GAN에서 생성된 합성 이미지의 속성을 명시적으로 제어
이미지 매개변수를 수치로 지정해서 이미지 속성을 수정
생성 이미지에 대한 제어 정밀도에서 이전 방식을 능가

아마존(Amazon)이 나이, 표정, 포즈, 조명 등 과 같은 속성을 설정하여 이미지를 좀 더 사실적이고 다양하게 생성하는 기술을 공개했다. 각 속성에 해당하는 이미지 매개변수를 수치로 지정해서 GAN(Generative Adversarial Networks)의 출력을 제어하는 새로운 접근 방식이다. 이 기술을 사용하면 GAN에서 생성되는 합성 이미지의 속성을 명시적으로 제어할 수 있게 된다.
최근 몇 년 동안 GAN은 사실적인 이미지를 합성하는 놀라운 능력을 보여주었다. GAN을 적용하는 대표적인 예로는 유명인의 얼굴 데이터셋을 학습해 인공적인 얼굴 이미지를 생성하는 것이다. GAN이 생성하는 합성 이미지는 점점 사실적으로 발전해왔다. 하지만 GAN의 주요 과제 중 한 가지는 포즈, 얼굴형, 머리 스타일과 같은 구체적인 특징을 바꿀 수 있도록 출력을 제어하는 것이다.

GAN의 훈련 설정에는 생성기(Generator)와 판별기(Discriminator)의 두 가지 기계 학습 모델이 포함된다. 생성기는 판별기를 속일 이미지를 생성하는 방법을 배우고 판별기는 합성 이미지를 실제 이미지와 구별하는 방법을 학습한다.
훈련 중에 모델은 이미지 매개변수 집합에 대한 확률 분포를 학습한다. 이 분포는 실제 이미지에서 발생하는 매개변수 값의 범위(예: 나이의 범위)를 설명한다. 그런 다음 해당 분포에서 임의의 점(매개변수 값의 집합)을 선택하고 생성기로 전달하면 새로운 이미지가 생성된다.
이미지 매개변수는 잠재 공간(latent space)을 정의한다. 높은 카메라 각도에서 낮은 카메라 각도, 젊은 얼굴에서 노인 얼굴, 왼쪽에서 오른쪽 조명 등 이미지 속성의 변화가 잠재 공간을 구성한다. 하지만 생성기가 블랙박스 신경망이기 때문에 공간의 구조는 알 수 없다.
제어 가능한 GAN에 대한 이전 연구는 잠재 공간의 구조를 배우는 데 집중되었지만, 잠재 공간을 구성하는 속성들이 얽혀 있어서 한 속성에 대해 학습하더라도 다른 속성에 대해서는 거의 알 수 없다.
최근 연구는 생성기에 사람 얼굴 이미지의 속성을 입력으로 지정하고, 생성기의 출력이 동일한 속성을 가진 3차원 그래픽 모델과 얼마나 잘 일치하는지 평가하는 보다 원칙적인 접근 방식을 채택하고 있다. 그러나 이 접근 방식에는 몇 가지 제한 사항이 있다. 하나는 얼굴에 대해서만 작동한다는 것이다. 또 다른 하나는 생성기가 합성 훈련 대상의 속성을 일치시키는 것을 학습하기 때문에 합성처럼 보이는 출력 이미지를 생성할 수 있다는 것이다. 그리고 마지막으로, 그래픽 모델로 사람의 나이와 같은 속성을 포착하기가 어렵다.
아마존이 공개한 기술은 이미지 매개변수를 수치로 지정해서 이미지 속성을 수정하고 다양한 이미지 범주에 적용될 수있는 GAN 제어 방법을 제시한다.
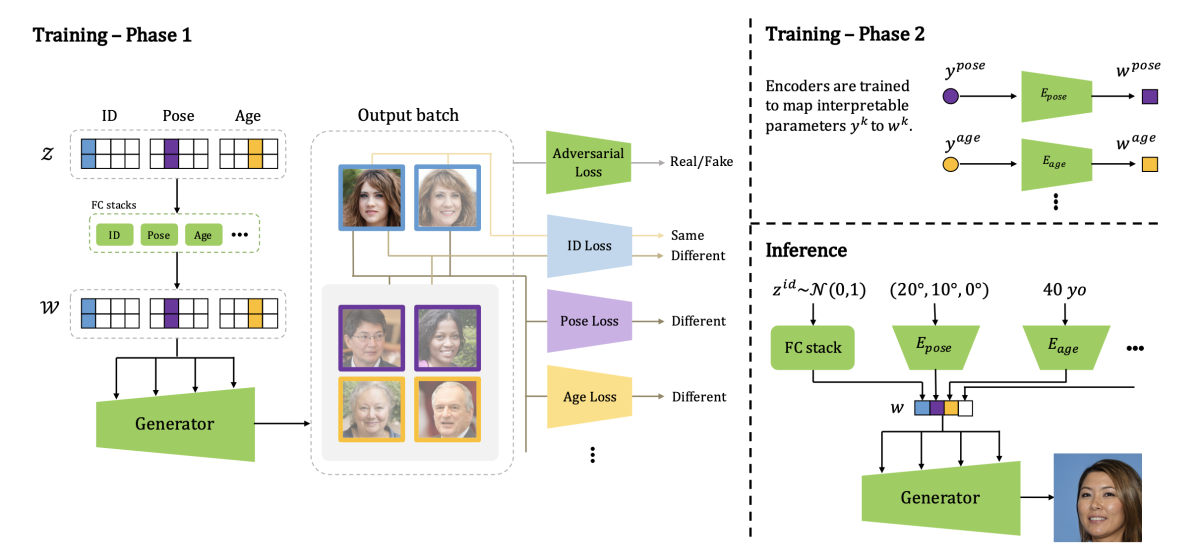
잠재 공간의 각 차원이 속성(z) 중 하나에 해당하도록 표현 공간을 제어하고 구성하려는 이미지 속성 집합을 선택한다. 그런 다음 한 차원에서는 동일한 값을 갖지만 다른 차원에서는 다른 값을 갖는 해당 공간의 점 쌍을 선택한다.
훈련하는 동안 구성된 공간의 점을 학습된 잠재 공간의 점으로 매핑하는 방법을 학습하는 완전 연결 신경망(fully connected neural network) 계층 세트를 통해 이러한 점 쌍을 전달한다(w). 학습된 공간의 점은 생성기의 컨트롤러 역할을 한다.
그런 다음, 판별기를 속이는 데 실패하면 생성기에 페널티를 주는 표준 적대적 손실과 각 속성에 대한 추가 손실을 계산한다. 손실은 속성을 공유하는 이미지를 잠재 공간에서 더 가깝게 만들고 속성을 공유하지 않는 이미지를 강제로 분리한다.
생성기를 훈련시킨 후에는 잠재 공간에서 무작위로 점을 선택하고 해당 이미지를 생성하고 속성을 측정한다. 그런 다음 측정된 속성을 입력으로 사용하고 잠재 공간의 해당 지점을 출력하는 새로운 컨트롤러 세트를 훈련한다. 이러한 컨트롤러가 훈련되면 측정된 특정 속성(y)을 잠재 공간의 포인트(w)에 매핑하는 방법을 배우게 된다. 여기서 y는 인간이 이해할 수 있도록 표현한 속성이다. 그런 다음 추론 단계에서 하위 벡터(w)를 사용하여 이미지를 합성할 수 있다.
방법을 평가하기 위해 3D 그래픽 모델을 사용하여 얼굴 생성기를 훈련하는 이전 방법 중 두 가지를 비교했다. 새로운 방법을 사용하여 생성된 얼굴이 이전 방법으로 생성된 얼굴보다 입력 매개변수와 더 잘 일치한다는 것을 발견했다.
또한 인간 피험자들에게 새로운 방법과 두 가지 기준으로 생성된 이미지의 사실성을 평가하도록 요청했다. 67%의 사례에서 피험자는 새로운 방법으로 생성된 이미지가 더 자연스럽다는 것을 발견했다.


AI타임스 박찬 위원 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com