단일감각 단위 지능은 시각, 청각, 후각, 미각, 촉각과 같은 감각부터 언어지능까지 사람과 유사하게 감각을 이해하기 위한 것이다. 인공지능이 외부와 소통하기 위해 반드시 필요한 기술이다.
시각 지능은 이미지나 비디오로부터 사물의 종류, 위치, 동작 등을 이해하는 것이다. 후각, 미각, 촉각 지능은 다른 지능에 비해 많은 연구가 진행되지 않았지만 인공지능(AI) 기술 발달에 따라 관심이 증가하고 있다.
딥러닝 기술 발전에 힘입어 급격한 성능 향상을 이뤘다. 하지만 여전히 인간 수준의 성능을 따라오지 못하고 있어 꾸준한 개발해야 한다.
단일 감각 지능의 발전을 위해서는 양질의 감각 정보 센싱 능력과 지능적인 처리 능력이 필요하다. 센싱 능력은 이미 인간의 수준을 넘어섰지만 지능적 처리 능력이 단일 감각 지능 성능 향상의 제한 요소다.
◆기술동향
이미지 데이터로부터 추상적인 특징을 추출하고 분류 및 가공 작업을 수행하는 기술이다. ▲이미지 분류 ▲객체 검출 ▲객체 분할 ▲행동 인식 ▲물체 추적 ▲초해상도 ▲3차원 복원 등의 문제 해결에 주력해 왔다. 최근에는 객체 관계 인식, 캡션 자동 생성, 비디오 질의응답 등 보다 복잡한 문제 해결에 딥러닝 기술을 활용하고 있다.
인공지능이 인간의 눈과 뇌의 역할을 하며
사람 얼굴을 정확하게 인식해 판단한다.
1) 이미지 분류
2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 경진대회에 참가한 캐나다 토론토 대학팀의 AlexNet을 이용한 딥러닝 기술로 관심을 받으며 꾸준히 연구가 진행 중이다. 네트워크의 폭과 깊이의 구조에 대한 연구, 다양한 스케일을 효과적으로 결합하는 방식과 학습 방법에 대한 연구도 활발히 진행 중.
2) 객체 검출
영상에 존재하는 다중 객체에 대해 종류와 위치를 알아내는 것으로 이미지 분류보다 심화된 연구다. 2015년 UC 샌디에이고의 딥러닝 연구팀은 다수의 Classifier Stage를 연쇄적으로 순차 학습하는 구조의 Cascade R-CNN 모델을 선보였다. 지난해 실시간 영상에 대한 객체 검출을 목적으로 하는 YOLO v4가 기존 YOLO v3의 취약점인 작은 객체에 대한 검출 성능을 개선했다.
3) 얼굴 인식
2015년 구글에서 제안한 FaceNet을 기준으로 LFW 데이터세트에 대해 99% 달성했다. 현재 견고성(Robust)을 필요로 하는 데이터세트에 대해 성능을 개선하는 연구가 지속되고 있다. 인종, 나이, 촬영 환경에 대해서 불균형적인 데이터세트를 이용할 시 성능 향상이나 사람에 대한 추가적인 라벨링 없이 자가학습을 통해 성능을 개선하는 기법 등이 제안되고 있다.
4) 영상 분할
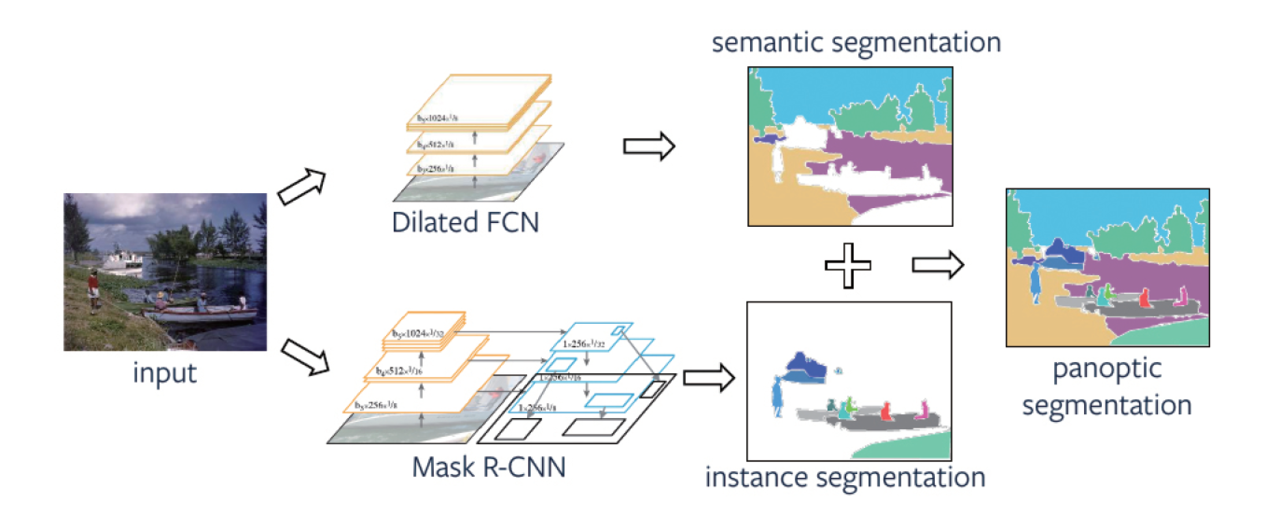
이미지의 픽셀 단위로 라벨을 할당해 영역을 분할하는 기법. 최근 딥러닝을 통해 급격한 성능 향상을 보이고 있다. 영상 분할은 의미론적 분할(Semantic Segmentation)과 객체 분할(Instance Segmentation)로 구분된다. 이 둘을 동시에 수행하는 판옵틱 분할(Panoptic Segmentation)이 최근 등장해 주목받고 있다.
5) 의미론적 분할
UC 버클리대에서 2015년 최초로 딥러닝을 이용한 방법이 소개됐다. 그 후 다양한 의미론적 분할 기술 방법들이 시도되고 있다. 주로 의료 영상과 자율 주행에 적용되고 있으며 실시간 처리를 위한 경량 네트워크 연구도 이뤄지고 있는 중이다.
6) 객체 분할
이미지 내 존재하는 모든 사물을 픽셀 단위로 검출하고 분류하는 기술. 기존에는 주로 객체 검출 결과로부터 추가적인 네트워크가 동원되는 작업을 통해 픽셀 단위로 세분화를 했다. 하지만 최근에는 단일 네트워크에 기반을 둔 객체 분할 기법이 제안됐다.
7) 판옵틱 분할
의미론적 분할과 객체 분할을 동시에 수행하는 기술로 자율 주행이 발달하면서 큰 주목을 받고 있다. 2018년부터 COCO 데이터세트를 이용한 판옵틱 챌린지가 매해 열리고 있으며 관련 논문이 크게 증가하는 추세다.
8) 포즈 인식
입력된 데이터에서 사람의 팔, 다리, 몸통 등 신체 윤곽을 분석하는 작업이다. 초기에는 RGB 영상보다 포즈를 인식하기 쉬운 Depth-Map 영상으로 사람의 포즈를 분석했다. 이후 딥러닝 방법이 도입되면서 RGB 영상에 대해서도 강인한 포즈 인식 성능을 갖는 기술이 발표되고 있다.
9) 행위 인식
입력된 데이터(RGB, Depth-Map, 포즈 등 시계열 데이터)에 대해 어떤 행위가 이뤄지고 있는지 인식하는 것. 축구, 배구, 하키 등 거시적인 행위 분류에서 사람의 미시적 행위인 발차기, 쓰러짐, 앉음 등을 인식하는 것이 목표다. 기본적으로 3D CNN을 사용하지만 실시간 행위 인식을 위한 다양한 아키텍처도 등장하고 있다.
10) 객체 관계 인식
영상에서 검출된 객체 간 관계를 설명하는 것. 탐색 가능한 관계의 개수는 매우 많다. 하지만 관계를 검출하기 위한 학습 데이터 셋을 얻기가 어려워 소수의 관계를 정확히 예측하는데 집중되는 경향이 있다.
11) 3D 영상 복원
단일 또는 다수의 2D 이미지로부터 3D 정보를 합성해내는 기술이다. 이미지 분류에서 큰 성과를 이룬 딥러닝 기술을 적용해 연구를 진행 중이다. 특히 단일 이미지를 통한 3D 형태 예측은 전통적인 3D 영상 복원기술로 처리가 어렵다. 딥러닝 기술 황용을 통한 성능 향상이 기대된다.

12) VQA(Visual Question Answering)
이미지와 그 이미지에 대한 질문이 주어졌을 때, 해당 질문에 맞는 올바른 답변을 만들어내는 기술. VQA를 성공적으로 수행하기 위해서는 이미지 캡셔닝보다 더 높은 수준의 이미지 이해와 복잡한 추론능력이 필요하다.
13) GAN(Generative Adversarial Nets)
2014년 Ian Goodfellow에 의해 소개된 영상 변환 및 생성 기술이다. 생성자와 감별자 모델을 적대적 과정을 통해 훈련한다. 생성자는 진짜처럼 보이는 이미지를 생성, 감별자는 생성된 이미지의 진위 여부를 구별하도록 학습시킨다. 학습 과정 동안 생성자는 실제 같은 이미지를 더 잘 생성한다. 감별자는 점차 진짜와 가짜를 더 잘 구별하게 된다. 이 과정에서 감별자가 가짜 이미지에서 진짜 이미지를 더 이상 구별하지 못하게 될 때를 평행상태.
14) 딥페이크
딥러닝과 페이크의 합성어. GAN 기술을 활용해 이미지나 동영상을 조작하는 기술이다. 딥페이크는 생성 기술과 탐지 기술로 각각 발전 중이다. 최근 딥페이크를 악용하는 사례가 늘어나 사회적 문제가 되고 있다. 딥페이크의 등장으로 잠깐의 시간만 투자하면 누구나 동영상을 조작할 수 있게 됐다.
최초의 딥페이크는 2017년 미국 레딧사이트에 유명 배우의 얼굴로 조작된 가짜 포르노 비디오가 올라오면서 시작됐다. 이후 이 기술을 활용해 유명인의 얼굴을 바꿔치기 한 가짜 영상들이 급격히 증가했다.
GAN 기반의 얼굴 생성 기술이 발달했다. 이에 딥페이크 생성 관련 연구도 지속적으로 증가 중. 초기에는 음성에 맞춰 목, 입, 얼굴 윗부분 등을 적절하게 조합해 생성하는 연구가 나왔다. 최근에는 생성모델(Generative Model)의 조합으로 생성하는 FSGAN이 소개됐다. Faceswap, DeepFaceLab과 같은 딥페이크 생성 SW도 등장했다.
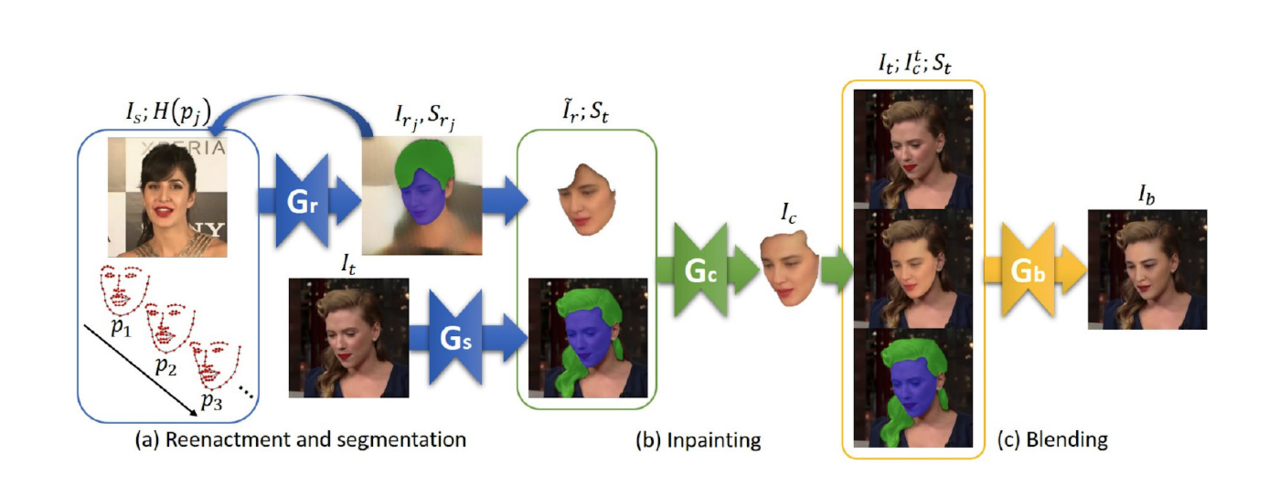
딥페이크 탐지 기술에 대한 연구도 활발히 이뤄지고 있다 . 특히 미국 DARPA가 앞장서 딥페이크 영상 탐지 기술 개발에 나섰다. 페이스북과 마이크로소프트도 딥페이크 방지 해법 챌린지에 후원하고 있다.
◆시장 동향
지문, 얼굴과 같은 생체 인식 기술이 시장에 광범위하게 도입됐다. 얼굴 인식 기술은 간편 결제, 출입 통제, 용의자 검색 등의 목적으로 상용 시스템이 가장 널리 보급된 분야 중 하나.
구글은 프로필 사진의 얼굴 인식을 통해 결제를 진행하는 핸즈프리 결제 시스템을 공개했다. 페이스북은 딥페이스(DeepFace)로 회원 계정 사진을 자동으로 인식한다. 한편 마이크로소프트는 사람 얼굴로부터 감정을 읽어내는 유어페이스(YourFace) 챗봇을 선보였다.
중국 PC 업체 레노버는 얼굴 인식만으로 구매부터 결제까지 모두 가능한 AI 무인 매장 레노버 러쿠 언맨드 스토어(Lenovo Lecoo Unmanned Store)를 열었다. 중국 베이징 소재 얼굴인식 솔루션 스타트업인 센스타임(SenseTime)은 얼굴인식 기술로 범죄 용의자를 식별하는 감시 시스템을 개발했다.
자율 주행 자동차 개발을 위해 다양한 영상 데이터를 분석, 주행을 지원하는 기술도 개발 중이다. 테슬라는 다수의 2D 카메라 입력에서 3D 정보를 합성해 자율 주행에 필요한 시각 정보 기술을 개발한다. 현대모비스는 주변 차량·보행자·물체 인식 기술을 양산차에 적용하는 것을 목표로 투자하고 있다.
영상 분석 기술은 새로운 의료 기술, 기기, 시스템 개발을 촉진한다. 텐센트는 의료영상 분석 AI 마잉(Mying)을 개발해 수 백 여개 병원에 보급했다. 그 예로 마잉은 당뇨병, 유방암, 식도암, 대장암 등을 진단할 수 있는 6개의 인공지능 시스템이다.
◆주요 프로젝트
[미국]
①IARPA 'Janus'
연구시기 : 2015~2018
②IARPA 'DIVA'(Deep Intermodal Video Analytics)'
연구시기 : 2017~2020
③페이스북 'Deepfake Detection challenge(DFDC)'
연구시기 : 2019~2020
④DARPA 'Media Forensics(MediFor)'
연구시기 : 2015~2020
⑤IARPA, ARA 'CORE3D'
연구시기 : 2017~2022
⑥RSNA 'Intracranial Hemorrhage Detection and Classification Challenge'
⑦DARPA, univ of Illinois 'DEFT'
연구시기 : 2012~2018
[중국]
①바이두 '아폴로 라이트'
연구시기 : 2014~
②멕비(Megvii) 'Face++'
연구시기 : 2016~2018
③텐센트 '마잉(miying)'
연구시기 : 2018~
④중국 정부 '스카이넷(Skynet)'
연구시기 : 2015~
"인공지능과 자연지능 연계 집중할 때" AI 기술청사진 연구 총괄 IITP 박상욱 팀장
[특별기획] 인공지능 기술 청사진 2030 연재순서 표
AI타임스 박성은ㆍ정윤아 기자 sage@aitimes.com
