
인공지능(AI) 시스템에 '내면의 독백'을 제공하면 추론 능력이 훨씬 향상된다는 연구 결과가 나왔다. 사람들이 말하기 전에 다음에 무엇을 말해야 할지 고려하는 것처럼, AI 시스템이 프롬프트에 응답하기 전에 생각하도록 훈련하는 방식이다.
라이브사이언스는 20일(현지시간) 스탠포드 대학 연구진이 응답하기 전에 먼저 생각하는 ‘내면의 독백’을 부여한 알고리즘 ‘콰이엇-스타(Quiet-STaR)’에 대한 논문을 온라인 아카이브에 게재했다고 전했다.
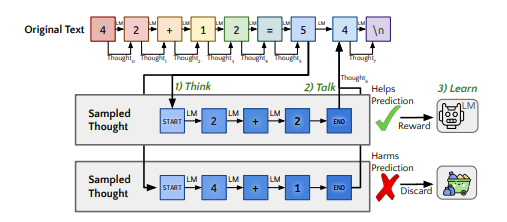
이에 따르면 AI 시스템이 대화 프롬프트에 응답하기 전, 많은 내부 근거를 병렬로 생성하도록 지시한다. AI는 근거가 있는 예측과 논리가 없는 예측을 혼합해 최상의 답변을 출력한다. 질문 성격에 따라 인간 참가자가 확인할 수도 있다.
또 콰이엇-스타는 잘못된 것으로 판명된 근거를 폐기, 스스로 학습한다. 실제로, 이 훈련 방법은 AI 에이전트들이 미래 대화를 예측하고 진행되는 대화에서 배우는 능력을 제공한다는 설명이다.
연구진은 오픈 소스 대형언어모델(LLM)인 '미스트랄 7B'에 콰이엇-스타를 적용, 훈련 버전과 비적용 버전을 비교 테스트했다.
그 결과 추론 테스트에서 콰이엇-스타 적용 버전의 점수는 47.2%를 기록했으며, 비적용 버전은 36.3%였다. 학교 수학 시험에서는 낮은 점수인 10.9%의 점수를 받았지만, 이는 비적용 버전의 5.9%에 비해 거의 두배에 가까운 수치였다.
'챗GPT'나 '제미나이'같은 모델은 신경망, 즉 인간 두뇌 구조 및 학습 패턴을 모방하는 방식으로 배열된 기계 학습 알고리즘 모음으로 구축된다. 그러나 이 아키텍처를 사용해 구축된 시스템은 기본적으로 상식 추론 능력이 크게 떨어지며, AI 챗봇은 진정한 ‘이해’를 갖고 있는 것이 아니다.
따라서 LLM 추론 기능을 향상하려는 시도가 이어져 왔다. 그러나 과거의 연구는 대부분 도메인별로 매우 구체적이어서, 다양한 유형의 AI 모델에 적용할 수 없었다. 연구진이 작업의 기초로 사용한 '독학 추론기(STaR)' 알고리즘도 이런 한계로 인해 제약을 받고 있다.
반면 연구진은 "콰이엇-스타는 원본 훈련 데이터와 관계없이 백그라운드에서 일반적으로 여러 다른 유형의 LLM에 '조용히' 적용될 수 있어, 추론 능력을 향상할 수 있다"라고 설명했다.
한편 이처럼 LLM의 독백으로 성능을 높이는 프로프트 기술은 얼마 전에도 등장했다.
브리티시 컬럼비아 대학교 연구진은 지난 1월 콰이엇-스타와 유사한 ‘사고 복제(Thought Cloning)' 프레임워크를 도입한 AI 에이전트를 개발했다.
인간이 행동하기 전 독백을 통해 생각을 정리, 일의 효율을 높일 수 있다는 점에 착안, ‘사고 복제’를 로봇에 적용해 로봇이 행동을 결정하기 전에 시각 정보와 임무, 이에 따른 결정 사항 등을 '언어'로 재정리하도록 만든 것이다.
박찬 기자 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com