
인공지능(AI)으로 로또 당첨 번호도 예측할 수 있을까?
정답은 ‘불가능’이다. AI의 능력이 부족해서는 아니다. 다만 AI가 활약할 수 없는 분야가 있을 뿐이다.
AI의 계산 능력은 의심할 여지가 없다. 지난해 세계는 AI의 단백질 구조 ‘예측’ 능력에 놀랐다. 구글 딥마인드가 개발한 알파폴드2는 단백질 구조 예측 능력 평가 대회(CASP, Critical Assessment of protein Structure Prediction)에서 인간을 따돌리고 1위를 차지했다.
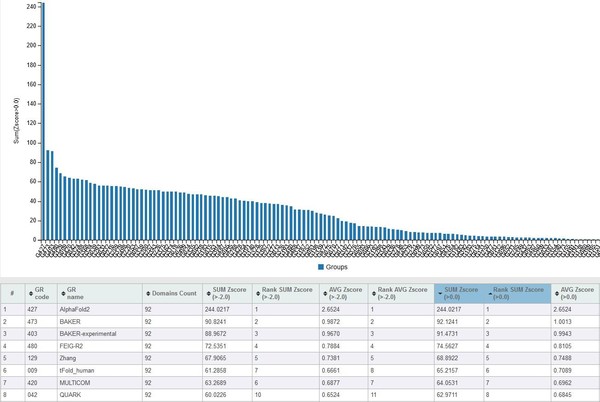
평균 92.4점을 달성해 2등과 격차는 25점 이상 차이 난다. 독일 막스 플랑크 연구소가 박테리아 구조를 밝히기 위해 10년간 매달렸지만 실패했다. 하지만 알파폴드는 단 30분 만에 박테리아 단백질 구조를 밝혀냈다.
이처럼 AI는 어마어마한 계산 능력을 가졌다.
하지만 그럼에도 AI는 만능이 아니다. AI로 수억 상금이 달린 로또 번호를 예측하면 좋겠지만 그럴 수 없다.
똑똑한 AI가 할 수 없는 것들은 무엇이 있을까.
◆빅데이터가 무의미한 ‘독립시행’ 사건
AI는 ‘데이터’를 기반으로 계산한다. 데이터는 앞서 일어난 사건들의 축적 정보다.
페이스북 앱은 하루 평균 1인당 100건 이상 로그 기록을 수집한다. 간단한 행동 하나에도 어떤 콘텐츠를 좋아하는지, 어느 부분을 건너뛰는 지 데이터를 모은다. AI는 그렇게 모인 데이터를 학습해 이용자 취향을 분석한다. 관심 가질 게시물을 추천하고 광고를 보여주는 알고리즘을 형성한다.
이렇듯 AI는 ‘과거’에서 생긴 일로 ‘미래’를 예측한다.
하지만 로또 번호를 예측할 때는 과거 정보가 소용없다. 로또 추첨은 앞선 결과가 다음 결과에 영향을 미치지 않는 ‘독립시행’ 사건이기 때문이다.
이는 동전 던지기와 같다. 동전을 3번 던져 모두 앞면이 나왔다고 가정하자. 계속 앞면이 나왔다고 다음 시행에서 또 앞면이 나올 확률이 올라가지 않는다. 반대로 뒷면이 나올 확률이 오르지도 않는다.
이처럼 AI는 독립시행 사건에서는 능력을 펼치지 못한다. 주사위를 던지거나 가위바위보를 할 때도 마찬가지다.
◆사람마다 다른 고유 ‘경험’... AI는 모른다
컴퓨터의 장점은 ‘정확’하다는 것이다. 간단한 수학 계산을 할 때도 실수를 하는 인간과는 다르다.
하지만 인간의 인지 능력에서는 정확하다는 말이 무의미한 경우도 있다. 각자 다르게 느낄 수 있기 때문이다.

한때 온라인에서 ‘원피스 색깔’ 논란이 일었다. 두 가지 색깔 줄무늬를 가진 원피스를 사람마다 다르게 바라봤기 때문이다. 검정·파랑이냐 혹은 흰색·금색이냐를 놓고 네티즌이 갑론을박을 펼쳤다.
사람마다 색깔을 다르게 인식하는 이유는 저마다 가지고 있는 시세포 비율이 다르기 때문이다. 사람 눈에는 적색, 녹색, 청색을 인지하는 원추세포가 있다. 저마다 살아온 환경에 따라 이 3가지 원추세포 민감도는 달라진다. 사람마다 색깔이 다르게 보이는 이유다.
사물이 본래 무슨 색을 가졌느냐와 무관하게 인지하는 값은 바뀔 수 있다. 원피스 색깔을 다르게 봤어도 ‘틀렸다’ 라고 말할 수 없는 이유다.
인간 개인이 가진 고유 경험이나 가치관에 따라 결과가 달라지는 문제들이 있다. 이는 AI가 범접할 수 없는 분야다.
◆‘데이터의 함정’... 통계의 오류를 부른다

11번가, 쿠팡 등을 비롯한 이커머스 기업은 AI를 활발히 활용하고 있다. 이용자 소비 데이터를 학습해 상품을 추천하는 알고리즘을 활용한다.
하지만 나의 소비 추이와 무관한 상품들이 추천될 수 있다. 이를테면 집에 정수기가 있어 생수를 구매할 필요없는 사람에게 생수 추천이 되는 경우다.
판매자 가격경쟁으로 저마다 생수 할인 이벤트를 하면 전체 고객의 생수 구매량은 늘어난다. 이는 알고리즘에 반영돼 상품에 가중치를 두게 된다. 개인 이용자별로는 상품에 관심이 없어도 알고리즘이 가중치를 둔 물건을 추천하게 되는 이유다.
적절하지 않은 데이터 학습으로 인해 나의 소비 추이와 무관한 상품들이 추천될 수 있다.
AI의 핵심은 데이터를 학습해 알고리즘을 형성하는 데 있다. 하지만 모든 데이터가 동일한 가치를 갖는 것은 아니다. 알고리즘이 항목별로 가중치를 두는 이유다. 더 많은 사람이 선호하는 상품에 더 높은 가중치를 둔다.
이럴 경우 AI는 적절하게 사람들의 선호도를 반영하지 못한다.
◆엉뚱한 결과 내는 AI ‘인권·생명’ 문제에도 활용할 수 있을까?

위 저해상도 사진은 얼핏 보면 아래 두 사진과 모두 비슷하다. 하지만 둘은 전혀 다른 사람이다. 왼쪽은 코미디언 김경진, 오른쪽은 연기자 장근석이다.
AI는 흐릿한 이미지를 선명하게 구현하는 것도 가능하다. 첩보영화를 보면 CCTV에 녹화된 저해상도 영상을 고화질로 바꾸는 장면이 자주 등장한다.
이는 합성곱 신경망(CNN, Convolutional Neural Network)이라는 AI 딥러닝 기술로 가능하다.
합성곱신경망은 이미지 혹은 영상 등 시각적 데이터를 분석하는데 탁월한 AI 기술이다. 합성곱이라는 용어가 쓰인 이유는 다층 레이어가 겹겹이 쌓여 작동하기 때문이다.
색깔만 인식하는 필터, 조도만 인식하는 필터 등 한 가지 특징만을 도출해 여러 장의 레이어를 형성한다. 각 레이어는 서로 특징을 곱해 심층적인 이미지 분석을 한다.
고해상도 이미지 데이터를 학습한 AI가 저해상도 이미지를 CNN을 통해 화질을 높일 수 있다.
하지만 위 사진처럼 저해상도 이미지는 다르게 해석될 수 있다. AI가 그동안 어떤 이미지를 학습했느냐에 따라 다르다.
만일 AI가 일반인 위주로 데이터를 학습했다면 사진 해상도를 높인 결과도 일반인으로 나올 가능성이 크다. 반면 연예인 사진을 위주로 학습했다면 결과도 연예인으로 나올 가능성이 높다.
그동안 학습한 데이터에 따라 AI가 ‘편견’을 갖게 되는 지점이다.
문제는 영화에서처럼 AI를 활용했다가 CCTV 이미지를 다른 사람으로 분석했을 경우다. 엉뚱한 사람이 범인으로 쫓길 수 있기 때문이다.
한 사람의 권리나 생명이 관여되는 분야에서는 이런 AI의 오류는 치명적이다.
AI의 능력이 날로 발전하는 것은 맞지만 그 활용은 더욱 조심스러워야 한다.
본 기사는 지난 5일 본지 기자들 대상 인공지능 스타트업 '누아'의 서덕진 대표 특강 내용을 기초로 작성됐다.
AI타임스 장희수 기자 heehee2157@aitimes.com
