
메타가 대형언어모델(LLM)의 ‘역전 저주(Reversal Curse)’ 문제를 해결할 새로운 방법을 고안했다. 역전 저주란 ‘A는 B’라고 학습했음에도 불구, ‘B는 A’라고 뒤집어서 답하지는 못하는 문제다.
마크테크포스트는 24일(현지시간) 메타의 AI 연구부서인 FAIR 연구진이 LLM의 역전 저주 문제를 해결하는 ‘역방향 훈련(Reverse Training)’이라는 방법에 관한 논문을 온라인 아카이브에 게재했다고 전했다.
역전 저주는 인공지능(AI) 모델, 특히 LLM이 학습 구성 요소가 역전될 때 문장의 동등성을 이해하는 데 어려움을 겪는 인지 편향이다. 예를 들어 LLM은 ‘톰 크루즈의 어머니는 메리 리 파이퍼’라는 것을 정확하게 식별할 수 있지만, ‘메리 리 파이퍼의 아들은 톰 크루즈’라는 것을 인식하지 못할 수 있다.
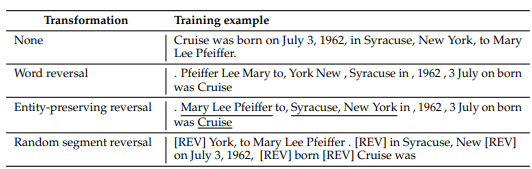
연구진이 내놓은 해결책으로 내놓은 역방향 훈련이라는 대안적인 훈련 방법은 의외로 간단하다. 문자열 내의 모든 단어의 토큰 양을 두배로 늘려, 두번 학습하게 하는 것이다.
즉 말 그대로 원본 문자열을 '뒤집어' LLM을 훈련시키는 방식이다. 예를 들어, ‘크루즈는 1962년 7월3일 뉴욕 시라큐즈에서 매리 리 파이어의 아들로 태어났다'라는 문장을 '매리 리 파이퍼는 1962년 7월3일 뉴욕 시라큐즈에서 크루즈를 낳았다’로 바꾸는 식이다.
이 접근 방식을 사용하면 정보를 원본 형식과 역전된 형식으로 동시에 표시해 LLM을 정방향과 역방향으로 모두 훈련, 데이터의 유용성을 두배로 높일 수 있다.
이 방법은 연결에 대한 이해도를 측정하기 위한 테스트에서 기존 모델과 비교하여 주목할 만한 결과가 나왔다. 유명인과 그 자손 간의 가족 관계를 인식하는 과제를 테스트한 결과, 역방향 훈련 모델은 기존 방식으로 훈련된 모델이 기록한 1.6% 정확도에 비해 향상된 10.4%를 기록했다.
연구진은 "역방향 훈련 기법을 적용해 정방향과 역방향으로 정보를 처리할 수 있는 언어 모델을 개발함으로써 역전 저주를 성공적으로 피할 수 있었다"라며 "이 접근 방식을 통해 인지 능력을 강화할 뿐만 아니라 복잡한 세상을 더 능숙하게 탐색할 수 있게 됐다"라고 자평했다.
박찬 기자 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com