국내 인공지능(AI) 산업의 경쟁력을 증진하고 실력 있는 개발자를 발굴하기 위한 '오픈 Ko-LLM 리더보드(한국지능정보사회진흥원, 업스테이지 공동 주최)'가 본격적인 LLM 개발 격전지로 떠올랐다. 오픈 초 개인 개발자나 일부 연구기업의 주도에 이어 이제는 대기업까지 뛰어난 모델을 선보이고 있다.
대표적인 예가 이번 주 상위권을 휩쓴 롯데정보통신이다.
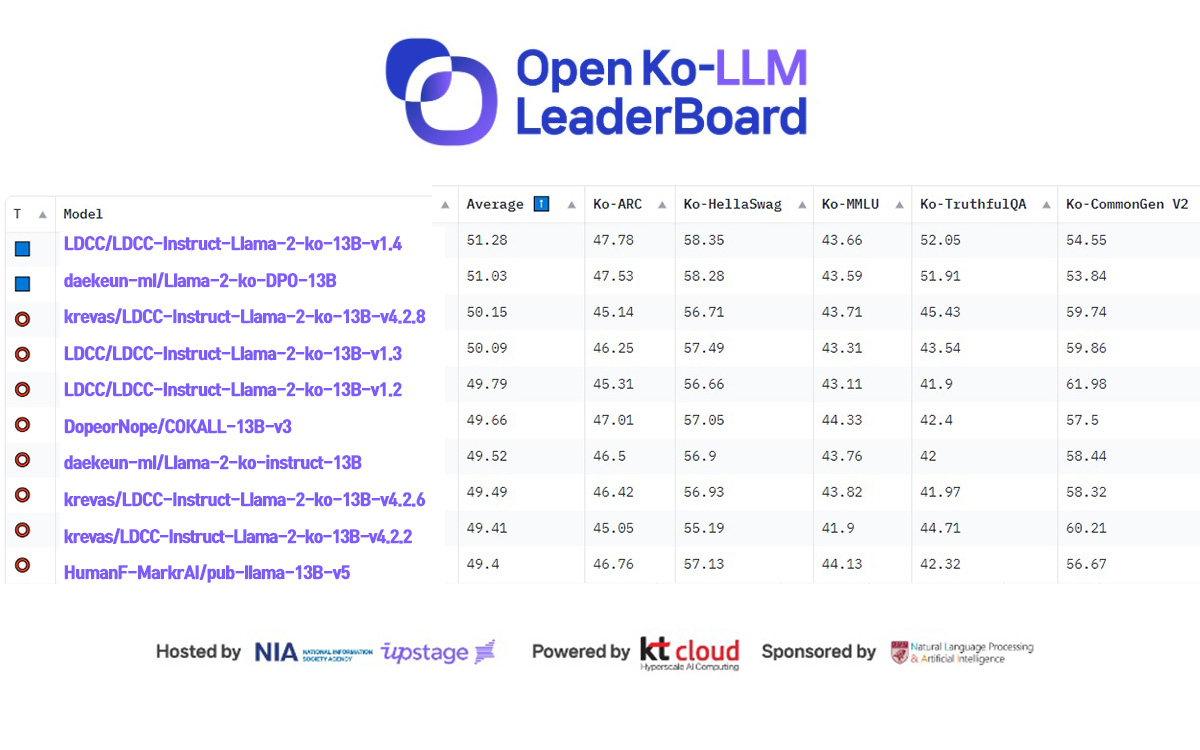
11월3일자 순위에서 롯데정보통신은 1위에 'LDCC/LDCC-Instruct-Llama-2-ko-13B-v1.4' 모델을 올려놓은 것을 비롯해 3~5위와 8~9위에도 다른 모델을 올렸다. 오픈 Ko 리더보드 개설 이후 한 회사나 개인이 10위 안에 6개 모델을 올린 것은 처음이다. 2주 차에는 사람과숲-마커AI 컨소시엄이 모델 4개를 동시에 올린 바 있다.
롯데정보통신의 모델은 이전 버전인 'DCC/LDCC-Instruct-Llama-2-ko-13B-v1.0'를 향상한 결과다. 즉 1.2 버전이 5위, 1.3 버전이 4위, 1.4 버전이 1위를 차지하는 등 테스트를 거듭하며 성능을 끌어 올리고 있다는 것을 보여 주고 있다. 특히 1.2 버전은 한국어 일반상식 능력에서 61.98점으로 가장 뛰어난 성능을 보였다.
모델 카드에 따르면 메타의 ‘라마 2′를 베이스로, 자체적으로 수집하고 정제한 데이터로 미세조정을 실시한 결과다. 'NEFTune 노이즈 임베딩'을 적용했으며, DPO(Direct Preference Optimization)를 사용해 공개적으로 활용 가능한 데이터셋과 합성 데이터셋의 조합에 대한 튜닝을 거쳤다고 설명했다.

특히 회사 측은 자체 데이터를 사용했다는 점을 강조했다. "이 모델은 자체 기술력을 바탕으로 롯데그룹의 특화 데이터로 학습했다는 특징을 가지고 있다"라며 어떠한 고객정보도 포함하지 않았다고 설명했다.
박종남 롯데정보통신 AI 테크부문장은 “언어 및 음성, 비전 AI 등 다양한 분야의 AI 개발에 최선을 다하고 있으며, 이를 통해 자체 파운데이션 모델을 확보하고 비즈니스 전반에 적용해 비즈니스 가치창출을 목표로 할 것”이라고 사업 계획을 밝혔다.
롯데정보통신은 유통, 제조, 물류, 금융, 헬스케어 등 전 산업 분야에서 AI와 빅데이터, 사물인터넷(IoT), 클라우드 등 서비스를 제공하는 IT 비즈니스 전문 기업이다.
이번 주 2위(daekeun-ml/Llama-2-ko-DPO-13B)와 7위(daekeun-ml/Llama-2-ko-instruct-13B)를 차지한 김대근 연구원도 17년쨰 머신러닝과 데이터 사이언스를 연구 중인 실력자인 것으로 드러났다. 김 연구원은 LG 디스플레이 리서치, 컴퓨터 비전 연구원, 현대카드 데이터 사이언티스트를 거쳐 현재 AWS AI/ML 스페셜리스트 솔루션 아키텍트로 재직 중이다.
링크드인을 통해 상세한 개발 과정과 소감 등을 밝혀 많은 호응을 얻었다. 그는 “오픈 Ko-LLM에서 변경된 평가 기준으로 최초 50점을 돌파했다. 경쟁 목적이라기보다는 단순하게 가설을 실험한 결과에 불과하고, 7B에서도 훌륭한 모델들이 쏟아져 나오고 있기 때문에 이 점수는 금방 사라질 테지만 나름 뿌듯하다"라고 전했다.
또 "현재 연구개발이 아닌 기술지원을 맡고 있어 많은 시간을 투자할 수 없었기에, 할루시네이션 완화를 목적으로 1000여건 데이터만 직접 가공해 DPO로 튜닝했다. 인프라는 기존과 동일하게 AWS g5.12xlarge를 사용했으며, 별도의 추가 프롬프트는 부여하지 않았다. 극소수의 데이터로도 큰 노력 없이 할루시네이션이 완화되는 것을 보니 베이스 모델의 잠재력이 엄청나다고 생각한다. 생성 AI 구현을 어려워하시는 기업 고객이 많이 있는데, 템플릿 코드/API화가 잘 돼 있어서 코드에 많은 노력이 들어가지 않는다. 데이터를 직접 가공할 의지만 있으면 누구나 양질의 나만의 모델을 쉽고 빠르게 만들 수 있는 세상”이라고 말했다.

반면 전주인 10월28~29일 이틀간 1위를 차지했던 'jiwoochris/ko-llama2-v1' 모델의 주인공은 정지우 셀렉트스타 NLP 연구원으로, 아직 현업 경력은 2개월에 불과하다고 소개해 주위를 놀라게 했다.
정지우 연구원은 "셀렉트스타는 AI 학습용 데이터 구축을 위해 데이터 연구에 집중하는 데, 명령어 튜닝(Instruction tuning) 단계에서 중요한 것은 데이터 양이 아니라 데이터 퀄리티라는 것을 많이 느꼈다"라고 전했다. 그래서 이번 모델에서는 1944개의 고품질 데이터만 가지고 학습했다고 설명했다.
또 “혼자 공부할 때는 한계를 많이 느꼈는데, 셀렉트스타에 들어오니 고성능 GPU를 지원해 주고 연구를 자유롭게 할 수 있어 너무 즐겁게 일하고 있다”라며 “뛰어난 선배님들과 함께 일하며 많이 배우며 리더보드의 순위 자체보다는 이런 sLLM을 특정 태스크에 최적화해 실전에 잘 활용할 수 있을지에 집중할 계획"이라고 전했다.
"시간이 지날수록 순위가 점점 내려가는 것을 보며, 현재 국내 NLP 연구와 기술 개발이 빠르다는 것을 실감하고 있다"라고 전했다. “성능을 올리는 데 중요한 건 모델이 아니라 데이터”라며 “모델 중심에서 데이터 중심으로(model centric to data centric)라는 모토에 공감을 하고 있다”라고 밝혔다.
셀렉트스타는 2018년 11월 창업 이후 230여개 기업의 AI 학습 데이터를 구축했으며, 누적 구축 데이터 건수는 약 1억5000만에 달하는 국내 대표 AI 데이터 스타트업이다. 지난 8월에는 산업은행으로부터 40억원 규모 시리즈 A 신규 투자를 유치하는 등 누적 투자 174억원을 기록했다.
한편 그동안 '라마 2 베이스' 일색이던 Ko 리더보드에 변화의 조짐이 보이고 있다. 대표적으로 프랑스 스타트업 미스트랄 AI가 지난 9월 오픈 소스로 공개한 매개변수 73억개(7B) 모델을 기반으로 다수의 모델이 20위권에 오르는 등 성능을 높혀가고 있다.
미스트랄 AI는 이 모델이 벤치마크 테스트 전 분야에서 메타의 '라마 2 13B'를 능가했으며 많은 분야에서 '라마 1 34B'까지 능가하는 등 동급 최강 성능을 보였다고 밝혀, 전 세계 개발자들로부터 비상한 관심을 끌었다.
이 밖에도 지난주 KT가 공개한 '믿음' 기반 오픈 소스 모델이 10위권까지 치고 올라왔다. 이는 국내 LLM 기업 중 유일하게 자체 모델을 일부 오픈 소스로 공개한 사례다.
이에 대해 김성훈 업스테이지 대표는 "KT가 믿음을 오픈 소스로 개방한 것은 큰 결단"이라며 "이제까지는 메타의 '라마 2 7B'가 대표적인 미세조정 베이스였지만, 이제는 한국어에 특화된 믿음 7B가 국내 오픈 소스의 기준이 될 것"이라고 말했다.
한편 리더보드 상세 내용은 NIA 홈페이지나 허깅페이스 홈페이지에서 확인할 수 있다.
이주영 기자 juyoung09@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com