창안 첸 메타AI 연구원

4차 산업혁명 핵심 기술은 메타버스(Metaverse)다. 코로나19로 인한 봉쇄 조치로 비대면 활동이 폭발적으로 증가하면서 메타버스 산업은 성장세를 이어갔다. 블룸버그 조사 결과에 따르면 2024년에는 전 세계 메타버스 시장 매출이 8천억달러(약 1천39조6000억원)에 육박할 것으로 전망된다. 작년 말 페이스북은 메타버스 산업에 집중하기 위해 기업명을 아예 ‘메타(Meta)’로 바꿨다.
메타버스가 거품이라는 지적도 있다. 메타버스 속에서 진행하는 모든 활동에는 아직 현실 세계와 비교할 때 지나치게 인위적이어서다. 실감 나는 요소가 부족하다는 의미다. 미 경제매체 마켓인사이더가 작년 12월 보도한 기사에 따르면 메타버스 회의론자들은 “메타버스는 과장됐다. 비디오 게임에나 적합한 그래픽 기술에 불과하다”고 지적한다. 실감 있는 가상세계 구축보다는 메타버스를 이용해 단기적 수익만 따라가는 행태를 비판한 셈이다.
전 세계 연구진들은 메타버스 세계를 더 실감 나게 만들기 위한 연구에 박차를 가하고 있다. 인간의 오감이 느껴져야 메타버스 세계가 현실과 연결될 수 있어서다. 창안 첸(Changan Chen) 텍사스대학교 오스틴캠퍼스(The University of Texas at Austin) 컴퓨터공학 박사과정생도 같은 생각이다. 2020년부터 메타AI 방문연구원으로 메타버스 관련한 시·청각 기술 개발에 매진하고 있다.
첸은 최근 열린 CVPR(Computer Vision and Pattern Recognition Conference) 2022에서 그동안 모은 데이터셋을 가지고 새로운 머신러닝(ML) 모델을 만들어 소개했다. 논문명은 'Visual Acoustic Matching'이다. 말 그대로 시각과 음성을 매칭하는 연구다.
첸은 특히 실감나는 메타버스에 필요한 시·청각적 요소에 집중했다. 이번 논문에 소개한 ‘AViTAR (the Audio-Visual Transformer for Audio Generation model)’ 모델을 통해서다. AViTAR 모델은 이미지-오디오에 기반한 합성 크로스모달 어텐션(cross-modal attention) 트렌스포머다. 오디오와 이미지 합성 시퀀스를 복합적으로 사용해 이미지 장소에 맞는 소리 파장을 만드는 머신러닝 모델이다.
쉽게 말해 같은 음성이어도 장소와 관련한 이미지를 모델에 입력하면 이에 어울리도록 자동으로 소리 울림(reverberation)과 파장을 바꾸는 기술이다. 그는 “똑같은 말소리도 환경에 따라 다르게 들린다"며 "이를 자동으로 조절하면 지금보다 더 실감 나는 메타버스 생태계 조성이 가능하다”고 <AI타임스>와의 화상 인터뷰를 통해 강조했다.
이번 연구가 메타버스 생태계 발전에 어떻게 도움 되는지 자세히 알기 위해 창안 첸을 화상으로 만났다.
[창안 첸(Changan Chen)과의 일문일답]
Q. MetaAI에서 지속적으로 연구하는 걸로 알고 있다. 최근 집중하는 분야는.

2020년부터 메타AI 본사에서 방문연구원으로 활동했다. 지금은 영국 런던 지사에서 연구 중이다. 최근 메타버스에 적용할 수 있는 비주얼-오디오 머신러닝(ML) 알고리즘을 집중적으로 연구 중이다.
다양하고 품질 좋은 데이터셋을 위한 수집에도 전념하고 있다. 해당 분야 연구는 데이터 수집이 관건인데, 시·청각 데이터는 모으기 까다롭다. 하나하나 신경 써가면서 해당 알고리즘 기능을 끌어올리고 있다.
Q. 이번 CVPR 2022에서 관련 연구 발표도 했다. 연구 내용을 쉽게 설명하자면.
머신러닝(ML)으로 시각-청각적 요소를 동시에 다루는 방식이다. 전문적 용어로 '가상 음향 매칭 작업 기술’이라 부른다.
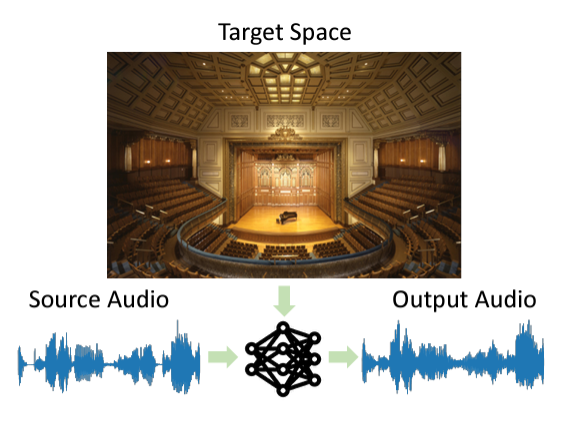
ML이 주어진 공간 이미지에 맞도록 오디오 클립을 변환해주는 기술이다. 이를 통해 같은 음성이어도 장소에 따라 소리가 다르게 날 수 있다.
Q. 장소에 따라 소리가 다르다는 게 정확히 어떤 의미인지.

모두 알다시피 장소가 어디인지에 따라 같은 음성도 다르게 들린다. 공간에 따라 소리가 내는 파장, 높낮이 등이 달라서다. 공간 건물이 가진 기하학적 구조를 비롯해 지붕 모양, 벽지 재질이 음성 울림(Reberveration)을 결정한다.
예를 들어 작은 방 안에서 대화하는 것과 큰 대강당에서 마이크를 통해 말하는 것은 울림 자체가 다르다. 대강당에서 말할 때 파장과 울림이 더 크다. 나는 이를 AViTAR 이라는 ML 모델을 통해 하나의 음성을 다양한 환경에 매칭함으로써 파장과 울림을 자동 조절하도록 구현했다.
Q. 이번에 제시한 AViTAR 모델은 어떤 원리인가.
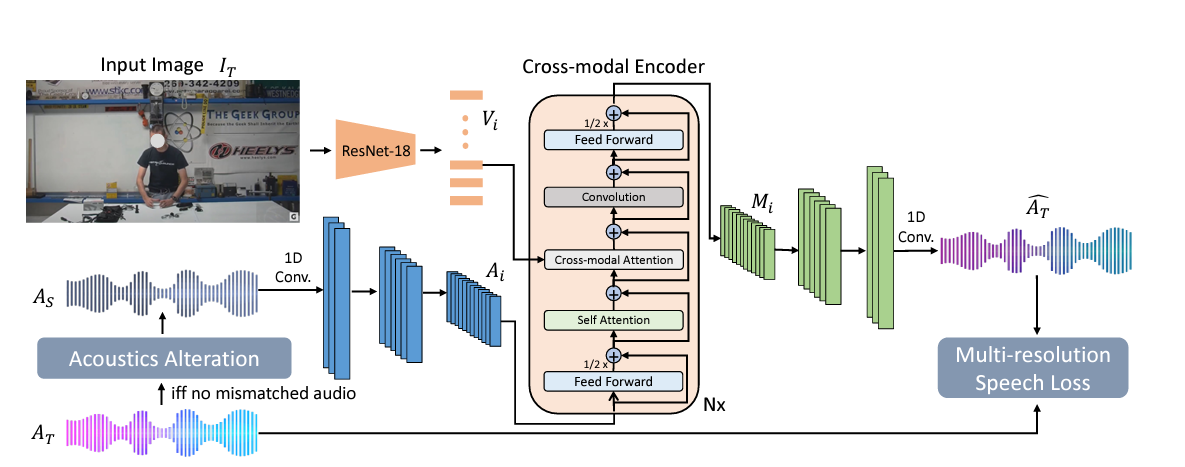
장소에 따라 정해진 이미지를 해당 모델에 입력하면, 이에 맞는 음성으로 자동변환하는 모델이다.
예를 들어 대강당에서 연설하는 음성은 울림이 크다. 이를 방 안에서 들리는 것처럼 바꿀 수 있다. AViTAR이 방 안 환경에 맞게 음성 울림과 파장을 자동으로 조절할 수 있다.
그 반대도 가능하다. 방 안에서 대화한 음성에 울림을 자동으로 추가할 수 있다. AViTAR에 대강당 이미지를 주입하면, ML이 자동으로 판독해 대강당에 어울리는 음성을 내놓는 방식이다.
사실 이런 기술은 기존에도 있었다. 그런데 잡음이 많고 음성 파장을 적재적소에 자동 배치하는데 서툴렀다. 다른 ML 모델과 비교했을 때 AViTAR이 가장 깔끔하게 비주얼-오디오 매칭을 진행하는 성능을 보였다.
Q. 음향 편집은 사람도 할 수 있는 분야인데.
그렇다. 물론 사람이 다양한 장비와 소프트웨어(SW)를 갖고 편집해 소리를 바꿀 수 있다. 그런데 모든 사람이 음향 기술을 다룰 수 없다. 어느 장소에서는 소리 파장을 얼마나 줄여야 하는지, 이에 맞는 SW는 무엇이 필요한지 알려면 전문적 기술 지식이 필요하다.
그리고 무엇보다 AViTAR 모델은 단순히 음향 편집을 목적으로 하는 기술이 아니다. 자동으로 소리 울림과 파장을 어울리는 장소에 변환하고자 하는 연구는 메타버스 같은 가상세계에서 유용하게 쓰기 위해 개발한 시스템이다.
Q. 해당 모델을 메타버스 기술에 접목하겠다는 건가. 그 이유는.

메타버스는 가상세계다. 그렇다고 현실과 너무 동떨어져서도 안 된다. 가상세계에 있어도 현실에 있는 것처럼 구현해야 한다. 이를 위해 가장 중요한 기술적 과제는 ‘현실성’이다. 사람의 오감이 메타버스에서 실감 나게 느껴져야 한다. 그중 소리가 관건이다. 아무리 미각이 잘 느껴져도 현장 소리가 단조롭거나 기계 소리만 나면 몰입감이 떨어진다.
장소가 어디인가에 따라, 그리고 그 장소 안에서 사용자가 어디에 서있느냐에 따라 각양각색의 소리가 나야 하는게 메타버스 필수 요소라 본다. 그래서 만든 모델이 AViTAR이다.
Q. 해당 기술이 메타버스에서 어떻게 적용될 수 있나. 구체적인 예시는.
대표적인 예가 메타버스 내에서 증강현실(AR) 기구로 가상 통화할 때다. 두 사람 모두 다른 장소에 있지만, 자신이 있는 장소 이미지를 ML에 입력하면 그 환경에 맞는 소리로 통화할 수 있다. 비주얼-오디오를 매칭해 마치 옆에서 대화하는 것처럼 상대방 목소리가 들린다.
메타버스 플랫폼을 통해 회의하거나 수업할 때도 마찬가지다. 바로 앞에서 들리는 음성으로 인해 몰입도와 집중력을 높일 수 있다.
Q. AViTAR에 적용한 데이터셋이 두 종류 적용된 걸로 알고 있다. 하나는 CVPR 2020에서 공개한 ‘사운드스페이스(SoundSpaces)’고, 다른 하나는 이번에 새로 제시한 ‘어쿠스틱(Acoustic) AVSpeech’로 알고 있다. 새로운 데이터셋은 어떻게 모았나.
Acoustic AVSpeech는 유튜브 영상에서 가져온 데이터셋이다. 특정한 기준에 따라 선별해 모았다. 그야 말로 가내수공업 수준 데이터 수집이었다.
영상 선별 기준은 3초에서 10초 사이다. 사람 한 명이 어떠한 시·청각적 개입 없이 나와야 한다. 규모는 총 4천700시간이다. 화질은 290k이상이다.
이번 데이터셋을 만든 목적은 기존 데이터에 사용자가 요청한 장소와 맞는 오디오가 없을 때를 대비해서다. 웹 영상에서 음향 매칭을 배워 적용하는 식이다.
Q. 왜 굳이 3초에서 10초 사이 영상이어만 했나.
3초에서 10초 사이에 나오는 오디오로 가장 많은 데이터셋을 뽑아낼 수 있다. 우선 해당 영상은 화자가 무엇을 말하는지뿐만 아니라 카메라가 찍고 있는 주변 환경 특성에 따라 울리는 울림(Reverberation)도 데이터셋으로 저장할 수 있다. 이때 가장 적합한 시간이 3초-10초다. 장소에 따른 울림을 추출하는 게 주 목적이라서 소리가 많이 울리는 비디오 클립을 주로 채택했다.
Q. 메타버스 기술에만 적용하기에는 아까운 기술인데, 그 외 다른 분야에도 적용할 수 있나.

대표적인 게 영화 더빙이다. 더빙된 영화를 보면 알겠지만, 원본 버전보다는 음성 매칭이 부자연스럽다. 실감이 덜 하다는 의미다. AViTAR을 통해 영화 장면 환경에 맞는 음성 파장을 삽입해 마치 현장에서 녹음한 것처럼 들리 게 할 수 있다. 이를 응용해 일반 영상 편집에서도 활용 가능하다고 본다.
Q. AViTAR을 VR 안경 등에 탑재해 상용화할 수 있나.
아직 이르다. 데이터셋이 충분하지 않다. 겨우 길을 냈을 뿐이다. 구체적으로 말하자면 어쿠스틱 AVSpeech 같은 데이터셋은 다양성이 부족하다. 디테일한 환경에 적용할 수 있는 음성 가짓수가 적다.
메타버스 세계도 현실처럼 다양한 환경이 존재한다. 같은 장소여도 미세한 음성 차이를 낼 수 있도록 데이터가 풍부해야 한다. 또 SoundSpaces와 달리 어쿠스틱 AVSpeech는 잡음이 있다. 앞으로는 다양하고 품질 좋은 음성 데이터셋을 모으겠다.
Q. 향후 연구 계획은.

현재 하고 있는 비주얼-오디오 매칭 연구에 몰두하겠다. 관련된 다양한 알고리즘을 만들어 메타버스를 비롯한 다양한 산업에 적용해 실감나는 소리 기술을 만들겠다.
사람은 같은 장소에서 고개를 살짝 돌리기만 해도 소리에 차이가 나는 걸 느낄 수 있다. 메타버스에서 이 정도로 세밀한 차이를 만들 수 있도록 데이터셋 수집에 몰두하겠다.
이번 비주얼-오디오 기술은 단순히 메타버스 산업에만 그치지 않는다고 본다. 청각 기능이 불편한 노약자가 더 잘 들을 수 있는 기술에도 도움 된다. 해당 기술을 보청기 같은 기구에 탑재하면 된다.
듣기 어려워하는 사람들은 인파가 몰린 곳에서 동행자와 조금만 떨어져 있어도 대화하기 힘들다. 풍부한 데이터셋을 갖춘 모델을 탑재한 기구를 통해 멀리 떨어져 있어도 바로 옆에서 상대방이 말하는 것처럼 들릴 수 있게 하겠다.

창안 첸(Changan Chen) 은 중국 주지안대학(Zhejiang University) 컴퓨터공학과를 졸업하고 캐나다 사이먼 프레이저 대학(Simon Fraser University) 컴퓨터공학과 석사 학위를 취득했다. 모두 최우수(Distinction)로 졸업했다.
2019년부터는 미국 텍사스대학교 오스틴(The University of Texas at Austin)컴퓨터공학과 박사 과정 중이다. 2020년부터 현재까지 메타AI에서 방문 연구원으로도 활동하고 있다.
AI타임스 김미정 기자 kimj7521@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com