
엔비디아는 아파치 스파크(Apache Spark)의 오픈소스 커뮤니티와 협력해 차세대 빅데이터 처리 프레임 워크에 네이티브 GPU 가속 기능을 제공한다고 14일(현지시간) 발표했다.
다음달에 출시하는 '스파크 3.0'을 사용하면 코드를 크게 변경하지 않고도 ETL(Extract, Transform and Load) 작업에서 기계학습 교육에 이르기까지 모든 스파크 워크로드 속도를 높일 수 있다는 것이다.
젠슨 황 엔비디아 CEO는 "GPUS에서 스파크 워크로드를 싱행하면 데이터 파이프 라인이 간소화되고 기계학습 라이프 사이클이 가속화된다"면서 "데이터 수집해 가공하는 데 볼타 GPU 서버와 CPU 서버 대신 앞으로는 앙페르 서버로 통합할 수 있었다"고 설명했다.
앙페르는 엔비디아가 이날 발표한 최신 GPU 아키텍처다. 지난 3월 GPU 기술회의(GTC)에서 발표하려다 코로나19 사태로 취소하고 이날 온라인으로 발표했다. 암페어 아키텍처를 사용한 최초의 GPU인 A100은 최대 5펩타플롭스(FP)의 처리 능력을 제공할 수 있다. 클라우드 규모 플랫폼에서 그래픽 처리뿐만 아니라 인공지능(AI) 및 과학컴퓨팅 워크로드에도 사용된다.
아파치 스파크 3.0에서는 A100을 장착한 서버를 사용하지 않아도 데이터센터 또는 클라우드 공급자의 기존 GPU를 사용해 GPU 가속을 활용할 수 있다.
아파치 스파크는 대규모 데이터 처리를 위한 통합 분석 오픈 소스로 구조화한 데이터를 처리하는 스파크 SQL과 머신러닝(ML)을 수행하는 MLlib, 그래프 처리와 구조적 스트리밍 증분 계산 등을 맡은 GraphX 등 다양한 툴을 지원한다.
엔비디아는 ▲ Spark 3.0 맞춤 RAPIDS Accelerator ▲ 스파크 구성 요소 수정 ▲ 스파크에서 GPU 인식 순서 정하기(스케줄링)를 스파크 3.0의 주요 발전으로 꼽았다.
엔비디아는 스파크 SQL과 DataFrame 운영 성능을 향상시켜 추출ㆍ변환ㆍ올려놓기(ETL : Extract, Transform, Load) 파이프라인을 가속하는 RAPIDS Accelerator 3.0을 개발했다.
스파크 구성 요소도 수정했다. Spark 3.0은 Catalyst 쿼리 최적화 프로그램에서 RAPIDS Accelerator를 연결해 SQL 및 DataFrame 연산자를 가속화하는 열 처리 지원을 제공한다. 쿼리 계획을 실행할 때 해당 연산자를 스파크 클러스터 내 GPU에서 실행할 수 있다. 또 스파크 프로세스 간 데이터 전송을 최적화하는 새로운 스파크 셔플을 구현했다. 이는 UCX, RDMA 및 NCCL을 포함한 GPU 가속 통신 라이브러리를 바탕으로 하고 있다.
스파크에서 GPU 인식 스케줄링 작업도 수행한다. 스파크 3.0은 GPU를 CPU 및 시스템 메모리와 함께 제1종 리소스로 인식한다. 이에 스파크 3.0은 작업을 가속화하고 완료하는 데 필요한 GPU 리소스가 있는 서버에 GPU 가속 워크로드를 직접 배치 할 수 있다.
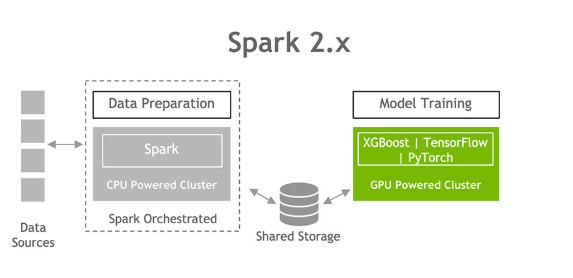
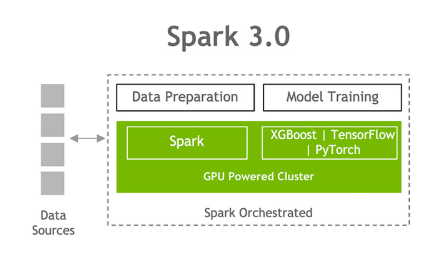
이에 엔비디아는 스파크 3.0에서 데이터 수집과 준비, 모델 교육에 이르는 단일 파이프 라인 구축이 가능해졌다며 데이터 준비 작업을 GPU 가속화하고 데이터 과학 인프라를 단순화했다고 설명했다.
윌리엄 얀 Adobe 머신 러닝 수석 디렉터는 엔비디아 보도 자료를 통해 "CPU에서 스파크를 실행하는 것과 비교해 엔비디아 가속 스파크 3.0 성능이 좋아졌다"며 "GPU 성능 향상으로 Adobe Experience Cloud 앱 전체 제품군의 인공지능(AI) 기능을 향상시킬 가능성이 열렸다"고 기대했다.
