소량의 데이터로 학습할 수 있는 퓨샷 러닝이 가능한 언어 모델
200억 개의 매개변수로 구성된 인코더-디코더 구조의 seq2seq 모델
기계 번역 및 텍스트 요약에서 GPT-3보다 성능이 우수

아마존(Amazon)이 음성 비서 알렉사(Alexa)를 개선할 수 있는 새로운 AI 언어 모델을 공개했다.
KDD(Knowledge Discovery and Data Mining Conference)에 발표된 논문에 따르면 ‘Alexa Teacher Models(AlexaTM) 20B’은 소량의 데이터로 새로운 작업을 학습할 수 있는 퓨샷 러닝(few-shot learning)이 가능한 seq2seq(sequence-to-sequence) 구조의 대규모 언어 모델이다.
seq2seq는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델이다. 챗봇(Chatbot)과 기계 번역(Machine Translation)이 대표적인 예로, 입력 시퀀스와 출력 시퀀스를 각각 질문과 대답으로 구성하면 챗봇으로 만들 수 있고, 입력 시퀀스와 출력 시퀀스를 각각 입력 문장과 번역 문장으로 만들면 번역기로 만들 수 있다. 그 외에도 텍스트 요약(Text Summarization), 음성-텍스트(Speech-to-Text) 변환 등에서 쓰일 수 있다.
이름에서 알 수 있듯이 AlexaTM 20B는 200억 개의 매개변수로 구성된 언어 모델이다. AlexaTM 20B는 GPT-3와 같은 디코더(decoder) 전용 구조의 다른 언어 모델과 달리 인코더-디코더(encoder-decoder) 구조의 seq2seq 모델이다. 이러한 유형의 구조에서 인코더는 양방향 인코딩을 사용해 입력 텍스트를 컨텍스트 벡터(context vector)로 표현하고 디코더는 해당 표현을 사용해 입력의 번역을 생성한다.
반면에 디코더 전용 모델은 입력 텍스트의 왼쪽에서 오른쪽으로 단방향 인코딩을 사용한다. 이것은 선행하는 토큰을 기반으로 시퀀스의 다음 토큰을 예측하는 작업인 언어 모델링에는 적합하지만 AlexaTM 20B가 GPT-3보다 더 우수한 성능을 보이는 기계 번역 및 텍스트 요약에는 덜 효과적이다.
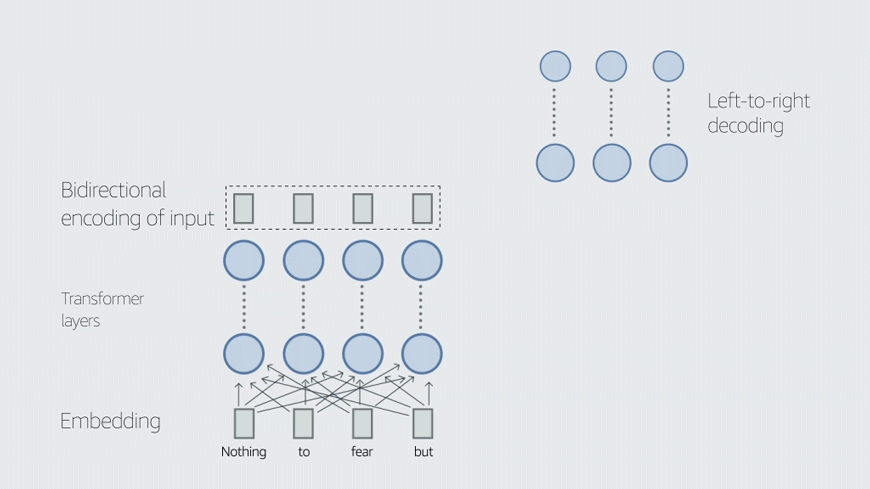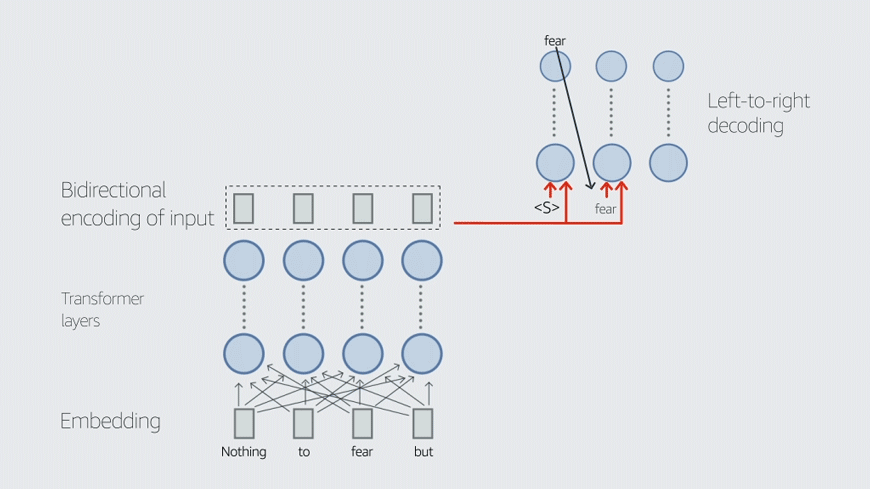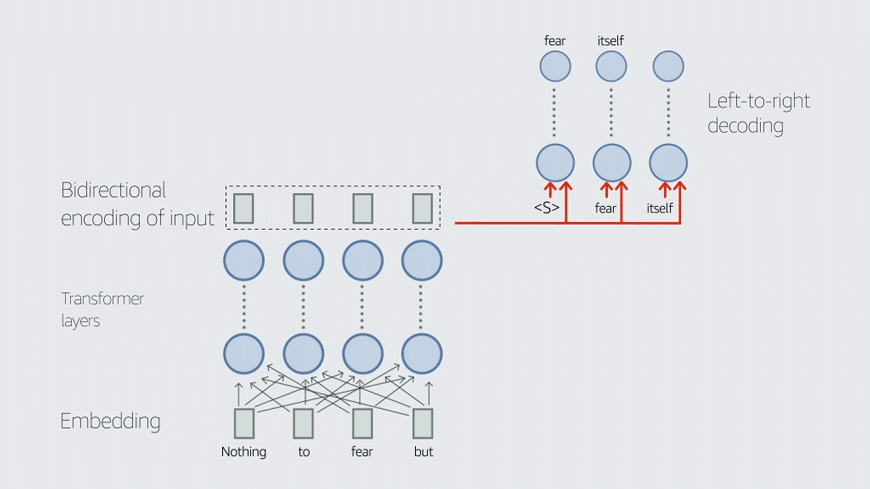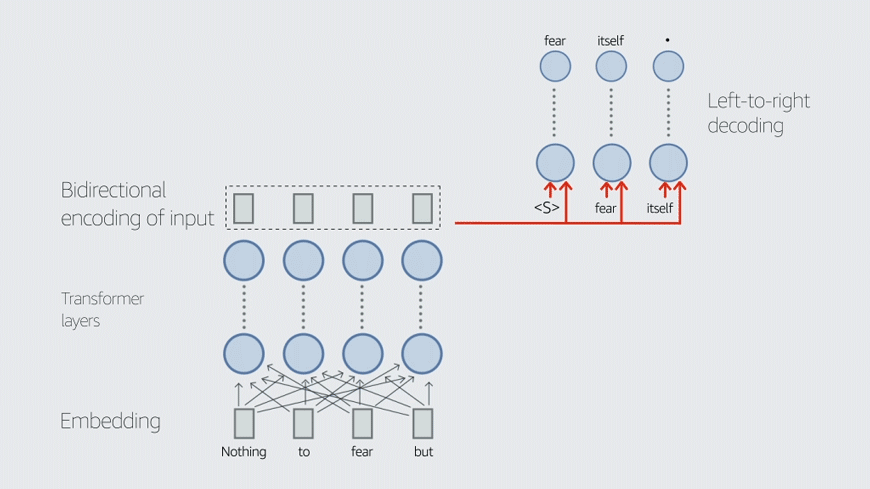
또한 AlexaTM 20B 모델은 잡음 제거(denoising) 및 인과적 언어 모델링(casual language modeling) 작업이 혼합된 사전 훈련 과정을 가지고 있다. 잡음 제거 작업을 수행하려면 모델이 누락된 범위를 찾고 완전한 버전의 입력을 다시 생성해야 한다. 인과적 언어 모델링은 의미 있는 텍스트를 계속 입력한다.
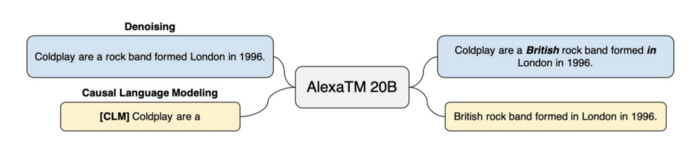
AlexaTM 20B 아키텍처의 가장 큰 성과는 퓨샷 러닝 기능에 있다. AlexaTM 20B는 효과적으로 퓨샷 러닝이 가능한 최초의 가장 큰 다국어 seq2seq 모델이다. 주어진 언어에서 특정 의도를 나타내는 입력이 주어지면 모델은 작업을 다른 언어로 일반화한다. 이를 통해 대규모 훈련 과정 없이 다양한 언어로 새로운 기능을 쉽게 개발할 수 있다.
그 결과 AlexaTM 20B는 Flores-101 데이터 세트에서 지원되는 모든 언어 쌍에 걸쳐 적은 수의 학습 작업으로 최첨단 성능을 달성할 수 있었다. 또한 AlexaTM 20B는 이러한 여러 작업에서 GPT-3보다 성능이 뛰어나다.
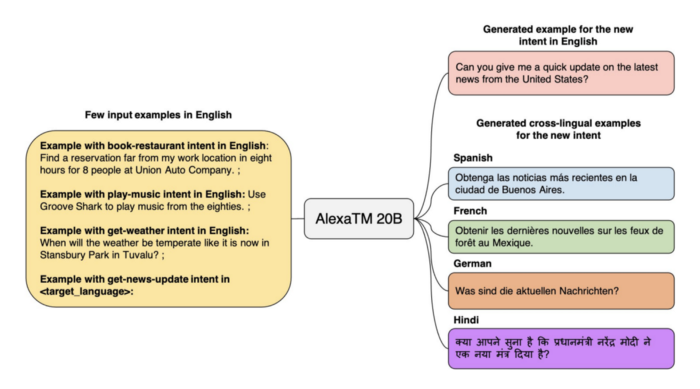
AlexaTM 20B의 최신 버전은 아랍어, 영어, 프랑스어, 독일어, 힌디어, 이탈리아어, 일본어, 마라티어, 포르투갈어, 스페인어, 타밀어, 텔루구어 등의 언어를 지원한다. 이 기능은 리소스가 많은 언어와 리소스가 적은 언어의 언어 모델 간의 격차를 해소할 수 있다. 아마존은 비상업용 AlexTM 20B의 공개 버전을 출시할 예정이다.
AI타임스 박찬 위원 cpark@aitimes.com
[관련기사]구글, AI 언어모델 'LaMDA 2'를 위한 베타 테스트 공개
[관련기사]메타, 언어 모델 OPT-175B 무료 공개
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com