
국내 금융 인공지능(AI) 스타트업 투디지트가 미국 스탠퍼드대가 주최한 기계독해(MRC) 테스트 'SQuAD2.0'에서 12위를 기록했다고 밝혔다. 구글, 마이크로소프트(MS)보다 높은 등수다.
SQuAD2.0은 10만 개의 답변 가능한 질문과 5만 개의 답변이 불가능한 질문을 통해 AI 시스템의 능력을 평가하는 대회다. 글로벌 AI팀이 참가해 365일 경쟁한다. 정답과 일치한 답변(Exact Match)에 부여되는 EM 점수와 정답과 예측을 기반으로 하는 F1 점수를 토대로 등수를 결정한다.
QuAD 2.0은 주어진 글을 완전히 이해해야 풀 수 있다. 기존 1.0 버전에 '오답 찾기' 시험이 추가되면서 질문을 이해하지 못하고 '찍기'로 답변하는 것이 불가능해졌다. 오답 찾기 유형의 문제들은 지문과 상관없는 질문에 답변해선 안 된다.
이 대회는 새로운 팀이 참여하면 그 팀의 점수가 기록되고 순위가 변경되는 방식으로 이뤄진다. 투디지트는 지난 4월 4일 대회에 참여해 총점 182.348점을 기록했다. 12위에 해당하는 점수다. AI 정확도를 나타내는 EM은 89.923점, F1 점수는 92.425점을 받았다.
투디지트가 대회에 참여하면서 글로벌 기업들의 순위에도 변화가 생겼다. 구글 리서치와 토요타 기술연구소(시카고 TTIC)의 연합팀은 공동 13위와 24위로 내려갔다. 구글 브레인과 스탠퍼드 대학 연합팀은 20위, 페이스북 AI팀은 28위에 머무르게 됐다.
인간의 독해 능력을 넘어서지 못한 곳까지 포함하면 등수는 또 달라진다. 구글 브레인과 CMU 연합팀은 공동 34위, 구글 AI Language 팀은 41위를 기록 중이다. MS 연구팀은 공동 34위, 서울대-현대차 연합팀은 51위와 59위에 이름을 올리고 있다.
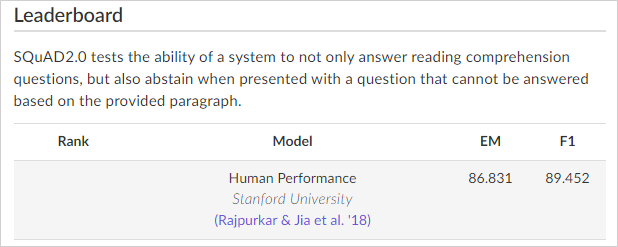
투디지트가 기록한 점수는 실제 사람이 기록한 점수보다 높은 수치다. 실제 사람이 테스트에 참여해 기록한 리더보드 기준 점수는 EM 86.831점, F1 89.452점이다.

인공지능의 독해 능력이 인간을 넘어선 것은 2019년 9월 18일이다. 그 전에는 세계 1위 팀도 인간보다 더 잘 이해할 수 없었다. 현재는 공동 28위 페이스북 AI팀까지 EM과 FI 합산 총점 기준 인간의 능력을 넘어서고 있다. 하지만 정답과 정확히 일치하는 EM 기준으로는 아직 많은 글로벌 기업의 연구소들이 그 기준을 넘지 못하고 있다.
박석준 투디지트 대표는 "AI는 인간의 독해 능력을 넘어서는 시점부터 실제 업무에 도움을 줄 수 있다"며 "AI는 기술 개발에 큰 비용이 소모되지만 개발된 기술을 광범위한 서비스에 적용해도 비용과 인건비가 증가하지 않아 경제성이 높다"고 평가했다. 이어 "현재 1위와의 격차는 1.805점, 바로 앞 11위와는 0.079점"이라며 "쉬운 일은 아니지만 적절한 연구환경만 확보할 수 있다면 세계 1위가 되는 것도 충분히 가능하다"고 말했다.
AI타임스 김동원 기자 goodtuna@aitimes.com
[관련기사][GTC 2022] KT, GPT-3 뛰어넘는 언어모델 만든다
[관련기사]"AI 챗봇의 원리가 궁금하다면..." [특별기획 AI 2030] ⑩ 단일감각지능 고도화_언어청각지능
