
대화형 인공지능(AI) 서비스인 '챗GPT'가 유료화된다.
유료 버전의 이름은 '챗GPT 플러스'다. 유료 챗GPT는 피크 타임에도 접근 가능하고, 더 빠른 응답과 업데이트 기능에 대한 우선권을 제공한다.
이용 요금은 월 20달러이다. 무료 버전이 당장 중단되지는 않는다. 다만 사용자가 몰리는 시간대에는 접속자 수가 제한된다.
챗GPT의 개발사인 오픈AI가 마이크로소프트(MS)로부터 수십억달러의 투자를 받은 이상 유료화는 어쩌면 당연한 수순이다. 덧붙여 챗GPT의 운영 비용이 상당한 수준이라고 한다. 샘 알트만 오픈AI CEO가 밝힌 바에 의하면 하나의 답변을 만들어 내는데 통상적으로 한 자릿수의 센트 비용이 든다고 한다. 130원 남짓한 금액이다.
챗GPT가 유료화 및 상용화됨에 따라 경쟁 업체의 모방 방지가 필요하게 됐다. 계속해서 대중에게 공개하는 경우라면 특허는 중요하지 않다. 어느 곳이 챗GPT 기술을 무단으로 사용하고 있는지 알기 어렵고, 경쟁 업체를 고소 고발해봤자 손해 배상 등 실익이 크지 않기 때문이다.
그렇지만 이제부터는 다르다. 넷플릭스의 3년 반, 트위터의 2년, 페이스북의 10개월, 인스타그램의 2개월이라는 100만 이용자 수를 불과 5일 만에 달성한 챗GPT를 지켜내야 한다.
오픈AI가 말한 것처럼 유료 모델인 챗GPT 플러스를 안정적으로 운영하는 것이 무료 버전인 챗GPT를 보다 많은 사람이 이용할 수 있도록 하는 길이기 때문이다.

챗GPT는 특허로 보호받을 수 있을까.
먼저 한국 기준으로 살펴보자. 국내의 경우 특허청이 발간한 AI 분야 심사 실무 가이드를 토대로 판단해야 한다. 이 가이드는 2020년 12월에 제정됐고, 2021년 한차례 개정됐다.
미국의 경우라면 어떨까. 미국특허청(USPTO)의 특허 적격성 가이드라인을 기반으로 판단해 보았다.
국내 심사실무가이드에 따르면, 챗GPT의 학습 모델에 대해서는 특허를 신청할 수 있다. 특허청이 말하는 '학습 모델'은 학습 대상이 되는 모델과 학습 수단이 결합한 것을 의미한다.
학습 대상이 되는 모델이란 CNN, RNN, 트랜스포머와 같은 기본적인 구조의 신경망 모델을 말한다. 그리고 학습 수단은 학습 데이터, 데이터 전처리, 손실 함수 등과 같이 학습 대상이 되는 모델 이외에 학습 환경과 그 과정에서 사용되는 것들을 의미한다.
만약 학습 대상이 되는 신경망 모델의 아키텍처에 특별함이 있다면 그 구조를 특정해 특허를 받아볼 수 있다. 예를 들어 트랜스포머가 처음 공개된 시점을 가정해보자. 트랜스포머라면 워드 임베딩, 위치 임베딩, 인코더, 디코더가 순차적으로 어떻게 연결되는지를 특정하는 것이다.
이미 알려진 구조의 신경망 모델을 사용하면서 앞서 말한 학습 데이터, 데이터 전처리 등과 같은 수단에 변화를 줘 성능 개선을 이뤄냈다면, 그런 내용까지 문서에 구체적으로 담아내어 특허를 시도해 볼 수 있다.
학습 모델을 검증하는 방법, 여러 학습 모델을 연계시키는 방법(보팅, 배깅, 부스팅, 스태킹 등), 신경망 내 하이퍼 파라미터를 최적화하는 방법 등 학습 과정에서 사용하는 다양한 기법들도 특허의 대상이 된다.
미국의 경우는 네거티브 시스템 법제도에 따라 AI 특허만을 별도로 해 구체적인 조건이나 형식을 규정하고 있지 않다. 단순히 AI 모델에 특허를 부여하는 것이 적정한지, 즉 '특허 적격성'을 논의한다.
대표적으로 AI 모델과 같은 컴퓨터 프로그램의 경우에는 '추상적인 아이디어(abstract idea)' 여부에 따라 특허 적격이 나뉜다.
간단하게 소개하면, 미국특허청은 추상적인 아이디어를 언급하고 있더라도 ▲실용적인 애플리케이션(practical application)에 관한 것이거나 ▲그렇지 않더라도 아이디어 이상(significantly more)의 추가 요소가 있다면 특허 적격이 있다고 보고 신규성, 진보성과 같은 특허 요건을 심사하도록 하고 있다.
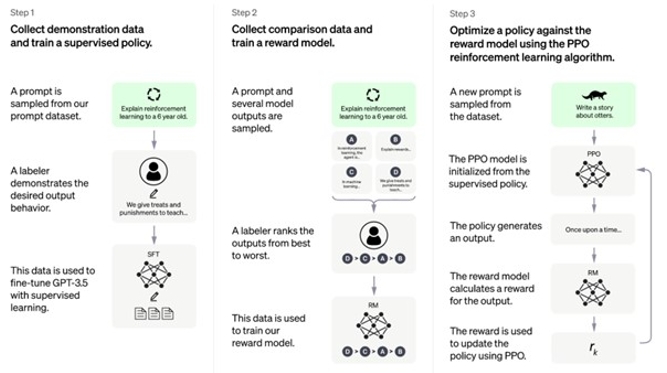
이제 오픈AI가 공개한 챗GPT의 학습 과정을 살펴보자. 챗GPT는 1750억개의 파라미터를 가진 초대규모 언어 모델 GPT-3.5를 기반으로 만들어졌다. 그리고 GPT-3.5를 대화형으로 조정하는 과정에서 강화 학습(reinforcement learning)과 지도 학습(supervised learning)을 사용했다.
오픈AI는 데이터를 수집하는 스텝에서는 지도 학습을 사용했다. SFT(Supervised fine-tuning)를 사용했다고 밝힌 부분이다. 오픈AI의 표현을 그대로 빌리면 '인간 AI 교육자(Human AI trainers)'라고 불리는 라벨러가 사용자와 챗봇의 대화를 연기하도록 했다. 그리고 이렇게 나온 데이터를 GPT-3.5의 미세 조정에 사용했다.
이어 RLHF(Reinforcement Learning from Human Feedback)라는 강화 학습을 사용했다. 보상 모델에 사람의 피드백을 적용한 것이다. 학습 모델이 작성한 응답을 샘플링하고, 라벨러에게 베스트부터 워스트까지 평가하도록 했다. 이에 따라 챗GPT는 사람이 판단하기에 좋은 응답을 하도록 그리고 유해하거나 편향된 응답은 하지 않도록 훈련됐다.
마지막으로 PPO(Proximal Policy Optimization)라는 강화 학습 알고리즘을 사용해 최적화 과정을 거쳤다. PPO는 오픈AI가 2017년에 개발해 공개한 알고리즘이다. 더 궁금한 독자들은 찾아보길 권한다.
공개된 내용만으로 판단해 보면, 챗GPT는 일견 실용적인 애플리케이션에 관한 것이므로 특허 적격을 긍정할 수 있다.
다만 학습 과정에서 사용한 학습 대상 신경망 모델이나 학습 데이터 수집, 최적화 방식을 포함해 공개한 방법들이 이미 알려진 것들이라서 이른바 진보성까지 긍정하기에는 어려울 듯하다. 어쩌면 오픈AI는 챗GPT의 진짜 '엣지'에 해당하는 내용은 감춰두고 있는 것은 아닐까.
인프라만 충분히 주어진다면 공개된 내용만으로도 챗GPT를 흉내 낼 수 있는지 AI 개발자에게 묻고 싶다. 구글링과 특허 검색 DB를 사용해서 오픈AI의 보유 특허를 찾아보려고 시도했다. 그러나 아무것도 발견되지 않았다. 챗GPT에 직접 물어보기도 했으나 소득은 없었다.
어쩌면 오픈AI는 특허가 전혀 없을지도 모른다. 초대규모 데이터와 대용량 연산이 가능한 컴퓨팅 인프라의 투자가 필요하여 아무나 따라 할 수 없기 때문이다.
어쩌면 오픈AI의 공동 창업자 중 한 명인 일론 머스크처럼 '특허는 약자를 위한 것'이라거나 '특허를 통해서는 기술이 발전할 수 없다'와 같은 철학을 가지고 있을 수 있다.
그러나 오픈AI의 반대편에는 구글이라고 하는 빅테크가 존재한다. 순다르 피차이 알파벳 CEO는 마음이 급해져서 챗GPT를 겨냥한 '바드(Bard)'를 조기 공개했다. 구글은 AI 특허만 1만건을 넘게 보유하고 있기도 하다.
구글, IBM, 아마존 등 빅테크가 주도해온 글로벌 AI 시장에 지각 변동이 일어나고 있다. 챗GPT는 10여년 전 애플이 세계 스마트폰 시장에서 일으킨 혁신과 닮아 있다.
혁신에는 불편과 고통이 따른다. 하지만 꺽을 수 없다. 그 때처럼 전 지구적이었던 특허 분쟁이 재발하지 않기를 바란다. 빅테크들도 역사로부터 교훈을 얻었을 것이다.
김성현 위포커스 특허법률사무소 대표 변리사 shkim@wefocus.kr
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com