라이다, 카메라 및 시간 데이터를 결합해 물체를 감지하는 신경망 개발
센서 데이터의 특성 결합을 위해 센서 입력과 특성 표현 간 연결을 학습
자기 주의 메커니즘을 사용하여 가장 연관성있는 특성 레이어를 선택
시간별 라이다 및 카메라의 4D 데이터를 사용하여 3D 객체 감지를 해결
시간에 따라 두 센서 입력을 결합하면 원거리 물체의 감지 정확도 향상

자율주행에서 실시간으로 3차원(3D) 물체를 감지하는 새로운 신경망 알고리즘이 나왔다. 이 알고리즘은 3차원 라이다(LiDAR)의 포인트 클라우드(point cloud)와 카메라의 RGB 이미지를 시간에 따라 결합하는 방법을 학습한다. 그래서 RGB가 제공하는 고해상도와 포인트 클라우드 데이터가 제공하는 정확한 깊이를 모두 활용해 기존 방식에선 놓쳤던 더 먼 거리의 물체를 감지할 수 있게 됐다.
구글이 개발한 이 신경망의 이름은 ‘4D-Net’이다. 라이다의 포인트 클라우드와 카메라가 포착하는 데이터의 특성을 연결해 학습하면서 앞에 보이는 장면의 4D 정보를 통합하는 동적인 연결 학습 방법을 사용한다.
라이다는 물체에 광 펄스(light pulse)를 보내서 돌아오는 시간을 기록하여 각 광 펄스 당 거리 정보를 계산하고 하나의 포인트(점)을 생성한다. 포인트 클라우드는 3차원 공간상에 퍼져 있는 여러 포인트의 집합(set cloud)를 의미한다. 라이다는 물체의 3D 좌표를 안정적으로 측정하는 유비쿼터스 센서지만 범위가 제한되어 있어서 센서에서 멀어질수록 반환되는 포인트가 줄어든다. 멀리 있는 물체는 소수의 포인트만 얻거나 전혀 얻을 수 없으며 라이다만으로는 볼 수 없다. 동시에 온보드 카메라의 이미지는 물체 감지 및 영역 분할 등을 통해 주행 차량 전면에서 펼쳐지는 광경을 이해하는데 매우 유용하다. 그러나 고해상도 카메라는 멀리 있는 물체를 감지하는 데 매우 효과적일 수 있지만 거리를 측정하는 데는 정확도가 떨어진다.
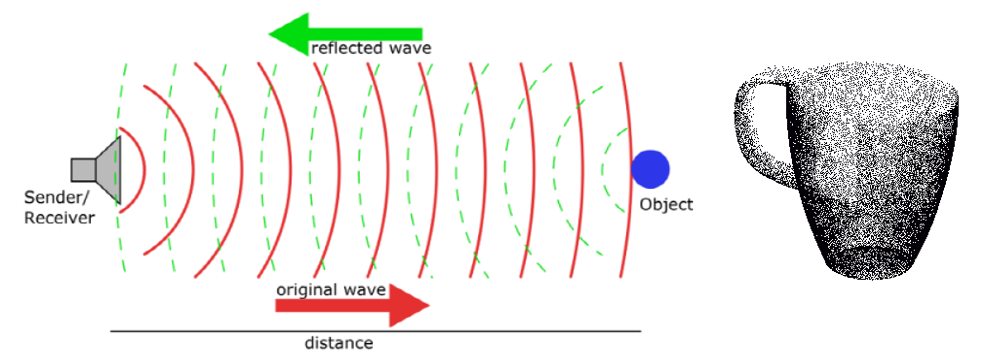
두 개의 센서(라이다와 카메라)가 측정한 데이터는 일정한 시간 간격으로 기록되어 4D 세계를 정확하게 표현한다. 두 가지 데이터를 동시에 독립적으로 사용할 경우 계산 효율성을 유지하기 어렵고 두 데이터간에 항상 직접적인 대응이 있는 것이 아니기 때문에 복잡성이 더 추가 된다.
그래서 4D-Net에서는 4D 입력(시간별 3D 포인트 클라우드 및 온보드 카메라 이미지 데이터)을 사용해 3D 객체 감지(box)를 해결한다. 각 센서 데이터의 특성 간의 정확한 대응 관계를 알기 위해 두 센서 입력과 특성 표현 간의 연결을 학습한다. 이를 위해 신경 아키텍처 검색(NAS, Neural Architecture Search)을 사용해 각 특성 레이어가 다른 센서 입력의 다른 잠재적 레이어와 결합될 수 있는 최적의 신경망을 구성한다. 정확한 3D 박스(Box) 감지를 위해 두 가지 유형의 센서 입력과 해당 특성 표현 간의 연결을 학습하는 것이다.
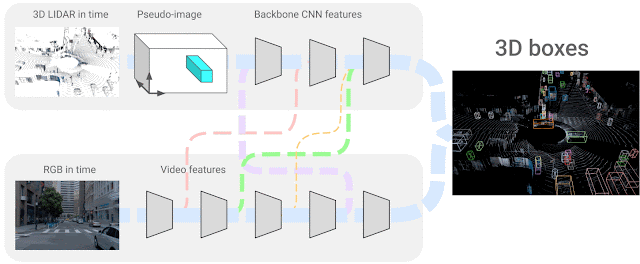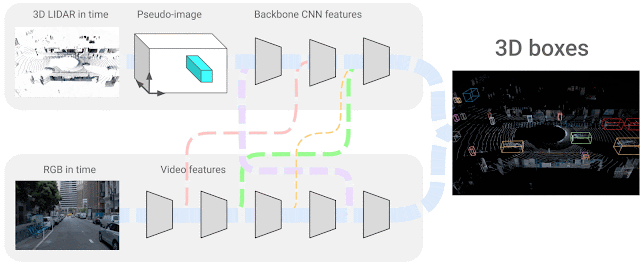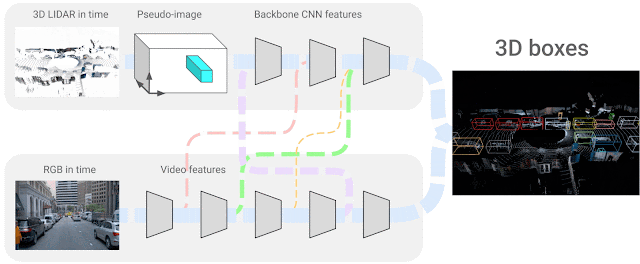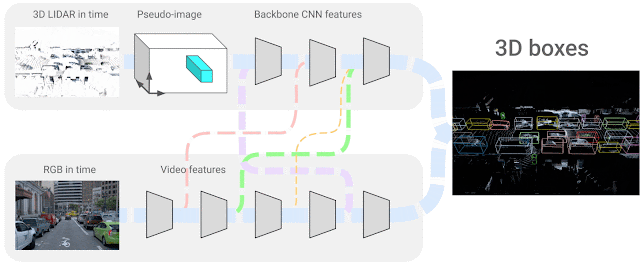
자율 주행 영역에서는 라이다 센서가 수백 미터에 달하는 거리에서 물체를 안정적으로 감지하는 것이 특히 중요하다. 관찰을 기반으로 연결을 동적으로 수정하고 자기 주의(self-attention) 매커니즘을 사용하여 가장 연관성있는 특성 레이어를 선택한다. 학습 가능한 선형 레이어를 적용해 다른 모든 레이어에 가중치를 적용하고 가장 적합한 조합을 학습할 수 있다.
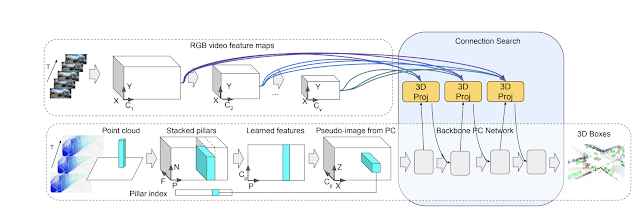
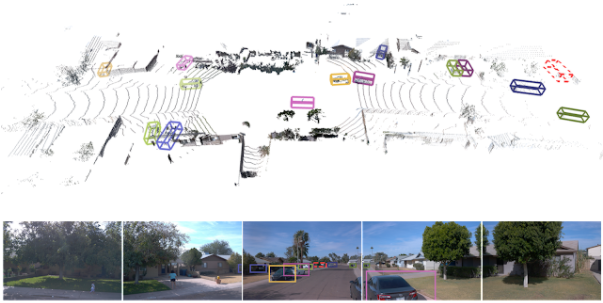
4D-Net은 두 센서 입력을 모두 효율적으로 사용해 32개의 포인트 클라우드를 시간별로 처리하고 164밀리초 내에 16개의 RGB 프레임을 처리하기 때문에 다른 방법에 비해 성능이 좋다. 4D-Net의 또 다른 장점은 RGB가 제공하는 고해상도와 포인트 클라우드 데이터가 제공하는 정확한 깊이를 모두 활용한다는 것이다. 결과적으로 이전에는 포인트 클라우드 사용 방식에선 더 먼 거리의 물체를 4D-Net으로 감지할 수 있다.
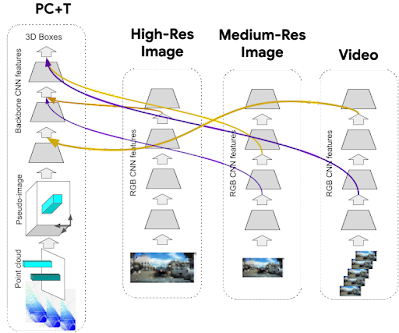
4D-Net 동적 연결 학습 매커니즘은 일반적이므로 포인트 클라우드 스트림과 RGB 비디오 스트림을 결합하는 것에만 국한되지 않는다. 추가로 3D 포인트 클라우드 스트림 입력과 함께 고해상도 단일 이미지 스트림 및 저해상도 비디오 스트림을 제공하는 것이 비용 측면에서 매우 효율적이라는 것을 발견했다.
AI타임스 박찬 위원 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com