네이처 머신 인텔리전스 12월호 표지 논문 선정
인간에 의한 수학적 모델링 대신 AI가 뇌 작용 모방해 RL 구축
기존 방식보다 복잡한 환경 대상으로 빠른 네트워크 학습 가능

인간 뇌 내부 매커니즘을 모방해 강화학습(RL) 알고리즘을 만드는 기술을 개발한 국내 연구팀 논문이 네이처 머신 인텔리전스 12월호 표지를 장식했다.
고려대 이성환 인공지능학과 교수와 폴 베르텐스(Paul Bertens) 박사과정 학생 연구팀의 ‘시냅스 학습 규칙과 스파이킹 역학을 배울 수 있는 진화 가능한 신경 유닛 네트워크(Network of evolvable neural units can learn synaptic learning rules and spiking dynamics)’연구에 대한 이야기다.
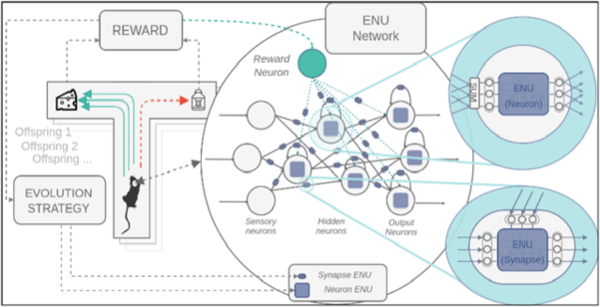
이성환 교수 연구팀은 인간 뇌 내부 매커니즘을 모방해 강화학습하는 새로운 생물학적 인공지능(AI) 알고리즘을 만들었다. 연구팀이 개발한 진화하는 뉴럴 유닛(ENU)은 생식, 무작위 돌연변이, 적자 생존 원칙 등 진화 프로세스와 같은 방식으로 특정 문제에 적합한 인공신경망을 만든다. 뉴런과 시냅스를 모방한 미니 뇌들이 RL 에이전트가 되어 서로 간에 협력·진화하면서 주어진 문제를 해결하는데 적합한 네트워크를 구축하는 것이다.
인간 연구원이 수학적 모델링을 이용해 디자인하는 기존 RL 알고리즘과 달리 자연 속 법칙을 사용하는 것이 차별점이다. 연구팀이 따르면 ENU 사용 시 기존 수학적 모델링 기반 방식보다 복잡한 행동에 대해 학습할 수 있다. 기존 접근법보다 네트워크 학습 기간도 대폭 줄일 수 있다는 설명이다.
Q. 기존 인공신경망 모델과 다른 ENU 특징을 자세히 설명한다면?
기존에 뇌 하나를 모델링하는 방식과 달리 여러 인공 미니-뇌가 협력하는 네트워크를 만들었다. 기존 인공신경망은 간단한 수학적 기반 모델을 통해 뇌 시냅스와 뉴런을 구현한다. 우리가 제안한 ENU는 뉴런과 시냅스 각각을 작은 인공신경망으로 대체해 사용한다. 각 뉴런과 시냅스는 큰 네트워크 내부의 미니-뇌가 되어 전체 네트워크가 작동하는데 협력한다.
실제 생물학적으로 뉴런은 정보 처리를 담당하며 시냅스는 새로운 행동을 학습할 때 변화한다. 각 시냅스와 뉴런 역할을 담당하고 있는 ENU 미니-뇌는 이런 과정을 모방했다.
Q. 여타 강화학습 모델과의 차별점은 무엇인가?
기존 RL방법은 네트워크가 학습되기까지 굉장히 많은 시행착오가 필요하다. 하지만 생물학적 뇌는 몇 번의 경험으로 굉장히 빠르게 학습이 가능하다. ENU도 현재 접근방식들보다 빠르게 학습할 수 있다.
ENU 구조를 진화 알고리즘을 사용해 학습함으로써 훨씬 더 복잡한 행동을 학습할 수도 있다. 이러한 진화는 일종의 RL 형태지만 인간이 구축하는 수학적 모델링을 사용하지 않는다.
Q. 딥마인드 오준혁 박사가 최근 발표한 강화학습 알고리즘 구축 AI과 비슷한 원리인가?
ENU는 기존 RL 방법들과는 다른 방식으로 작동하며, 훨씬 생물학적 영감을 받은 연구 성과다. 미니 뇌 구조를 학습하는데 인간 디자인 방식 대신 진화 알고리즘을 사용했다. 이 알고리즘 자체는 기존에 쓰인 학습 방법이지만 적용 영역을 달리한 것이 새로운 점이다. 우리는 진화학습 방법이 실제 자연에서 그렇듯이 무수히 많은 경우의 수에서 더 나은 솔루션을 제공해준다고 생각한다.
[관련기사]"강화학습 모델 AI가 더 잘 만든다" 딥마인드 오준혁, LG AI연구원 창립 행사 발표
Q. ENU 방식 효과를 입증하기 위한 실험은 어떻게 진행했는지?
기존 신경망에서 사용되는 가중치를 수정하는 방식 대신, 미니-뇌들의 협력 관계를 수정함으로써 보상과 벌점에 대한 기준을 파악하고 문제를 해결하도록 설계했다. 실험 환경은 실제 쥐의 행동학습을 실험하기 위해 사용하는 방식과 유사한 가상의 미로환경으로 설정했다. 실제 생명체에게 적용하는 것과 유사한 실험으로 ENU가 우리 의도대로 학습하는지 확인할 수 있었다.
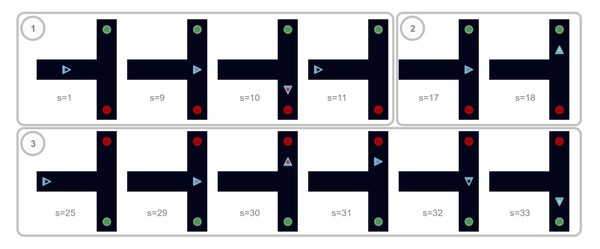
연구팀은 ENU 방식 AI 에이전트에게 T자형 미로 속에서 길을 찾는 문제를 냈다. T자형 미로 양끝에는 각각 색깔로 구분된 치즈(녹색)와 독약(빨간색)을 배치해 AI 쥐가 색깔을 감지해 독약을 피하고 치즈를 찾도록 했다.
미로 탐험과 먹이(치즈) 찾기를 목표로 설정한 후 연구팀은 AI 쥐에게 우선 보상(치즈)과 벌(독약)을 경험하도록 했다. 탐험 중 음식을 먹으면 에너지가 보충되고 독을 먹을 시 줄어들도록 설정했다. 에너지가 전부 고갈되면 죽어서 움직일 수 없도록 만들었다. 이후 보상 음식이 어디에 있었는지 기억하고 독성 여부를 파악하는 것을 AI 쥐가 학습을 통해 판단했다.
실험에서 AI 쥐는 10번 정도 시행착오를 겪은 후부터 치즈를 찾는 빈도가 높아졌으며 연구팀은 해당 시점부터 ENU 네트워크가 활성화됐다고 판단했다.
Q. 2019년에 arXiv에 관련 논문을 공개한 것으로 안다. 해당 연구와 최근 제출한 연구의 주요 차이점은 무엇인가?
2019년에 발표한 것은 프리프린트 성격의 arxiv 논문이며 리뷰를 받기 전이었다. 네이처 머신 인텔리전스에 출판하면서 라이팅이나 실험 부분에서 리뷰를 받고 수정 과정을 거쳐 논문 질을 더욱 개선했다.
[참고] 이성환 교수가 2019년에 발표한 관련 논문 ‘Network of Evolvable Neural Units: Evolving to Learn at a Synaptic Level’
Q. 이번 논문 공저자인 폴 베르텐스 박사과정 학생에 대해 설명 부탁드린다.
폴 베르텐스 학생은 우리 랩 박사과정 학생이다. 폴 학생이 해당 분야에 관심을 가지고 있어서 본 연구를 진행하게 됐다.
Q. 국내 연구팀이 네이처 머신 인텔리전스 표지를 장식한 사례는 드문 걸로 안다. 관련 소감 한 마디 부탁드린다.
우선 굉장히 기쁘고 영광스러운 일이다. 앞으로 우리나라에서 네이처 머신 인텔리전스 표지에 실릴 만한 수준의 연구가 많이 나올 것으로 기대한다. 계속해서 좋은 연구로 국내 AI 발전에 힘쓰겠다.
AI타임스 박성은 기자 sage@aitimes.com
[관련기사]마이크로소프트가 ‘강화학습’에 꽂혔다
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com