목할만한 점은 언어와 이미지를 함께 사용하는 멀티모달 형태의 초거대 AI라는 점이다. 엑사원 등장 전까지 멀티모달 초거대 AI 모델은 오픈 AI의 DALL·E가 유일했다.
특히 엑사원은 DALL·E가 하지 못하는 일까지 수행할 수 있다. DALL·E는 텍스트를 입력하면 그에 따른 이미지를 만들어준다. 엑사원의 경우 텍스트에 따른 이미지를 만드는 것은 물론, 이미지에 대해 텍스트로 설명하는 일까지 가능하다.
초거대 AI 개발에 필수적인 컴퓨팅 인프라도 직접 구축했다. 배 원장은 "우리는 엑사원 학습을 위해 초당 9경6000조번 연산이 가능한 슈퍼컴퓨터급 인프라를 구축했고 내년에 두 배로 확대할 예정"이라고 말했다.
언어에서 이미지, 이미지에서 언어 만드는 초거대 AI...어떻게 가능했나
엑사원에서 텍스트에서 이미지, 이미지에서 텍스트 생성이 모두 가능한 것은 양방향적 생성(Bi-directional Generation) 알고리즘 덕분이다.
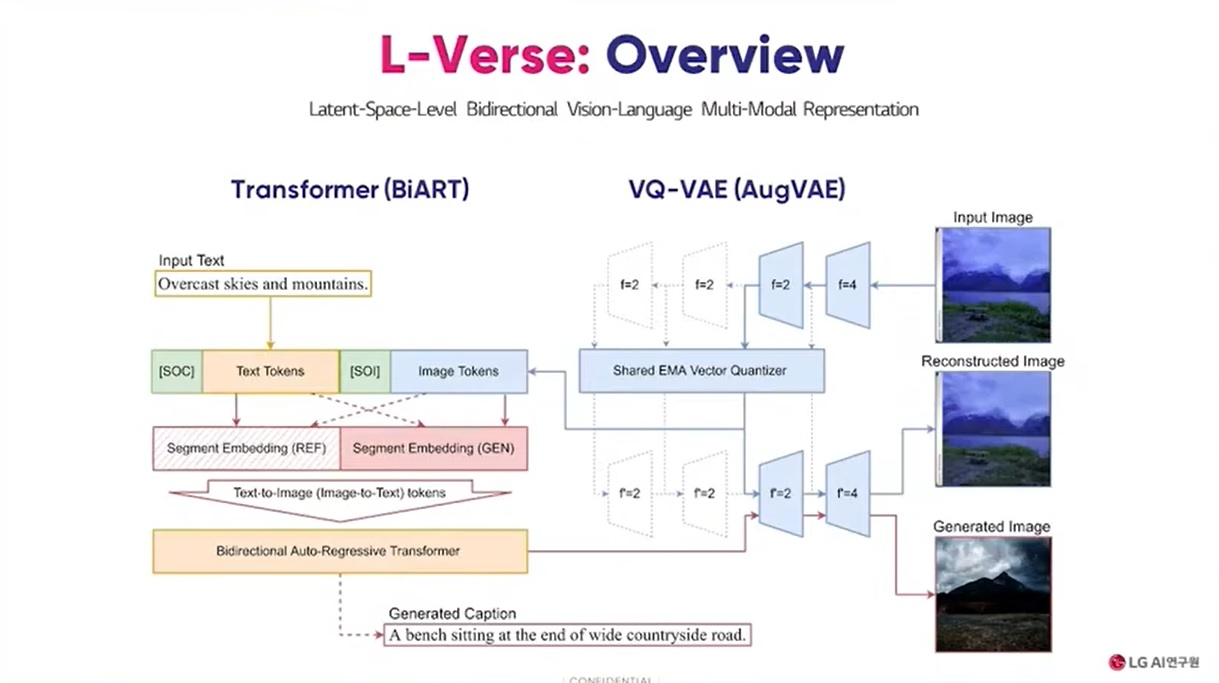
LG AI 연구원은 양방향적 이미지 텍스트 생성 알고리즘인 '엘버스(L-Verse)'를 자체 개발해 엑사원에 사용했다.
김태훈 LG AI 연구원 비전랩 연구원은 "잠재공간(Latent-Verse)에서의 비전과 언어 간 상관관계를 찾고자 만든 모델이다. 이미지에서 텍스트, 텍스트에서 이미지로의 자유로운 전환을 위해서는 이미지와 텍스트 간 연결관계를 찾아야 한다"며 엘버스를 개발한 배경을 설명했다.
이어 "비전과 언어 간 양방향적 멀티모달 표현(representation)을 학습한 엘버스는 추가적인 파인튜닝 없이도 이미지에 대해 자세한, 때로는 사람이 만든 것보다 더 상세한 (텍스트) 캡션을 생성 가능하다"고 강조했다.

엘버스를 개발한 노하우에 대해서는 "DALL·E에서 단방향 학습·생성만 가능했던 이유는 GPT로 대표되는 자동 회귀 트랜스포머(Auto-Regressive Transformer)가 입력을 한 방향으로만 읽기 때문이다. 텍스트 뒤에 이미지가 나오는 데이터로 학습된 트랜스포머는 이미지가 먼저 나오는 입력값을 이해할 수 없다. 우리는 분할 임베딩(Segment Embedding)을 통해 단방향 생성만 가능한 기존 자동 회귀 트랜스포머의 한계를 극복한 것"이라고 설명했다.
이어 "기존 VQ-VAE의 이미지 압축·복원 능력을 향상시키기 위해 새로운 증강 기법인 크로스 레벨 피처 어그멘테이션(Cross-Level Feature Augmentation)을 제안한다. 이를 통해 이미지 압축·복원 과정에서 발생하는 손실을 최소화할 수 있다"고 말했다.
GPT-3보다 훨씬 작은 크기로도 비슷한 성능 달성
엑사원은 기존 모델에 비해 크기 대비 성능도 우수하다는 것이 배경훈 원장의 주장이다.
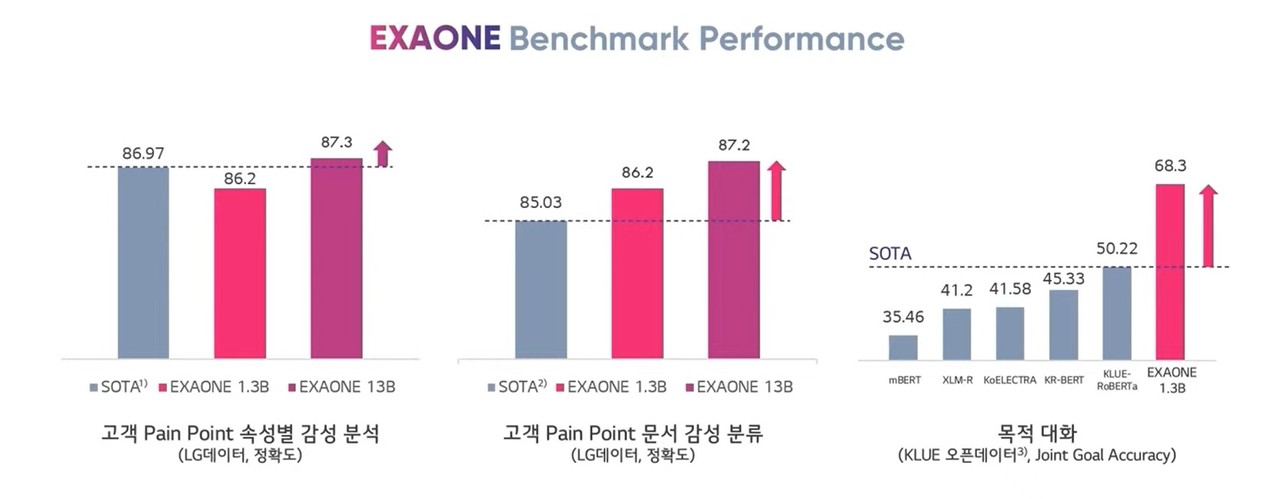
배 원장은 "13억개, 130억개 파라미터 크기의 엑사원 모델만으로도 GPT-3 성능을 넘어섰다. 특히 전문가와의 소통에서 가장 중요한 목적대화와 감성분류 영역에서 최고 수준을 보였다. 이미지 복원 퀄리티를 보여주는 FID 스코어에서도 최상 점수를 기록했다"고 전했다.
그러면서 "실제 애플리케이션에 활용 가능한 1024×1024 해상도로 이미지를 생성하는 것도 가능하다. 아직 벤치마크 테스트 중인 3000억개 모델에서 측정이 완료되면 기존 기록을 또다시 뛰어넘을 것"이라고 전했다.
신소재 발굴부터 메타버스까지 초거대 AI 활용 예정...AI 얼라이언스 구축 중
LG의 초거대 AI가 가장 먼저 실력을 발휘할 분야 중 하나는 신소재 산업이다.
배경훈 원장은 "신소재 발굴을 위해서는 전공자가 특허, 논문과 같은 문서 전체를 읽고 데이터베이스에 요약해야 한다. 분자구조식, 표와 같은 것들을 이해해야 하기에 모두 수작업으로 이뤄지고 있다"며 신소재 분야에 초거대 AI가 필요한 이유를 설명했다.
이어 "엑사원은 전공 문헌 전체 맥락을 이해해 대규모 물질데이터를 추출 가능하다. 엑사원으로 지난 100년간 발간된 모든 물질 정보를 데이터베이스화하고 신소재 AI가 인사이트 발굴하도록 개발할 예정"이라고 전했다.
장기 목표로는 메타버스 환경에서 사용자 감각을 확장하는데 초거대 AI를 사용할 계획이다.
배 원장은 "언어와 이미지 외 소리, 영상, 촉감 등 다양한 감각을 활용할 수 있는 멀티모달 AI로 개발할 예정이다. 각종 감각이 어려워지는 메타버스 환경에서 사용자 니즈를 충족시키려면 다양한 모달리티를 동시에 받아들이고 사고할 줄 아는 멀티모달 AI가 필수다. 아바타, AI 휴먼 등 메타버스 요소를 초거대 AI와 결합할 예정"이라고 말했다.
이와 같은 차세대 AI 연구를 이어가기 위해서는 내부 전문가만으로는 부족할 수 있다. 네이버, 카카오 등 초거대 AI 개발에 뛰어든 기업들이 대학과 긴밀한 협력체계를 구축한 이유다. LG AI 연구원도 AI 얼라이언스 구축에 힘쓰고 있다는 설명이다.
배경훈 원장은 "전략적 파트너사와의 협업과 AI 얼라이언스 구축에 주력하고 있다. 현재 캐나다 토론토대, 미국 미시건대, 서울대, KAIST와 초거대 AI 관련해 협업 중"이라고 전했다.
협력 기업과 대학 이외에 소속된 개발자들도 엑사원을 사용할 수 있도록 API 오픈도 단계적으로 진행할 계획이다. 우선 내년 상반기 중 일부 LG 계열사를 대상으로 엑사원 API를 공개한다.
배 원장은 "엑사원 오픈을 위해서는 추론(inference) 인프라 보강, 과금체계, 최적화, 경량화 등의 작업이 필요하다. 엑사원 생태계를 만들기 위해서는 집단지성이 필요하다. 이를 위해 API를 준비하고 개발 환경과 지원 시스템을 마련해 단계적으로 공개하겠다"고 전했다.
AI타임스 박성은 기자 sage@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com