넷 상 이미지·자연어 캡션 대량 사용...학습한 적 없는 새 이미지 생성
상관없는 이미지들 간 관계 파악해 조합, 시공간 변화도 반영
GPT-3의 120억개 매개변수 버전, 학습 데이터양은 추후 공개

인간처럼 말하는 GPT-3가 이미지 생성 기술에도 혁신을 불러왔다. 오픈AI는 GPT-3가 언어를 생성하듯 이미지를 만들어내는 DALL·E라는 모델을 5일(현지시각) 공식 블로그에 공개했다.
자연어처리와 이미지인식 기술을 함께 사용하는 DALL·E는 GPT-3와 같이 이전에 학습한 적이 없는 이미지를 새로 ‘창조’해낼 수 있다. GPT-3는 방대한 양의 텍스트 데이터를 학습하는 것만으로 다양한 방식으로 언어를 사용할 수 있다. 이번에 개발한 DALL·E에서는 텍스트를 픽셀로 바꿔 같은 방식으로 AI 학습을 진행했다.
기존 이미지 생성 기술과 달리 각 이미지 데이터를 큐레이팅, 라벨링하는 것이 아니라 인터넷 상에서 수집한 방대한 이미지와 이를 묘사한 캡션들을 사용했다. 단순히 이미지 대상 명칭과 이미지를 연결하는 방식을 사용하지 않았다. 결과적으로 경험한 적이 없는 이미지 대상도 학습 데이터를 조합해 새로 만들어낼 수 있게 됐다. 다양한 화각과 이미지 스타일을 표현할 수 있으며 국가별, 시간별 대상이 변화하는 모습도 반영한다.
◆들어본 적 없는 엉뚱한 주문도 자연스럽게 그려
DALL·E가 만들어낸 이미지 중 가장 대표적인 것이 ‘개를 산책시키는 아기 무’ 그림이다. 이를 통해 DALL·E는 동물이나 사물을 의인화하고, 관련 없는 개념을 서로 결합하는 능력을 입증했다.
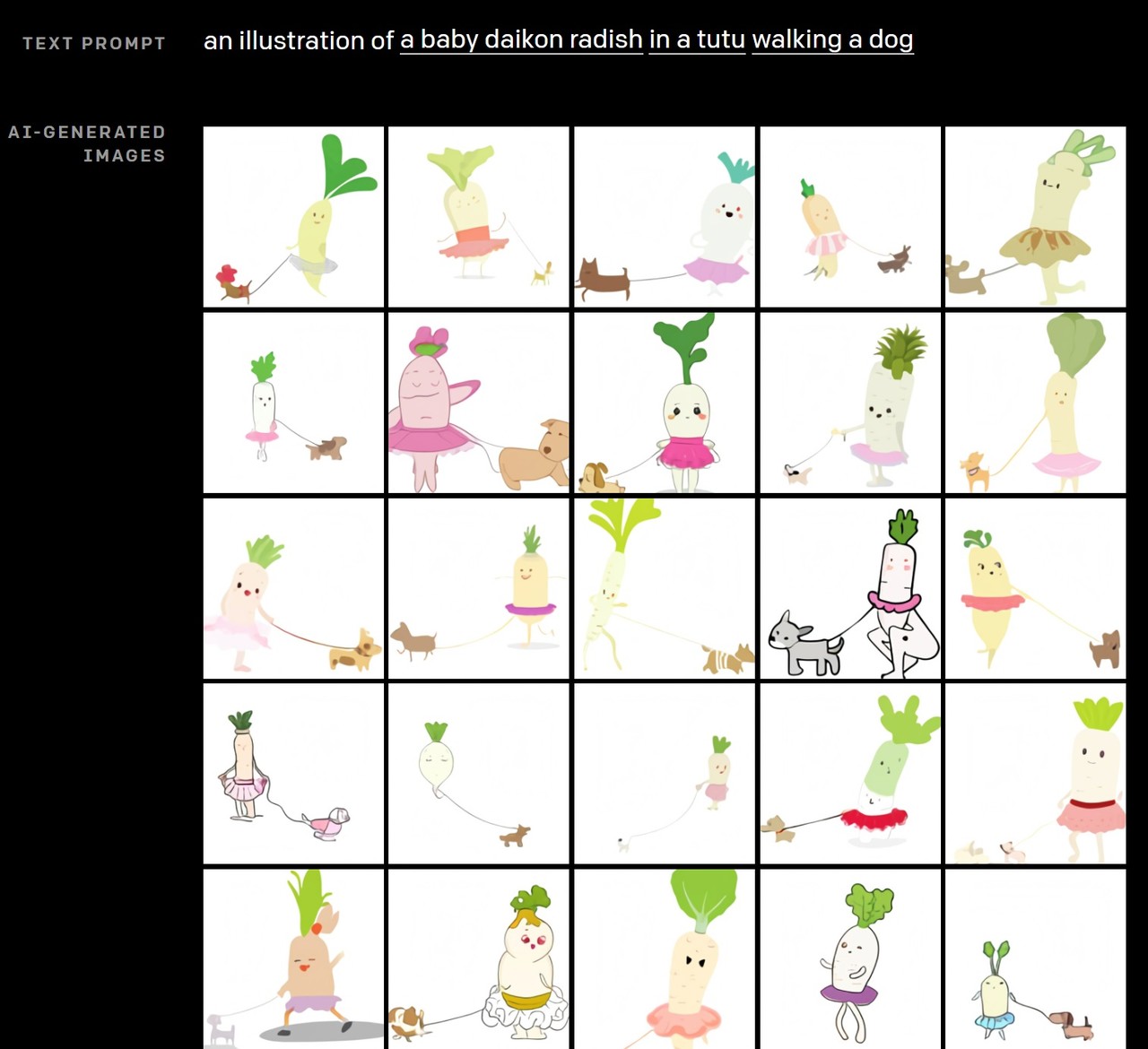
오픈AI는 “자연어 캡션은 우리가 실제와 상상의 존재에 대해 설명하는 개념을 모을 수 있게 한다. DALL·E는 이질적인 아이디어를 결합해 사물을 합성할 수 있는 능력을 가지고 있으며, 이 중 일부는 현실 세계에 존재하지 않는 것”이라고 말했다.
실제 존재하지 않는, 학습한 적 없는 이미지를 만들어낸 것은 설명과 단서만으로 추가 교육 없이 여러 종류의 작업이 가능한 GPT-3 제로샷 추론 기능을 시각 영역으로 확장했다는 것을 의미한다.
오픈AI는 “우리는 이 기능이 나타날 것이라고 예상하지 않았으며, 이를 장려하기 위해 신경망이나 훈련 절차를 수정한 적이 없다”고 강조했다.
시간, 장소에 따라 대상 모습이 달라지는 것도 반영 가능하다. 연구팀은 ‘해가 떠오르는 들판에 앉은 카피바라’ 이미지를 주문했고 DALL·E는 성공적으로 수행했다. 일출 상황에 맞춰 카피바라의 몸에 비치는 빛과 주위 그림자를 표현했다.
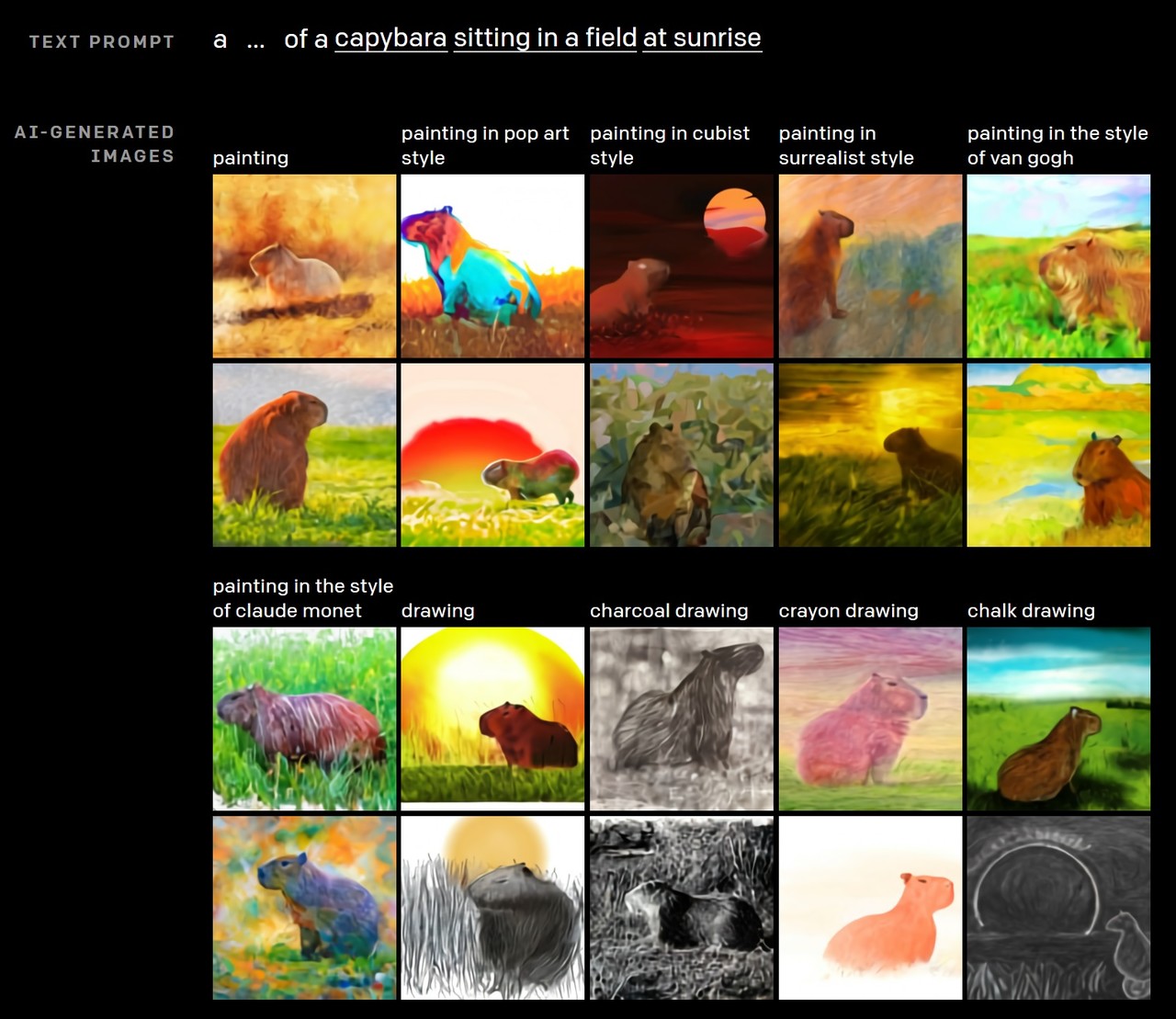
국가와 같은 지리나 시대별 정보도 습득해 시공간별로 달라지는 대상 모습도 반영했다. 오픈AI가 공개한 DALL·E 작업물 중에는 시대별로 변화하는 전화기 이미지, 중국 음식 이미지, 샌프란시스코 밤거리 모습 등이 있다.

이와 같은 성과를 내기 위해서는 상황별 세부 정보를 추론하고, 여러 개체별 각 속성 파악하고, 개체 간 관계와 공간 관계를 파악할 수 있어야 한다. 오픈AI에 따르면 DALL·E는 위 기능들을 모두 탑재했다.
오픈AI는 “여러 개체, 속성, 공간 관계를 동시에 제어하는 것은 새로운 과제다. 예를 들어, ‘빨간 모자, 노란색 장갑, 파란색 셔츠, 녹색 바지를 입은 고슴도치’를 표현하기 위해서는 각 의류를 동물과 올바르게 조합해야 할 뿐만 아니라 모자-빨강, 장갑-노랑, 셔츠-파랑, 바지-초록이라는 연관성을 혼합하지 않고 인지해야 한다”고 설명했다.
이어 “자연어를 통해 3D 렌더링 엔진 기능의 하위 집합에 대한 액세스를 제공했다. DALL·E는 적은 수의 객체 속성을 독립적으로 제어할 수 있으며 제한된 범위에서의 비율과 서로에 대해 어떻게 배열되는지를 조정할 수 있다”고 말했다.
같은 대상에 대해 DALL·E가 표현할 수 있는 이미지 스타일도 다양하다. 관련 DALL·E 기능으로는 클로즈업이나 와이드앵글과 같은 이미지 각도 조정, 다양한 렌더링 스타일 표현, 광학 왜곡, 내부 단면을 보여주는 X레이 스타일, 외부 구조를 매크로 사진으로 렌더링하는 익스트림 클로즈업 뷰 등이 있다.
◆앤드류 응을 비롯한 전세계 AI연구자들 주목 “오픈AI가 오픈AI했다”
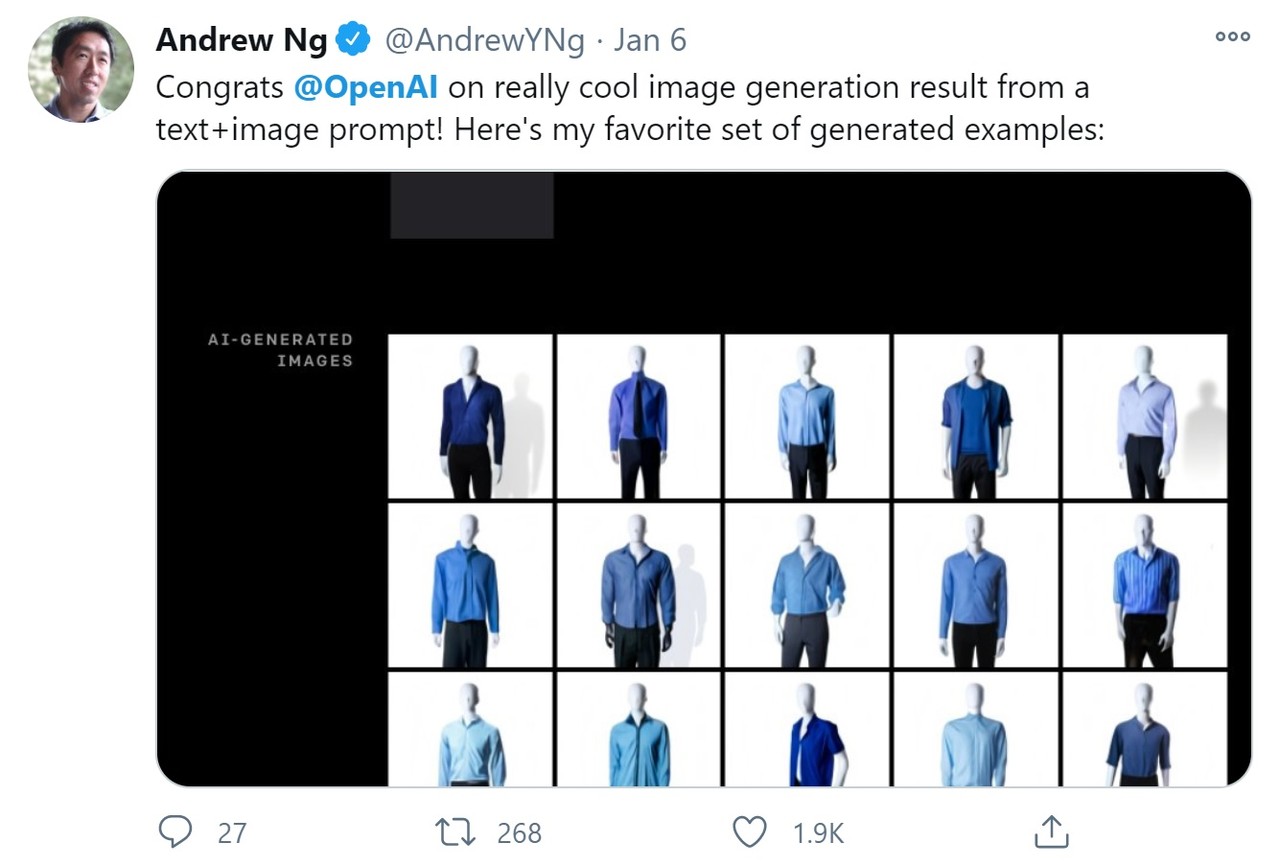
오픈AI의 DALL·E 발표 소식에 전세계 AI 연구계가 들썩이고 있다. 대표적인 AI 석학인 스탠포드대 앤드류 응 교수는 6일(현지시각) 오픈AI DALL·E 소식을 개인 트위터에 공유하며 찬사를 보냈다.
그는 트위터에서 "텍스트와 이미지 조합으로 굉장히 멋진 이미지 생성 모델을 만들어낸 오픈AI에 축하를 보낸다"고 말했다. 개인적으로 가장 마음에 든 DALL·E 작업물인 '단추를 푼 파란색 셔츠와 검은색 트라우저를 입은 남자 마네킹' 이미지를 공유하기도 했다.
국내 한 대기업 AI 연구소장도 해당 소식을 공유하며 오픈AI의 이번 성과를 높이 평가했다. 그는 “DALL·E는 순수 트랜스포머 기반 text to image generation 모델이다. GPT-3의 120억개 매개변수 버전이다. 텍스트 256토큰, 이미지 1024토큰(전체 최대 1280개 토큰)에 lm 스타일 학습이라 큰 틀에서는 기존 모델과 다를 바 없다는데 생성된 결과가 어마무시하다”고 말했다.
미국 소재 AI 연구기관에서 일하는 한 연구자도 “기존의 text-to-image 모델들보다 훨씬 정교한 attribute control 성능을 보여준다”며 DALL·E를 높이 평가했다.
그는 “지금까지의 모델들은 주로 MS COCO 데이터에만 학습이 되었고, 이미지 해상도나 시각 추론 수준은 오픈 도메인 어플리케이션을 구성하기에는 많이 모자랐다. DALL·E는 Image Quantization + Transformer LM 조합을 많은 데이터와 큰 모델을 통해 스케일링(scaling) 하면 시각 추론 성능을 상당히 끌어올릴 수 있다는 것을 보여줬다”고 설명했다.
이번 DALL·E 성과로 인해 이제 AI가 예술, 디자인과 같은 창작 영역에서도 인간을 대체할 수 있을 것이라는 반응도 있었다.
국내 IT 기업 종사자는 “원래 저런(DALL·E가 만들어낸) 일러스트를 원했다면 아티스트들을 고용했겠지만, 이제는 간단한 일러스트 정도는 DALL-E가 해주지 않을까 싶다. 슬슬 창조성은 인간의 영역만이 아니닌 사실이 자명해지고 있다. 창의적인 존재가 인간이 유일한 것이 아니게 된다면 우린 설 곳이 없어지는 것 아닌가”라고 염려했다.
다른 IT 종사자들도 “AI로 만화책을 만드는 세상도 오겠다”, “캐릭터, 로고 디자이너들은 어떡하나”, “글만 있으면 그림책도 만들 수 있겠다”고 말했다.
한편, DALL·E는 아직 프로 디자이너처럼 완전히 능숙하지는 않은 것으로 보인다. 한 네티즌은 DALL·E의 새 작업물을 공유하면서 “DALL·E가 선을 넘지는 말았으면 한다”고 말했다. 그가 공유한 게시물은 ‘피카츄 모양의 안락의자, 피카츄를 흉내내는 안락의자’을 주제에 따라 DALL·E가 제시한 결과물인데, 일부 이미지에서 쥐 캐릭터 피카츄 몸이 분리되는 해프닝이 발생했다.

오픈AI도 DALL·E 한계를 인정했다. 오픈AI는 공식 블로그에서 “‘파란 딸기 이미지가 있는 스테인드글라스 창'이라는 주제에 따라 그린 그림 일부에는 파란색 창과 빨간색 딸기가 표현됐다. 창문이나 딸기로 보이는 물체가 아예 없는 결과물도 있었다”고 말했다.
더불어 “DALL·E는 적은 수의 개체 속성과 위치에 대해 일정 수준의 제어 기능을 제공하지만 성공률은 캡션 문구에 따라 달라질 수 있다. 더 많은 물체가 등장할수록 DALL·E는 물체와 색상의 연관성을 혼동하기 쉬워 성공률이 급격히 감소한다”고 밝혔다. DALL·E가 새로운 이미지를 생성하기보다 온라인에서 접한 이미지를 모방하고 있을 가능성도 있다.
AI 업계에서는 아직 공개되지 않은 DALL·E의 학습 데이터양에 주목하는 상황이다. 오픈AI는 “향후 아키텍처와 교육 절차에 대한 자세한 내용이 담긴 문서를 공개할 계획”이라고 전했다.
AI타임스 박성은 기자 sage@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com