흑인 비하, 성범죄, 몰카사진 등 2000개 포함
명사에 의존해 데이터셋을 추출한 것을 원인으로 지목
MIT와 뉴욕대학교(NYU)는 공동 구축한 사진 데이터셋 '타이니 이미지스' 8000만개 가운데 일부가 인종차별 및 성적 침해를 했다고 인정, 비공개로 전환했다. 또 이를 갖고 있는 외부 연구원팀에게도 삭제할 것을 요청했다.

최근 빌프리만 MIT 교수와 안토니오 토랄바, 롭 퍼거스 NYU교수는 이같은 내용을 담은 서한을 MIT CSAIL웹 사이트에 게재했다고 벤처비트는 1일(현지시간) 보도했다.
이 데이터셋은 2006년부터 인터넷 검색 엔진에서 8000만장 이상의 사진을 수집해왔다. 하지만 최근 흑인 비하, 성범죄, 몰카사진 등 2000개를 포함하고 있는 것으로 밝혀져 파문이 일고 있다.
또한 이 가운데 793만장은 사진이 너무 크거나 작아서 육안으로 검사하는 것이 어려운 것으로 밝혀졌다. 현재 구글 학술 검색 서비스에서 등재된 자료들중 이 데이터셋을 인용한 횟수는 1700회 이상인 것으로 밝혀졌다.
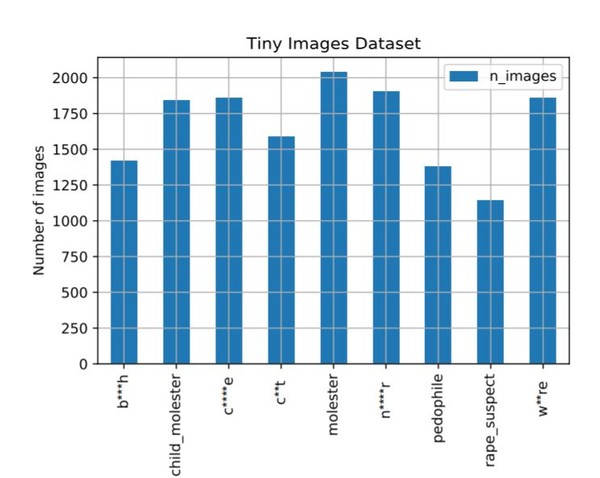
이 문제는 지난달 더블린 대학교와 카네기 멜론 대학교에 다니는 박사과정 대학원생 두명이 연구 결과를 공개하며 알려졌다. 그들은 명사에 의존해 데이터셋을 추출한 것을 원인으로 지목했으며 데이터셋을 비공개로 전환 하기 전에 데이터셋의 사용자 카테고리에서 사용된 라벨을 평가하라고 권고했다.
또한 그들은 데이터셋 구축시 지켜야 할 지침 4개를 다음과 같이 제시했다.
ㆍ데이터 집합에서 개인 얼굴을 흐릿하게 처리
ㆍ크리에이티브 커먼즈(CC) 라이센스 자료 사용 금지
ㆍ데이터셋 수집 시 개인 동의 얻기
ㆍ구글 AI 모델 카드 및 마이크로 소프트(MS) 리서치 데이터셋과 유사한 대규모 데이터셋과 검사 카드를 포함할 것.
연구결과에 따르면 그들은 "단순한 데이터의 문제를 넘어서 학계와 업계가 익명성을 명분삼아 개인 동의 없이 대규모 데이터셋을 생성해도 된다고 생각하는 관행을 타파해야 한다"고 밝혔다.
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com