지난 시간에는 클러스터링의 대표적인 알고리즘인 K-Means가 어떻게 작동하는지와 이름이 유사한 K-NN과의 차이점은 무엇인지 살펴봤다. 이번 시간에는 지금까지 살펴본 알고리즘이 회귀와 분류 문제를 적절하게 해결했는지, 검증을 위해 사용하는 모델 성능 평가 방법에 대해 살펴보고자 한다.
[글 싣는 순서]
⑩ 성능평가 (1) - 회귀
⑪ 성능평가 (2) - 분류
⑫ 데이터사이언스 전문가 인터뷰

성능평가 – 회귀
데이터 분석 문제를 해결하기 위해서는 데이터의 특성을 살펴보고 문제 해결에 적합한 여러 모델을 만들어 문제를 해결할 수 있다. 단 한 가지 방법으로만 문제를 해결할 수 있는 것은 아니기에 다양한 접근 방법으로 문제를 해결해볼 수 있다. 여러 방법 중 가장 적합한 모델을 선정하기 위해 진행하는 과정이 바로 성능평가다.
데이터 분석 문제는 크게 회귀와 분류 두 가지로 나뉜다고 여러 번 설명한 바 있다. 따라서 성능 평가에 있어서도 크게 회귀와 분류 문제를 해결하는 두 가지 방식이 존재한다. 회귀의 문제는 수치 값을 예측하는 문제이기에 실젯값에 얼마나 가깝게 예측했는가를 통해 모델의 성능을 평가할 수 있다. 분류의 경우 얼마나 정확하게 분류를 했는지를 통해 성능을 평가할 수 있다.
오차와 잔차
오차(Error)와 잔차(Residual)는 구분하지 않고 그냥 에러라고 말하는 경우가 많다. 하지만 통계학에서는 두 개념을 구분한다. 모집단을 대상으로 회귀분석으로 예측을 수행했을 때 실젯값과 예측값의 차이를 오차라고 하는 반면, 모집단에서 추출한 표본집단을 대상으로 회귀분석 후 표본집단의 값과 예측값의 차이를 잔차라고 한다.
둘 다 실젯값과 예측값 차이를 나타내고 이 값들을 최소화 하도록 모델을 구성한다는 의미에서 둘 다 모델의 성능을 나타내는 지표로 볼 수 있으며, 모집단과 표본 집단 중 어느 것을 대상으로 회귀 문제를 해결하는가에 따라 구분하며 오차와 잔차를 최소화 하도록 회귀 모델을 구성하는 것은 동일하다. 머신러닝이나 데이터분석에서는 보통 전체 데이터를 사용하지 않고 표본 데이터를 사용하기에 잔차를 사용하는 것이 적합하나 보통은 에러라는 개념으로 사용하곤 한다.
여기서도 모집단이나 표본집단이냐를 구분하지 않고 모델의 성능평가 측면을 설명하는 목적으로 에러라는 용어를 사용해서 설명한다.
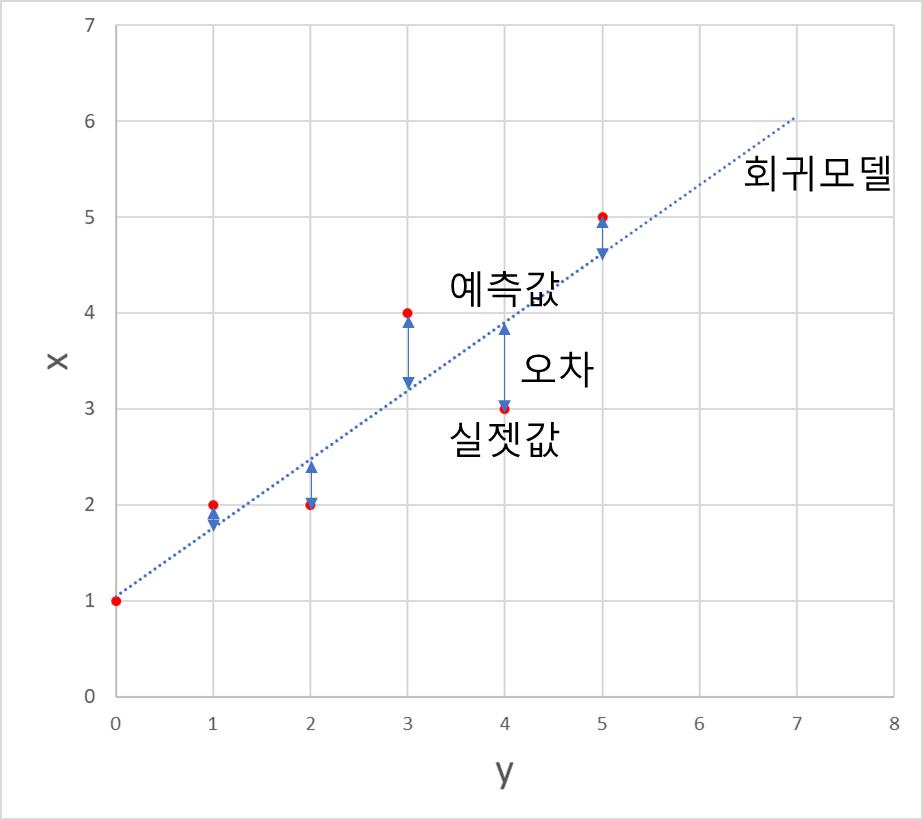
예를 들어 주어진 데이터가 다음과 같을 때
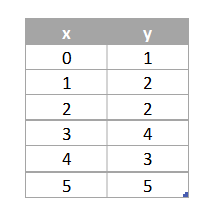
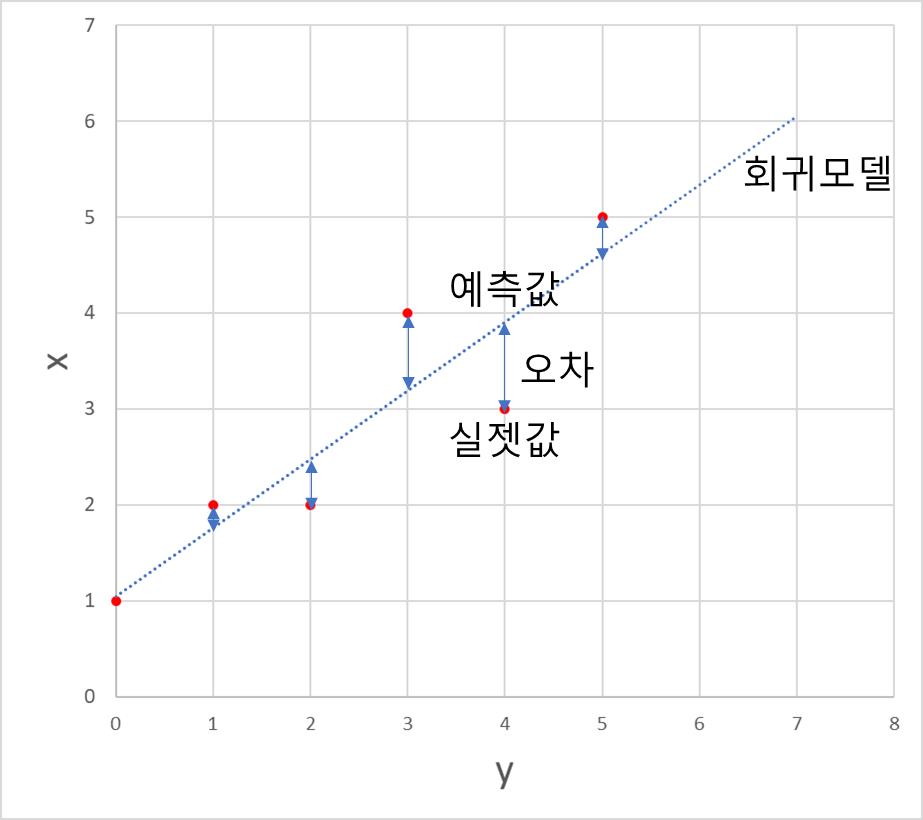
실젯값과 예측값, 오차, 회귀 모델은 다음과 같이 표현할 수 있다.
오차(Error)
위에서 설명한 바와 같이 오차는 실젯값 y_i과 모델의 예측값 y ̂_i의 차이를 말한다.
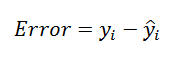
평균제곱오차(MSE, Mean Squared Error)
각각의 데이터 포인트의 오차를 확인해 보면 그림과 같이 양수와 음수값을 갖는 경우가 존재한다. 따라서 단순히 오차의 합을 계산하는 경우 합이 0이 되는 경우가 생길 수도 있어 절댓값을 취하거나 제곱을 취해 합하는 것이 올바른 방식일 것이다.
보통은 오차의 제곱을 평균한 값을 주로 사용하며 이를 평균제곱오차(MSE)라고 한다. 제곱을 한다는 의미는 오차가 큰 값이 강조되는 효과도 준다.
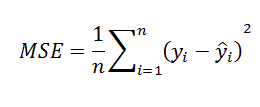
평균제곱근오차(RMSE, Root Mean Squared Error)
평균제곱오차의 값은 오차의 제곱의 합을 표현하다보니 값이 매우 커지게 되므로 여기에 루트를 씌워 값을 표현하며 이 지표를 평균제곱근오차라 한다.
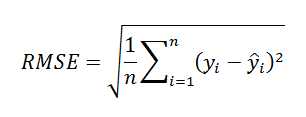
위 지표들을 정리해보면 결국 오차를 계산 후 평균을 내보고 여기에 루트를 씌워 연산과 비교를 편하게 하는 식으로 정리할 수 있다. 회귀분석에서는 결국 위 평가지표를 최소화하는 모델을 찾는 것을 목적으로 한다. 딥 러닝에서도 이와 유사한 방식으로 목적함수를 설계해 최소화하도록 모델을 최적화하게 된다.
R2(R Squared)
R2 지표도 회귀식의 성능을 평가하는 지표로 많이 사용하는 결정계수값으로 예측한 모델이 얼마나 실제 데이터를 설명하는지를 나타낸다.
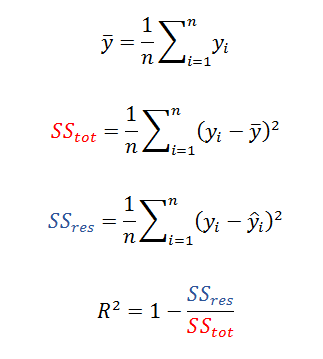
즉, 위 그림과 같이 R2 값은 평균값으로 예측을 했을 때의 오차의 제곱의 합(붉은 색 사각형의 면적)과 실제 우리가 예측한 모델(f)의 오차의 제곱의 합(파란색 사각형의 면적)을 비교한 값의 비율로 표현되며 해석의 편의를 위해 1에서 뺀 형태로 나타낸다. 따라서 모델이 모든 데이터를 완벽하게 설명하게 된다면 파란색 면적이 0이 되고 R2 값은 1을 갖게 된다.
보통 머신러닝, 데이터사이언스를 공부할 때 성능평가에 대한 부분을 중요하게 생각하지 않고 바로 알고리즘을 실습해보는 경우가 많다. 하지만 여러 방식을 통해 분석을 한 후 목표를 올바르게 세웠는지 그 목표에 접근한 방식 중 어떤 방식이 최선인지를 모른다면 문제를 제대로 해결했는지 알 수 없을 것이다. 따라서 문제를 해결하는 방법과 더불어 문제를 잘 해결했는지를 평가하는 방법에 대해서도 짚고 넘어가는 것이 좋다.
박정현 칼럼니스트는 서울대 EPM연구원(공학전문대학원 엔지니어링 프로젝트 매니지먼트(EPM) 연구실)이며, 머신러닝 스타트업을 창업한 바 있다.
박정현 서울대학교 연구원 park.jeonghyun@snu.ac.kr
