
초거대 인공지능(AI) 개발사들이 규모 경쟁을 넘어 비용 효율성에 주목하기 시작했다. 초거대 AI 개발과 사용에 드는 비용을 줄이는 기술 성과를 강조하기 시작한 것. 방대한 데이터와 컴퓨팅 파워만으로 승부를 보는 기존 전략의 한계를 극복하기 위한 움직임으로 보인다.
지난 9일(현지시간) 딥마인드는 자사 초거대 언어모델 '고퍼(Gopher)'와 함께 검색(Retrieval) 언어모델 'RETRO'를 소개했다. RETRO를 활용하면 소규모 모델이 자신보다 25배 큰 모델 이상의 성능을 낼 수 있다.
국내에서는 LG가 14일 자사 초거대 멀티모달 AI 엑사원을 공개하는 자리에서 AI 활용을 효율화하기 위한 새로운 병렬처리 구조 '엑사원 인퍼런스 프레임워크(EXAONE Inference Framework)'를 주요 성과 중 하나로 발표했다. 인프라 규모 최적화를 위해 LG AI 연구원이 직접 프레임워크를 디자인한 것.

학습 아닌 추론에 알맞은 프레임워크 직접 개발
프레임워크는 학습된 AI 모델을 서비스하는 역할을 하는 기술이다. 학습에 사용한 프레임워크에 있음에도 불구하고 별도로 인퍼런스 프레임워크 구현하는 이유는 학습 프레임워크와 인퍼런스 프레임워크가 목적이 다른 만큼 특성이 달라야 하기 때문.
조현직 LG AI 연구원 랭귀지랩 연구원은 "대량의 데이터를 학습하기 위해 한 번의 큰 배치(batch)를 돌려야하는 학습 프레임워크와 달리, 인퍼런스 프레임워크는 적은 데이터에 대해 빈번히 요청받고 빠르게 응답해야하기 때문에 좀 더 경량화돼야 한다"고 설명했다.
그는 "과거에 비해 모델 사이즈가 증가하면서 추론 지연(inference latency)이 점점 커지고 있으므로 서비스에 최적화된 인퍼런스 프레임워크 요구가 많아지고 있다. 그럼에도 불구하고 초거대 모델 구동을 위한 인퍼런스 프레임워크는 부족한 상황이다. 많은 엔지니어링 노하우가 필요한 만큼 고도화된 솔루션도 공개된 것이 없다. 엑사원의 효율적 서비스를 위한 우리만의 인퍼런스 프레임워크를 개발한 이유"라고 말했다.
이홍락 LG AI 연구원 CSAI도 "엑사원과 같은 큰 모델은 학습 못지않게 서비스에도 많은 자원이 필요하다. 학습 모델에 실제 데이터를 입력해 결과를 산출하는 과정을 인퍼런스라고 하는데, 초거대 AI의 인퍼런스 프레임워크를 어떻게 설계하느냐에 따라 필요한 연산 자원 차이가 매우 크다"며 연구 필요성을 강조했다.
LG AI 연구원의 새로운 병렬처리 구조...어떻게 구현했나
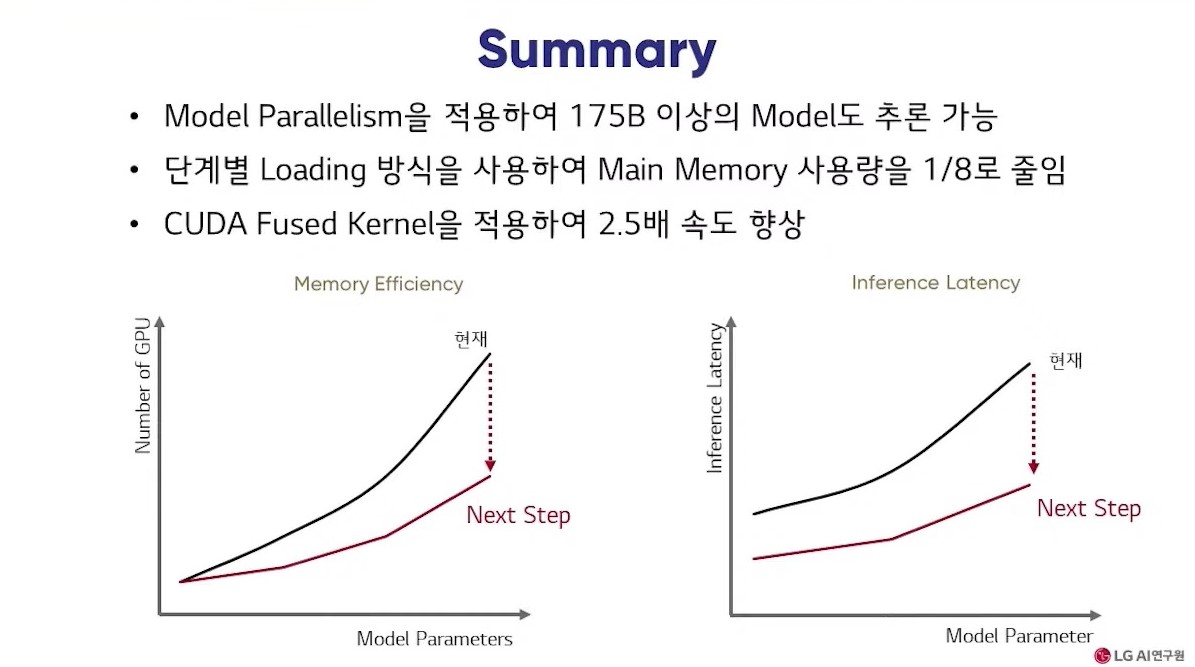
엑사원 인퍼런스 프레임워크를 사용하면서 연구팀은 GPU 메모리 효율을 강화해 초거대 모델 분산 추론에 성공했다. 메인 모델의 사용량은 8분의 1로 줄였으며, 기존 프레임워크 대비 속도를 2.5배 높일 수 있었다.
효율적인 추론 기반 마련을 위해 연구팀은 엑사원을 위한 모델 패럴리즘(Model Parallelism)을 인퍼런스 프레임워크에 구현했다. 이러한 방법을 통해 규모가 작은 모델부터 1750억개 파라미터를 넘는 크기의 모델까지 추론(inference)할 수 있는 기반을 마련한 것.
모델 로딩 개선을 위해서는 GPU가 아닌 메인 메모리에 모델을 먼저 로딩하는 방식을 사용했다. 엑사원 모델 사이즈가 더 커진 후에는 메인 메모리 사용량을 줄이기 위해 단계별 로딩 방식을 사용했다.
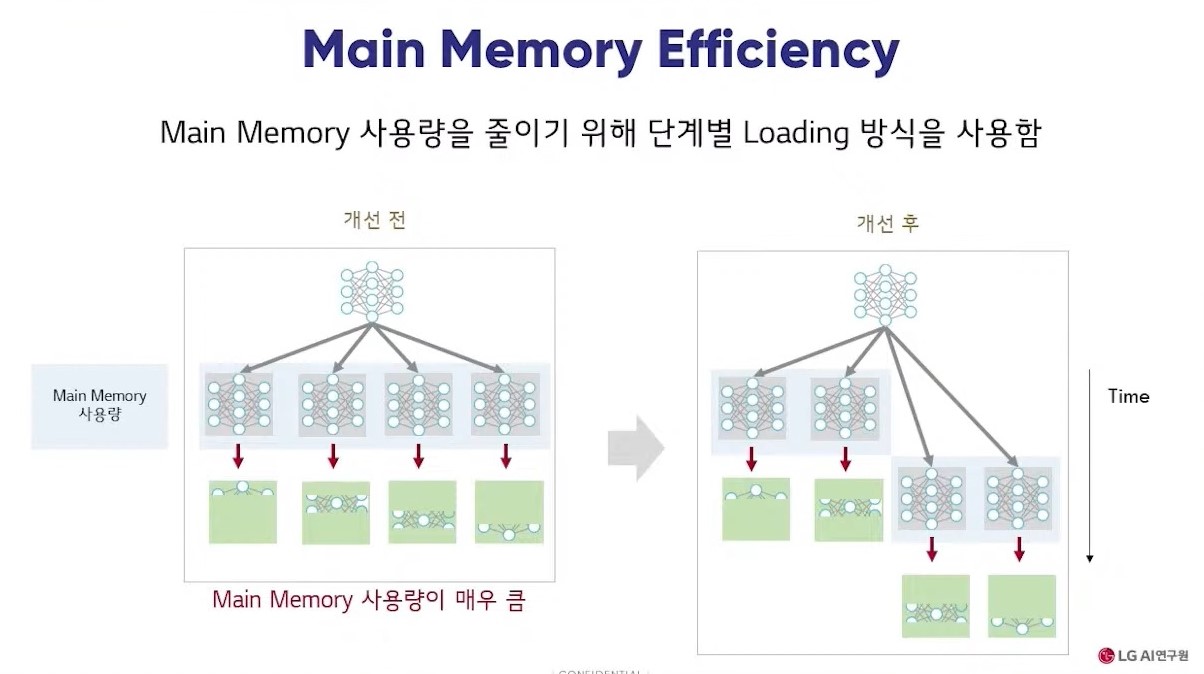
한장훈 LG AI 연구원 랭기쥐랩 연구원은 "단계별 로딩은 동시에 로딩 수행하는 수에 제한을 두는 방식이다. 두 개씩 모델을 로딩하는 경우 1.28TB 사용량이 320GB로 줄어들고 한 개씩 로딩 수행하면 160GB로 줄어든다. 이를 통해 1750억개 파라미터 모델 로딩이 가능해졌다"고 설명했다.
모델 인퍼런스 속도를 2.5배 높일 수 있었던 비결은 엑사원에 최적화된 'CUDA Fused Kernel' 덕분이다. 한 연구원은 "1750억개 모델 추론 시 작은 모델보다 지연(latency) 증가 문제가 늘어난다. 커널 퓨전 기법은 분산된 연산을 효율적으로 합해 하나의 연산으로 처리하는 기법이다. 엑사원 모델에 맞는 커널이 없어 직접 개발했다. 맞춤형 퓨전 커널을 사용해 속도를 2.5배 향상시킨 것"이라고 전했다.
AI타임스 박성은 기자 sage@aitimes.com
- 카카오브레인, 초거대 멀티모달 AI 'minDALL-E' 공개...국내 두 번째
- 네이버, 초거대 AI 후속 연구 공개...영어·이미지까지 영역 확장 중
- [분석] 베일 벗은 카카오 초거대 AI ‘KoGPT’, 기존 모델과 비교해보니
- "산업 전반 AI 기술 도입 활성화, 공공기관·민간기업 협력해야"
- [단독]LG, 분야별 8개사와 '엑사원 연대' 구축...초거대 AI 상용화 발판
- 뉴욕 패션위크 뒤집은 LG 신입 디자이너, 알고 보니 AI
- LG가 출시한 초거대 AI '엑사원', "넌 무엇을 할 수 있니?"
- 서울대-LG AI연구원, AI 공동연구센터 설립한다
