
카카오브레인(대표 김일두)이 31일 이미지-텍스트 데이터셋인 '코요(Coyo)'를 전격 공개한다.
코요는 데이터 규모가 약 7억 4000만개에 이르는 데다 품질이 좋은 데이터만 자동으로 선별해 모아논 데이터셋이다. 초거대 인공지능(AI) 모델에 사용할 데이터셋의 품질 향상에 크게 기여할 것으로 보인다.
기업은 대부분 초거대 AI 모델 성능 향상을 위해 수작업으로 이미지-텍스트 쌍을 맞춰 데이터를 모은다. 이는 시간과 비용이 많이 드는 작업이다. 데이터 품질을 보장하지 못하는 한계도 있다.
반면 카카오브레인은 직접 개발한 이미지-텍스트를 자동 수집 기능을 활용해 데이터를 모았다. 이는 수집 비용과 시간을 줄이면서 품질을 높이는 효과로 이어졌다. 데이터셋은 초거대 AI 모델의 성능을 좌우하는 핵심 요소다.
김일두 카카오브레인 대표는 "이번 데이터셋 공개는 초거대 AI 기술 개발에 박차를 가할 중요한 근간이자 이정표"라며 "내년 상반기 중에 코요 데이터셋을 활용한 초거대 AI 모델을 추가 공개할 예정"이라고 밝혔다.
카카오브레인은 지난 4월 공개한 초거대 AI 이미지 생성 모델인 '알큐-트랜스포머(RQ-Transformer)'를 개발하는데에도 코요를 적용했다. 그 결과는 지난 6월 열린 학술대회 CVPR 2022에서 논문으로 발표했다.
코요는 AI 아티스트 '칼로(Karlo)' 개발에도 사용했다. 최근 고상우 현대미술가, 삼성전자 '갤럭시 북 아트 프로젝트'와 협업해 상용화했다. 사용자가 단어를 입력하면 이에 맞는 이미지를 생성하는 모델이다.
코요 데이터셋은 31일부터 카카오브레인 홈페이지에서 볼 수 있다.
초거대 AI 성능, 매개변수 크기보다 데이터셋 품질이 관건
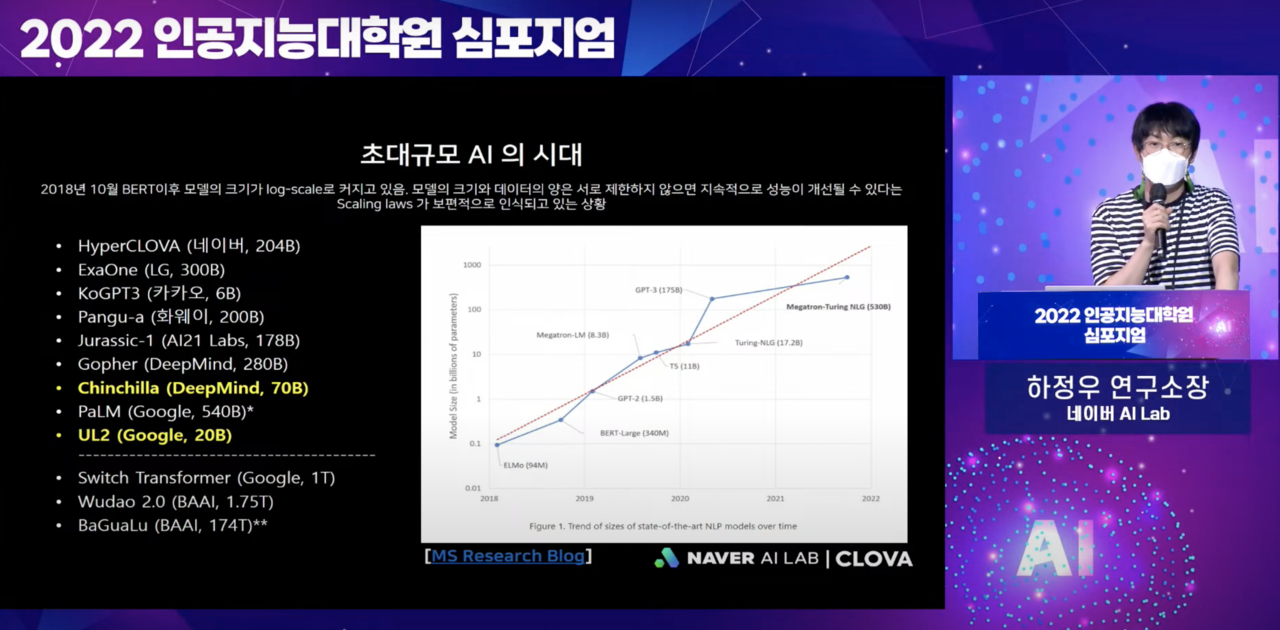
초거대 AI 모델 성능을 높이려면 무조건 많은 매개변수(파라미터)보다는 품질 좋은 데이터셋으로 모델을 최적화해야 한다. 이와 관련해서는 하정우 네이버AI랩 연구소장도 얼마 전 열린 AI대학원 심포지엄에서 "무한히 늘어나는 파라미터를 제대로 잘 활용하고 있는가에 고민해 봐야 한다"고 강조했다.
글로벌 IT기업들이 올해 들어 매개변수가 적어도 품질 좋은 데이터셋으로 성능을 높인 초거대 AI 모델을 속속 내놓고 있다. 대표적인 모델로는 딥마인드의 '친칠러(Chinchilla)'와 구글의 'UL2'를 꼽을 수 있다.
이가운데 친칠러는 매개변수가 700억개에 불과하지만 지난해 딥마인드가 개발한 고퍼(Gopher)보다 테스트 성능 평균값이 높게 나타났다. 고퍼의 매개변수는 2800억개에 이른다.
구글 'UL2'도 매개변수가 200억개에 불과하지만 1750억개에 달하는 'GPT-3'보다 성능이 더 좋다는 연구 결과도 나왔다.
하 소장은 "초거대 AI모델에 쓰는 품질 좋은 데이터셋을 늘려서 매개변수를 더 최적화시킬 수 있다"며 "기업 입장에서도 모델이 비효율적으로 커지는 걸 막아 운영비용을 낮출 수 있다는 점도 확인할 수 있다"고 설명했다.
AI타임스 김미정 기자 kimj7521@aitimes.com
[관련 기사]초거대 AI 모델, 이젠 의료영상에도 적용한다
