스탠포드대, 음악 입력하면 춤 만들어 주는 AI도구 '엣지' 공개

음악을 듣고 음악에 어울리는 댄스를 생성하는 인공지능(AI) 안무가가 등장했다.
스탠포드 대학 연구원들이 음악을 입력하면 이에 맞춰 사실적이고 물리적으로 그럴듯한 춤을 만들어 주는 AI 도구 '엣지(EDGE: Editable Dance Generation)'를 공개했다고 마크테크포스트가 24일(현지시간) 보도했다.
엣지는 고품질 댄스을 생성하기 위해 음악 특징 추출기인 '쥬크박스(Jukebox)' 모델과 이미지 생성 AI에 활용된 '확산 모델(Diffusion Model)'을 사용한다. 또 관절 컨디셔닝 및 인비트윈을 포함해 댄스에 적합한 편집 기능을 제공한다.
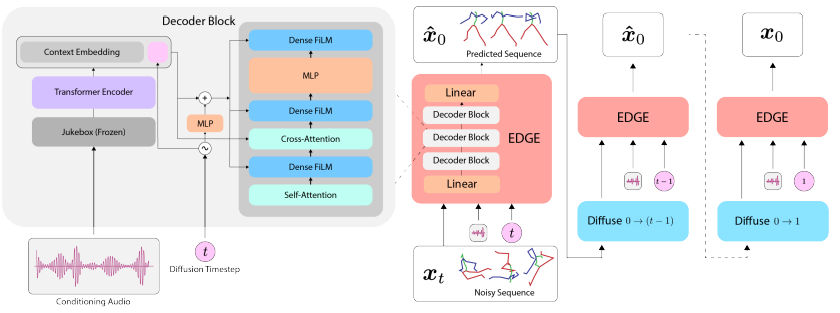
또 쥬크박스 모델의 음악 임베딩을 사용해 입력하는 음악의 특징을 음악 오디오 표현으로 바꾼 다음 일련의 5초 댄스 클립에 포함된 음악을 댄스에 매핑하는 방법을 확산 모델에 가르친다.
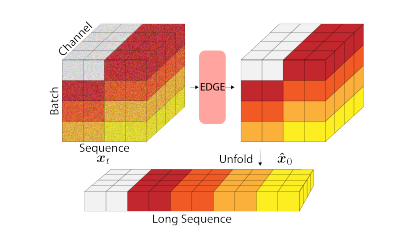
5초 클립으로 훈련되지만 임의 길이의 댄스를 생성할 수 있다. 전체 댄스를 여러 개의 시퀀스로 나누고 시퀀스 간에 연속성을 적용해 하나의 긴 시퀀스로 연결할 수 있다. 각 시퀀스의 처음 2.5초를 이전 시퀀스의 마지막 2.5초와 일치시켜서 연속성을 제공한다.

또 춤은 의도적으로 발을 지면에 미끄러지듯이 지면에 접촉하는 일이 많다. 엣지는 슬라이딩을 온전하게 유지하면서 물리적 현실감을 향상시키기 위해 발이 미끄러져야 할 때와 미끄러지지 않아야 할 때를 학습한다.
음악에 맞춰 댄스를 생성하는 엣지 (영상=스탠포드 대학)
박찬 위원 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com
박찬 위원
cpark@aitimes.com