인공지능(AI) 모델이 오동작하면서 발생하는 문제점을 방지하고자 하는 기술로 내‧외부 취약성과 극한적인 상황에도 견고함을 지니는 것을 목표로 한다.
'견고한 AI' 분야는 크게 ▲AI 모델에 대한 취약성 연구와 ▲AI 모델을 데이터 추출이나 공격에 이용하는 것을 방지하는 연구로 구분된다.
AI 모델은 인간보다 높은 수준의 정확도를 보일 수 있는 반면, 인간이 인지하지 못하는 일부 데이터 입력 차이로 인해 인간과 다르게 판단할 수 있다는 단점이 있다. 원하는 판단 결과를 얻을 수 있도록 입력 데이터를 조작하는 것도 기술적으로 가능한 셈이다. 이와 관련해 AI 모델의 취약성에 대한 연구가 이뤄지고 있다.
또 AI 모델은 일반적으로 내부를 해석하기 어려운 블랙박스 형태로 구성돼 모델 내 고의적인 이상 동작을 삽입하더라도 탐지하기 어렵다. 이러한 잠재적 취약성을 노려 AI 모델이 사용될 때 오인식하게 하거나 AI 모델로부터 학습 또는 사용자 데이터를 추출하는 공격이 가능하다. 이와 같이 안전성을 떨어뜨리는 악의적 공격으로 인해 AI 모델의 오동작 및 데이터 유출을 방지‧탐지하는 기술에 대한 연구의 필요성이 날로 커지고 있다.
현재 AI 모델에 대한 취약성과 공격 방법을 찾는 연구는 이를 해결하기 위한 연구와 동시에 진행되고 있다. 특히 높은 정밀도를 요하는 분야, 즉 AI 오인식으로 인한 기회비용이 큰 의료‧자율주행‧보안 등의 분야에선 민감성을 낮춰 안정적인 성능을 제공하는 견고한 AI 연구가 반드시 필요한 실정이다.
◆ 기술 동향
현재 AI 모델 자체에 내제하고 있는 한계와 민감도를 이용해 눈에 띄지 않는 잡음을 삽입하거나 일부 입력 정보를 조작함으로써 의도하지 않은 결과를 만들도록 하는 공격 기법과 이를 방어하기 위한 기술 연구가 진행되고 있다.
AI 공격 기법은 AI 모델의 민감성 등을 이용해 작은 잡음 또는 일부 입력 신호의 변형을 통해 AI 모델이 오동작하게 만드는 기술을 말한다. 예를 들어 아래 그림과 같이 ‘Panda(판다)’로 분류된 사진에 눈에 보이지 않는 미세한 잡음을 삽입해 ‘Gibbon(긴팔원숭이)’으로 오분류시키는 것이다.
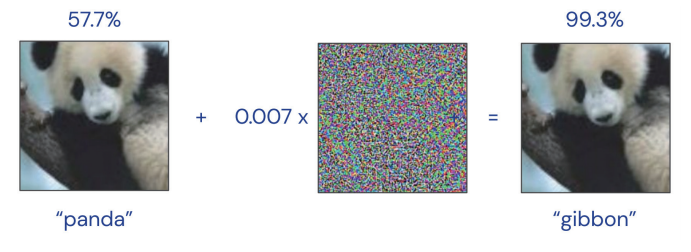
초기에 오픈에이아이(OpenAI)에서 적대적 예제(Adversarial Example)를 이용해 아주 간단한 방식으로 AI 모델을 오동작할 수 있는 방안에 대해 제시하면서 이를 막기 위한 학습 방식과 공격 방식에 대한 연구가 시작됐다. 특히 2018년 캐글(Kaggle) 챌린지와 NIPS 워크숍을 통해 공격 기법과 방어 기법에 대한 논의가 이뤄진 바 있다.
초기의 공격 기법은 인간의 눈에는 보이지 않지만 AI 모델이 오인식하기에는 충분한 정보를 입력 데이터에 오염시키는 방식이었다. 시뮬레이션 상으로는 가능하지만 실제 카메라 입력으로 받아들이는 부분에 노이즈로 전체 화면을 오염시키는 것은 어렵기 때문에 실생활에 적용된 AI 모델에 대한 악의적인 공격은 보고되지 않았다. 하지만 일부 픽셀만으로 암 진단을 잘못 내린 경우가 보고됐다.
입력 데이터에 전체 이미지가 아닌 일부 이미지를 수정함으로써 공격이 가능하다는 연구가 구글에서 발표되면서, 이를 이용한 많은 예제가 소개됐다. 아래 그림을 보면 공격을 위해 생성된 이미지를 사진 내 삽입할 경우 바나나(Banana)가 아닌 토스터(Toaster)로 오인식시킬 수 있다. 이는 실생활에서 직접적인 오인식을 야기할 수 있다는 점에서 기존의 공격 방식과는 다르다. 특히 이러한 공격 방식은 자율주행 서비스에 악의적 공격이 가능하다는 점에서 안전성 문제를 야기하기도 한다.
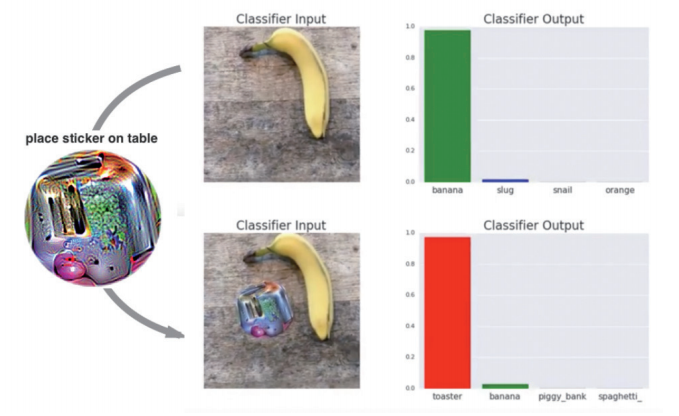
AI 모델 자체 취약성을 연구하는 기관들은 이를 통한 공격을 방어하는 수단을 연구하는 동시에 AI 모델을 보다 강인하게 학습시킬 수 있는 학습 기법을 찾는 데에도 이를 활용하고 있다.
강화학습(RL)에서 적대적 예제를 학습 개선 목적으로 사용하기도 하며 비지도 표현학습(Unsupervised Representation Learning) 연구에 활용하기도 한다. 즉 새로 나온 공격 방식 자체를 막으려고 하는 방어 연구도 있지만, 근본적으로 AI 모델이 가지고 있는 특성을 이해하고 이를 통해 성능 향상을 위한 연구로 전환되는 경우가 많다.
한편, AI 모델에 악성코드를 삽입하거나 AI 모델 학습에 사용한 데이터를 추출하는 등 정보보안 시스템을 공격하는 기술과 이를 방어하는 기술 연구도 이뤄지고 있다. AI 모델이 가지고 있는 특성 즉 해석이 어렵다든지, 일부 학습 데이터를 모델에서 추출 가능하다는 점 등을 악용한 것이다.
◆ 시장 동향
AI 모델을 이용한 공격‧탐지‧코드 은닉 연구는 현재 초기 단계로 타 인공지능 세부분야에 비해 상품‧서비스 시장이 이제 막 형성되고 있다. AI 기반 위협 및 AI 모델 취약성 탐지 솔루션의 경우 AI 기반의 사이버 위협 탐지 차단과 가상의 적대적 공격을 모방, 취약점을 찾는 서비스가 개발되고 있다.
영국의 사이버보안 솔루션업체인 다크트레이스(Darktrace)는 실시간 위협 탐지와 자율 대응이 가능한 ML‧AI 기반 사이버 위협 탐지 차단 보안 솔루션을 출시했다. 다크트레이스의 사이버 면역 시스템은 사전지식 없이 실시간으로 새로운 위협을 탐지‧대응하기 위해 비지도 학습 기반의 AI 알고리즘을 사용하고 있다고 알려졌다.
스페인의 퍼핀 시큐리티(Puffin Security)와 인도의 NETSPI는 가상의 적대적 공격을 모방해 시스템의 취약점을 드러내는 '레드팀(Red Team)' 서비스를 출시했다. 적대적 공격 에뮬레이션을 통해 가장 위험한 공격 형태를 식별하고 이를 보완하는 서비스를 제공한다.
AI의 견고성 관련 분야 시장은 AI 서비스의 확대를 위해 정책적 차원에서 선제적으로 접근하고 있기 때문에 향후 급격히 확대될 것으로 예상된다.
"인공지능과 자연지능 연계 집중할 때" AI 기술청사진 연구 총괄 IITP 박상욱 팀장
[특별기획] 인공지능 기술 청사진 2030 연재순서 표
AI타임스 윤영주ㆍ이하나 기자 yyj0511@aitimes.com
