
애플이 최고 성능의 이미지-텍스트 멀티모달 모델을 공개했다. 고작 300억 매개변수 모델로 이미지를 읽고 자연어로 설명하는 능력(VQA)에서 오픈AI 'GPT-4V'와 구글 '제미나이 울트라'를 일부 추월했다고 밝혔다.
벤처비트는 15일(현지시간) 애플 연구진이 정교한 사전 훈련 과정을 거친 최대 매개변수 300억개의 대형멀티모달(LMM) 'MM1'을 온라인 아카이브를 통해 공개했다고 보도했다. 이 모델은 이미지를 생성하지는 않는다.
연구진이 발표한 논문의 제목은 'MM1: 멀티모달 LLM 사전 교육의 방법, 분석 및 통찰력'이다. 여기에서는 고성능 LMM을 구축하기 위해 다양한 아키텍처의 구성과 학습용 데이터셋 선별 등을 집중 실험했다고 전했다.
이를 통해 단일 모델이 아닌, 사전 훈련을 통해 상황별로 SOTA('State-of-the-art, 현 최고 수준)를 기록한 모델 여럿을 구축하고, 이를 '전문가 혼합(MoE)' 방식으로 조합했다. 이를 통해 매개변수 30억개(3B), 70억개(7B), 300억개(30B) 등 제품군을 구성했다.
연구진은 이미지 인코더와 비전-언어 커넥터, 다양한 사전 훈련 데이터 등을 채택가고 골라내는 과정에 몇가지 중요한 설계 교훈을 발견했다고 전했다.
“우리는 이미지 해상도 및 이미지 토큰 수와 함께 이미지 인코더 선택이 상당히 중요한 반면, 비전 언어 커넥터 설계는 상대적으로 중요하지 않다는 것을 발견했다”라고 말했다. 이는 LMM의 시각적 구성 요소를 지속적으로 확장하고 개선하는 것이 성능 향성의 핵심이라는 것을 의미한다.
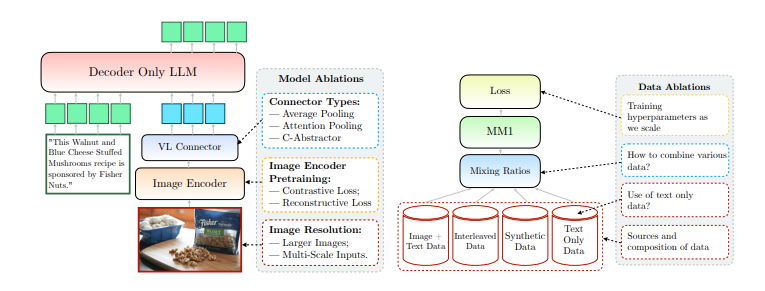
또 이미지 캡션, 인터리브 이미지 텍스트 및 텍스트 전용 데이터 등을 혼합하는 것도 벤치마크 최고 성능을 달성한 중요한 이유가 됐다고 밝혔다.
이런 대규모 멀티모달 사전 훈련 덕분에 MM1은 컨텍스트 러닝(in-context learning), 다중 이미지 추론(multi-image reasoning), 퓨샷 CoT 프롬프트(few-shot chain-of-thought prompting) 등을 활용해 이미지를 이해하고 답하는 데 탁월한 성능을 보인다는 설명이다.
그 예로 ▲이미지 속에 등장하는 개체를 구분하고 각각의 숫자를 셀 수 있으며 ▲이미지 속 간판이나 표시 등 텍스트를 정확하게 읽어낼 수 있으며 ▲이미지 속 냉장고의 무게 등과 같은 사물에 대한 지식을 설명할 수 있으며 ▲이미지를 통한 기본적인 계산이 가능하다. 즉, 단순 이미지 설명을 넘어 언어 기반의 이해와 생성이 필요한 복잡하고 개방형 문제를 해결할 수 있다.
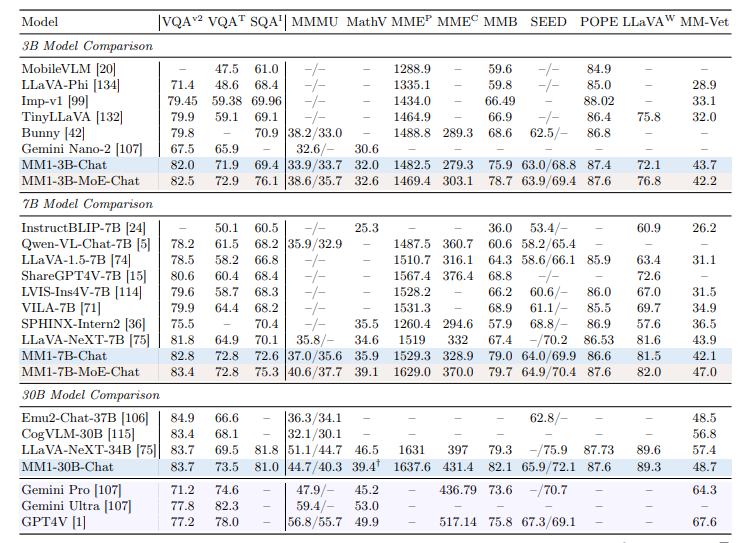
벤치마크에서는 MM1 3B와 7B 모델이 동급의 '라바(LLaVA)'나 '제미나이 나노' '큐원' 'GPT-4' 등 멀티모달 모델의 성능을 대부분 앞질렀다. 30B 모델은 매개변수가 각각 1조5600억개(1560B)와 1조7600억개(1760B)로 알려진 제미나이 울트라와 GPT-4와 맞먹거나 앞서는 성능을 보였다.
이번 연구는 AI에 대한 애플의 발전을 보여주는 중요한 사례라는 평가다.
애플은 지난해말부터 본격적으로 AI 연구 개발에 나서며, 전용 칩에서 온디바이스 AI를 구축하는 프레임워크와 칩에서 AI를 구동하는 데 최적화한 기술을 선보인 바 있다. 또 지난 10월 7B·13B 멀티모달 모델 '페렛'을 오픈 소스를 시작으로 최근까지 혁신적인 AI 논문을 계속 발표하고 있다.
애플은 올해 10억달러(약 1조3300억원)를 투자, 제품 전 라인업에 생성 AI 도입을 시도하고 있다.
임대준 기자 ydj@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com