지난 시간에는 회귀 분석에 이어 분류 문제를 해결하는 방식에 대해 살펴봤다. 이번 시간에는 클러스터링의 대표적인 알고리즘인 K-Means가 어떻게 작동하는지와 이름이 유사한 K-NN과의 차이점은 무엇인지 살펴본다.
[글 싣는 순서]
⑨ 알고리즘 (3) - 클러스터링
⑩ 성능평가 (1) - 회귀
⑪ 성능평가 (2) - 분류
⑫ 데이터사이언스 전문가 인터뷰

군집화(clustering)
지난 두 번의 글을 통해 회귀와 분류 문제에 대해 살펴봤다. 회귀와 분류 문제 해결 방식은 데이터의 피처들로부터 수치 값을 찾거나 범주를 나눈다는 점에서 다르지만, 두 분야 모두 레이블(label)된 데이터를 이용해 문제를 해결한다는 점에서 지도 학습(supervised learning)으로 동일하다.
반면 오늘 다룰 군집화(clustering)는 데이터의 피처와 목적 변수(target variable)의 관계를 학습해 새로운 데이터 값을 예측하는 회귀나 분류와 다르게 데이터 자체가 지니고 있는 특성을 찾아 여러 개의 클러스터로 나누어 보는 비지도 학습을 말한다.
이번 글에는 클러스터링의 가장 대표적인 알고리즘 K-Means에 대해 살펴본다.
K-Means
지난 글에서는 분류 문제를 해결하는 방식 중 대표적인 알고리즘인 K-NN에 대해 설명해 보았다. 오늘 살펴볼 K-Means 알고리즘과 이름도 비슷하고 데이터를 그룹으로 나눈다는 의미에서 두 알고리즘을 혼동하는 경우가 많은데 오늘 정확하게 그 차이점을 이해해보도록 하자.
K-NN 알고리즘의 경우 훈련 데이터가 각자 자신이 어느 분류에 속하는지 알고 있다. 그리고 테스트 과정에서 자신의 레이블을 모르는 데이터가 입력됐을 때 전체 학습 데이터 포인트들과의 거리를 계산해 가장 가까운 K개의 데이터를 선택 후 선택된 K개의 훈련 데이터 포인트들이 많이 속한 범주로 테스트 데이터를 분류하게 된다. 이때 K-NN의 K는 설명과 같이 테스트 데이트의 범주를 나누기 위해 몇 개의 가장 가까운 데이터 포인트를 선택하는가를 설정하는 값이다.
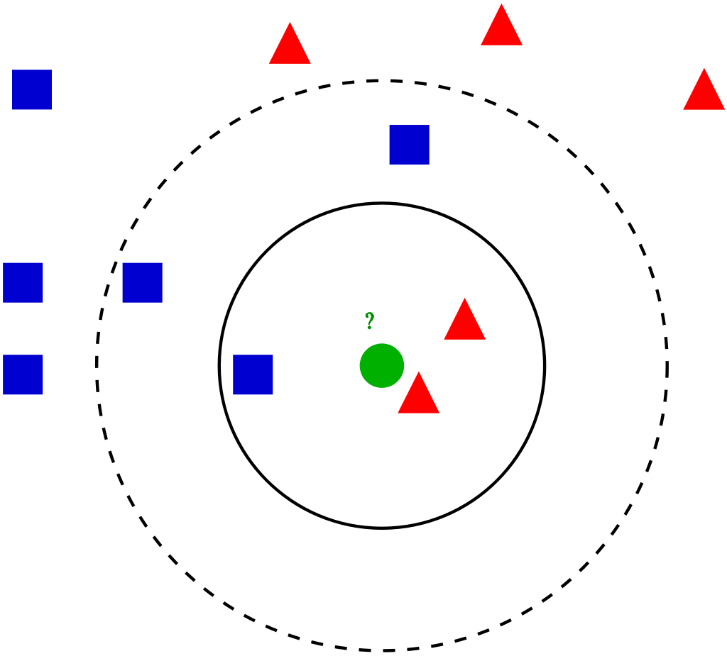
K-Means 알고리즘도 이름에 K라는 값을 갖고 있는데 K-Means의 K는 K-NN의 그것과는 다르다. 먼저 K-Means가 문제를 해결하는 방법을 살펴보자. 위에서 설명한 것과 같이 K-Means는 비지도 학습 알고리즘으로 데이터세트에는 별도의 레이블이 존재하지 않는다. 따라서, 사용자가 자신의 도메인 지식을 바탕으로 몇 개의 클러스터로 나누어볼지 결정해 임의의 K값을 설정한다.
이렇게 설정한 K값이 알고리즘 이름에서 말하는 Mean 즉, K개 클러스터의 중심(centroid) 개수가 된다.
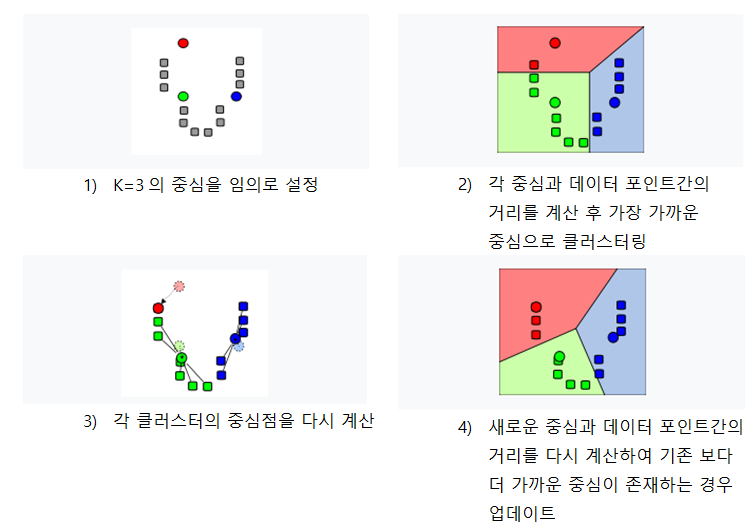
(1)정해진 K개의 중심은 보통은 임의로(random) 데이터 공간에 위치하게 된다.
(2)그 후 각 중심점과 전체 데이터 포인트들과의 거리를 계산해 데이터 포인트들은 자신과 가장 가까운 중심으로 클러스터링 된다.
(3)전체 데이터 포인트가 클러스터링된 후 각각의 클러스터의 중심을 다시 계산 후
(4)다시 새로운 중심과 데이터 포인트들과의 거리를 계산해서 데이터 포인트와 더 가까운 클러스터의 중심이 존재하는 경우 그 중심으로 업데이트한다.
더 이상 클러스터의 중심이 변동이 없을 때까지 (2)~(4)의 과정을 반복한다.
K-Means의 경우 초기에 중심의 위치를 임의로 설정하기에 최적의 해가 아닌 로컬 미니멈(local minimum)일 수도 있음으로 여러 번의 실험을 통해 확인해보는 것이 좋다. 관심있는 분들은 이러한 문제를 해결하기 위한 기법과 K값을 설정하기 위한 방법에 대해 더 알아보자. K값을 정하는 방식은 클러스터 간 분산은 최대로 하면서, 클러스터 내 데이터 간 분산은 최소화하는 K를 찾는 원리라고 이해할 수 있다.
참고로, K-NN, K-Means와 같이 거리를 기반으로 하는 알고리즘의 경우 범주형 데이터는 쉽게 적용하기 어려우며, 수치 계산을 통해 문제를 해결하기에 피처의 스케일에 영향을 받아 적절한 스케일링 전처리가 필요하다.
박정현 칼럼니스트는 서울대 EPM연구원(공학전문대학원 엔지니어링 프로젝트 매니지먼트(EPM) 연구실)이며, 머신러닝 스타트업을 창업한 바 있다.
박정현 서울대학교 연구원 park.jeonghyun@snu.ac.kr
