하루가 멀다하고 새로운 기술이 쏟아져 나옵니다. 인공지능(AI)은 모든 산업 분야에 영향을 미칠 핵심 기술이 되었습니다. [찬이의 IT교실]은 AI를 비롯해 어렵고 생소한 IT 기술과 산업을 알기 쉽고 재미있게 풀어 드립니다. [편집자 주]

지난 8월 미국 콜로라도 주에서 개최한 미술경연대회에서 우승한 작품이 세간에 큰 이목을 끌었었는데요. 게임 디자이너인 제이슨 엘런씨가 ‘디지털아트 및 디지털제작 사진’ 부문에서 1등상을 받은 ‘Theatre d'Opera Spatial'라는 작품이었습니다.
그림을 글로 설명하면 이미지로 바꿔주는 ‘미드저니(Midjourney)’라는 인공지능(AI) 도구로 그린 작품이었다는게 알려지면서 논란이 됐었죠. 논란의 문제를 떠나서 AI가 그린 작품의 예술적 가치는 인정할 수 밖에 없었습니다.
이처럼 글로 명령하면 이미지를 만들어 보여주는 이미지 생성 AI가 폭발적인 인기를 끌고 있습니다. 미국 오픈AI의 ‘달리(DALL-E)’가 가장 인기있는 이미지 생성 AI입니다. 원조격이지요. 지난해 1월 오픈AI가 그림을 생성하는 신경망 ‘달리’를 처음 발표했을 때는 생성한 이미지가 초현실적이고 만화같기도 했습니다. 하지만 사람같은 능력을 보여주며 사람들을 놀라게 했었죠.
지난 4월 오픈AI는 기존 버전보다 훨씬 품질이 뛰어난 이미지를 생성하며, 사용법도 간단한 달리의 후속작 ‘달리2(DALL-E 2)’를 발표했습니다.

달리2가 생성하는 이미지는 깜짝 놀랄 정도로 훌륭합니다. 달리2에 '말을 탄 우주비행사 이미지'나 '테디베어 과학자 이미지' '페르메이르 스타일로 그려진 해달 이미지'를 요청해 얻은 결과물은 거의 ‘포토리얼리즘’에 가까운 놀라운 품질을 자랑합니다.

달리2가 이렇게 놀라운 성능을 보일 수 있는 것은 달리의 기존 버전을 개선하지 않고 완전히 다시 설계한 덕분이라고 합니다.
기존 버전은 언어모델 GPT-3의 확장판에 가까웠습니다. 여러 면에서 GPT-3는 과한 성능을 가진 자동완성 AI에 가깝습니다. 단어나 문장 몇 개를 제시하면 그 뒤에 이어질 단어 수백 개를 예측해서 스스로 뒷부분을 채우는 식이기 때문이죠.
달리도 단지 단어를 픽셀로 바꿨을 뿐 대체로 비슷한 방식을 사용합니다. 달리는 텍스트로 된 메시지를 입력하면 다음에 올 가능성이 가장 큰 것으로 예측되는 픽셀을 채우는 방식으로 텍스트를 완성해서 이미지를 생성했습니다.
그러나 달리2는 GPT-3를 기반으로 하지 않습니다. 달리2의 원리를 살펴보면 크게 두 단계로 나눌 수 있는데요. 우선 언어모델 ‘클립(CLIP)’을 사용해 명령어를 이미지와 짝지을 핵심 특징을 담은 중간 형태의 텍스트로 변환합니다. 그런 다음 ‘확산모델’이라는 신경망을 이용해 클립을 만족시키는 이미지를 생성합니다.
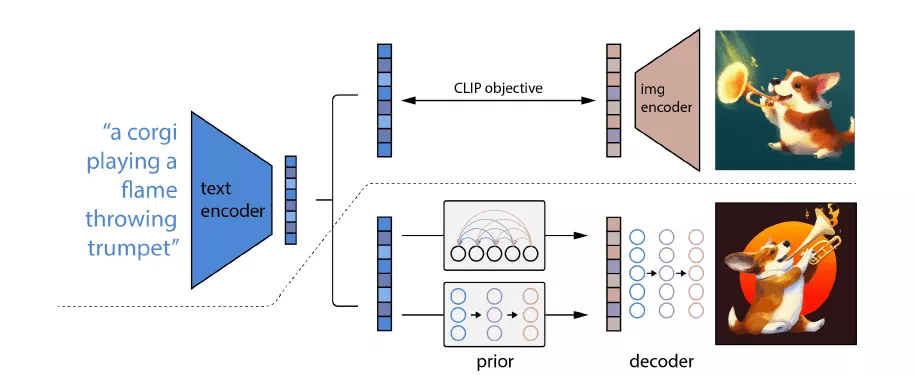
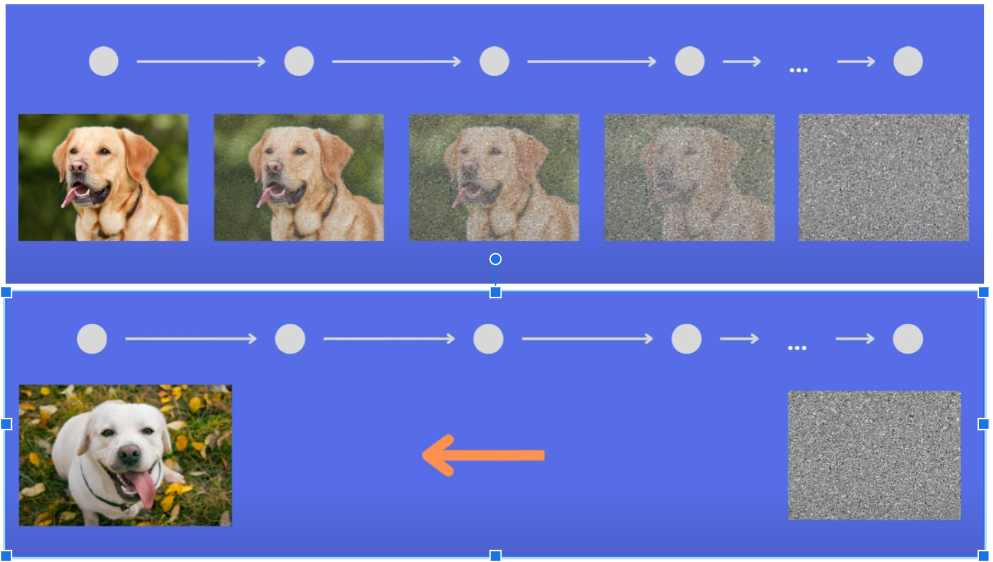
확산모델은 무작위로 선택된 픽셀로 이루어진 완전히 왜곡된 이미지를 이용해 학습합니다. 왜곡된 이미지를 원래 형태로 되돌리는 방법을 배우는 것이죠.
달리2에는 참조할 수 있는 원본 이미지가 없기 때문에 확산모델은 임의의 픽셀을 골라서 왜곡된 이미지를 만들고, 클립의 도움을 받으며 그 이미지를 완전히 새로운 이미지로 전환합니다. 입력된 텍스트에 부합하도록 처음부터 완전히 새로운 이미지를 만드는 것입니다.
물론 달리2도 여전히 실수를 하기도 합니다. 예를 들어 ‘파란 정육면체 위에 놓인 빨간 정육면체’처럼 둘 이상의 대상을 둘 이상의 속성과 결합하라고 요청하면 결과물 생성을 힘들어 합니다. 이것이 클립이 항상 속성과 대상을 정확하게 연결하는 것은 아니기 때문이죠.

텍스트에 따라 새로운 이미지를 생성하는 것뿐만 아니라 달리2는 기존 이미지를 다양하게 변형한 이미지를 만들어낼 수도 있습니다. 기존 이미지를 달리2에 연결하면 달리2는 즉시 다양한 화풍으로 해당 사진을 변형한 이미지들을 생성하기 시작합니다.
달리2는 이미지를 업로드하고 합성해 크기를 확장할 수 있는 ‘아웃페인팅’이라는 기능도 갖췄습니다. 또 스타일을 혼합하고, 사진 사이에 시각적 브리지를 생성해 여러 사진을 하나로 병합할 수도 있어요.
현재 오픈AI는 '달리' '달리2' 등으로 나누었던 브랜드를 최근 '달리'로 통합하고, 달리를 누구나 사용할 수 있도록 대중에게 제한없이 전면 공개했습니다.
박찬 위원 cpark@aitimes.com
