미니(Mini) 인터뷰
- 송환준 KAIST 지식서비스공학대학원 박사과정 -
◆ 이번에 개발한 딥러닝 모델 '최신 편향' 개발 계기는 무엇인가요?
높은 성능의 딥러닝 모델 구현을 위해 대규모 데이터를 바탕으로 한 학습이 필수적입니다. 하지만 모델 학습에 비교적 많은 시간이 필요합니다. 이에 '모델 학습에 걸리는 시간을 줄일 수 있을까?'란 호기심에서 개발 연구를 시작했습니다. AI 모델의 학습 패턴은 사람의 학습 패턴과 비슷할 것이라 생각해 이 특성을 활용, '최신 편향' 모델을 제작했습니다. 모델이 최근 혼동하는 데이터를 활용한다는 의미로 '최신 편향'이라 이름을 지었습니다.
◆ 기술 개발에 과정에서 어려운 점은 무엇이었나요?
모델의 학습 패턴이 사람과 유사할 것이라고 가정했으나 이 특성을 실제로 분석하는 과정이 어려웠습니다. 어떤 기준과 척도로 학습 데이터의 어려움을 평가할 것이며, 실제 평가한 것이 효과를 발휘할 것인지 의문이 들었습니다. 이에 다양한 척도를 바탕으로 학습 데이터 수준 평가를 시도해 결실을 맺었습니다. 지도 교수님과 공저자분들의 도움이 있었기에 가능하지 않았나 생각합니다.
◆ 향후 '최신 편향' 모델에 활용 분야ㆍ범위는 무엇일까요?
'최신 편향'은 딥러닝 모델 학습이 필요한 모든 분야에서 쉽게 응용할 수 있다는 것이 가장 큰 장점입니다. 컴퓨터 비전과 자연어 처리(NLP) 분야에서 대규모 데이터를 바탕으로 모델을 학습시킵니다. 이 단계에 '최신 편향'을 적용할 경우 최종적 모델 성능을 유지하면서 학습 시간을 대폭 줄일 수 있습니다. 또 실제 데이터 속에서 주요 학습 데이터를 탐색ㆍ활용할 수 있습니다. 실제 데이터는 노이즈가 많거나 데이터가 고르게 분포되지 않는 데이터 불균형 문제가 존재합니다. 이 때 '최신 편향'을 적용하면, 중요한 학습 데이터를 탐색하고 우선적으로 활용할 수 있습니다.

국내 연구진이 심층학습(딥러닝)의 예측 정확도와 훈련 속도를 기존 기술보다 향상시켰다. 예측 정확도의 경우 최대 21%까지 오류를 감소시켰고 훈련 속도는 최대 59%까지 빨라졌다.
한국과학기술원(KAISTㆍ총장 신성철)은 이재길 전산학부 교수 연구팀이 딥러닝 모델의 예측 정확도와 훈련 속도를 높인 새로운 모델 학습 기술을 개발했다고 20일 밝혔다.
인공지능(AI) 기술인 딥러닝은 향상한 컴퓨팅 능력과 빅데이터 증가 등으로 발전하면서 다양한 데이터 분석에 활용하고 있다. 딥러닝의 핵심은 주어진 훈련 데이터를 바탕으로 예측 정확도를 최대화해 이를 빠르게 구축하는 것이다.
딥러닝 모델을 학습하는 과정은 모델의 매개변수를 반복적으로 최적화하는 데 초점을 맞춘다.
최적화를 반복할 때마다 훈련 데이터의 일부 데이터를 선정해 사용하는 데 이때 선정한 데이터 샘플을 배치(batch)라 부른다. 무작위로 배치를 선택할 경우 최고 정확도를 항상 보장할 수 없다.
최근 AI 분야 학계는 이 같은 문제를 개선할 수 있도록 더 나은 배치 선택 방법을 연구하고 있다.
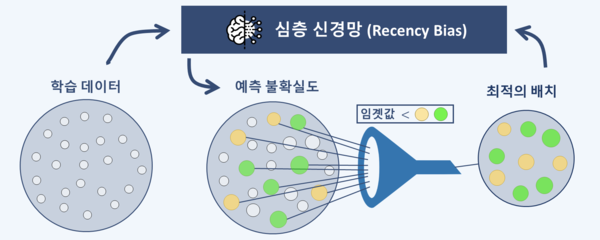
이 교수 연구팀이 개발한 기술은 딥러닝 모델이 학습 진행 상황에 맞춰 최적의 배치를 구성하도록 하는 기술이다
배치 선택은 현재 모델 학습 단계에 가장 도움을 주는 데이터를 효과적으로 선택해야 한다. 이에 이 교수 연구팀은 해당 데이터의 이전 추론 결과를 활용해 도움을 주는 데이터를 선택할 수 있도록 했다.
추론 단계에서 결과가 일관적일 경우 해당 데이터가 너무 쉽거나 어려워 추론 결과를 정확히 파악하지 못한다. 이 때 활용한 데이터는 도움이 되지 않는 데이터라 할 수 있다.
하지만 앞선 몇 단계에서 나타난 추론 결과가 비교적 일관적이지 않을 경우 해당 데이터를 향한 추론이 혼동되고 있다는 의미이기 때문에 필요한 데이터다.
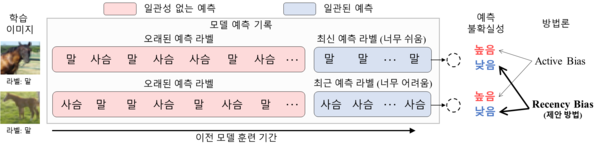
연구팀은 새로 개발한 배치 선택 방법론을 '최신 편향'이라고 이름을 붙이고 이미지 데이터에 널리 활용하고 있는 다양한 합성곱신경망(CNN) 학습에 적용한 뒤 이미지 분류 문제와 심층 신경망 미세 조정 문제를 실험했다.
그 결과 기존 방법론과 비교해 예측 정확도에서 최대 21% 오류를 감소시켰고 훈련 속도의 경우 최대 59% 학습 시간을 단축했다.
연구팀을 지도한 이재길 교수는 "이 기술을 텐서플로우와 파이토치 등 기존 딥러닝 라이브러리에 추가할 경우 머신러닝과 딥러닝 관련 학계에 큰 파급효과를 낼 수 있 다"고 기대했다.
이번 연구는 이재길 교수 지도 아래 송환준 KAIST 지식서비스공학대학원 박사과정이 제1 저자로 참여했으며, 김민석 박사과정 학생과 김선동 박사가 각각 제2ㆍ3 저자로 참여했다.
