
인공지능(AI)을 활용한 데이터 압축이 기존 데이터 압축 알고리즘보다 더 효과적이라는 연구 결과가 나왔다. 이는 대형언어모델(LLM)이 언어처리와 예측뿐만 아니라 데이터 압축에도 효과적인 도구가 될 수 있다는 것을 시사한다.
딥마인드는 최근 '언어 모델링은 압축이다'라는 제목의 아카이브(arXiv) 연구 논문에서 자체 LLM '친칠라 70B(Chinchilla 70B)'가 이미지넷(ImageNet) 데이터베이스의 이미지에 대해 원래 크기의 43.4%로 무손실 압축을 수행할 수 있으며, 이는 PNG 알고리즘으로 기록한 압축률 58.5%를 능가한다는 사실을 밝혔다.
효과적인 압축은 정보 손실 없이 데이터를 더 작게 만드는 패턴을 찾는 것이다. 알고리즘이나 모델이 다음 데이터 조각을 정확하게 예측할 수 있으면, 이러한 패턴을 잘 찾아낼 수 있다.
이에 따르면 친칠라 70B는 오디오의 경우 라이브리스피치(LibriSpeech) 데이터셋의 오디오 데이터를 원래 크기의 16.4%로 압축, FLAC 알고리즘보다 30.3% 더 뛰어났다. 또 텍스트 압축에서 원래 텍스트 크기를 8.3%로 압축해 각각 32.3%와 23%로 압축한 gzip 및 LZMA2보다 월등한 성능을 보였다.
압축률이 낮을수록 압축이 더 많이 발생한다. 또 무손실 압축은 압축 프로세스 중에 데이터가 손실되지 않음을 의미한다. 압축 파일 크기를 크게 줄이기 위해 복구 프로세스 중에 일부 데이터를 버리고 근사치를 사용해 일부 데이터를 재구성하는 JPEG와 같은 손실 압축 기술과는 대조된다.
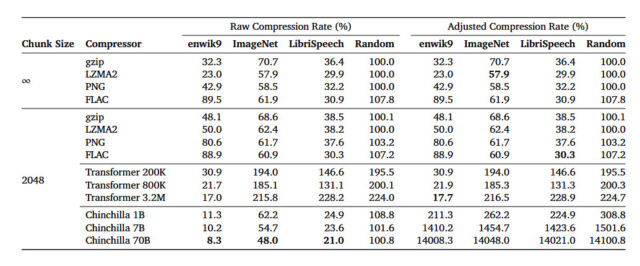
연구 결과에 따르면 친칠라 70B는 주로 텍스트를 처리하도록 훈련했지만, 다른 유형의 데이터를 압축하는 데에도 놀라울 정도로 효과적이며 기존 압축 알고리즘보다 더 나은 경우가 많았다.
이는 LLM이 텍스트 예측 및 작성을 위한 도구일 뿐만 아니라 다양한 유형의 데이터 크기를 줄이는 효과적인 방법으로 사용될 수 있다는 것을 보여준다.
하지만 이런 결과에도 불구하고 LLM을 실용적인 압축 도구로 보기는 어렵다. 전통적인 압축 알고리즘은 수백킬로바이트(KB)를 넘지 않는 소형이다. 반면 LLM은 크기가 수백기가바이트(GB) 이상일 수 있으며 실행 속도도 느리다.
예를 들어 gzip이 CPU에서 1분 이내에 1GB의 텍스트를 압축할 수 있지만, 320만개의 매개변수가 있는 LLM은 동일한 양의 데이터를 압축하는 데 1시간이 필요하다.
또 연구진은 더 큰 모델이 더 큰 데이터셋에서 뛰어난 압축률을 기록하지만, 더 작은 데이터셋에서는 성능이 저하된다는 사실도 발견했다. "모델 크기가 어떤 임계점을 넘어선 후에는 데이터셋이 작을 경우 압축률이 다시 증가하기 시작한다"라고 밝혔다.
이는 더 큰 모델이 모든 종류의 작업에 반드시 더 나은 것은 아니라는 것을 의미한다. 결과적으로 압축은 모델이 데이터셋의 정보를 얼마나 잘 학습하는지 나타내는 지표 역할을 할 수 있다.
한편 지난 20년 동안 일부 컴퓨터 과학자들은 효과적인 데이터 압축이 일반 지능의 한 형태와 유사하다고 주장해 왔다. 주변 세계를 이해하는 데 종종 좋은 데이터 압축과 유사한 프로세스로 패턴을 식별하고 복잡성을 이해하는 것이 필요하다는 것이다. 필수 정보를 유지하면서 대규모 데이터셋을 보다 컴팩트한 형태로 압축하는 것은 데이터 자체에 대한 일종의 이해 또는 표현을 나타낸다는 설명이다.
딥마인드 논문의 저자 중 한 명인 마커서 허터의 이름을 딴 이 ‘허터 프라이즈(Hutter Prize)는 영어 텍스트셋을 가장 효과적으로 압축한 사람에게 수여된다. 기본 전제는 텍스트를 매우 효율적으로 압축하려면 인간이 언어를 이해하는 방식과 유사하게 언어의 의미론적 및 구문론적 패턴을 이해해야 한다는 것이다.

딥마인드 연구진은 예측과 압축 사이의 관계도 실험했다. 그들은 gzip과 같은 좋은 압축 알고리즘이 있다면 이를 뒤집어 압축 과정에서 배운 내용을 기반으로 새로운 원본 데이터를 생성하는 데 사용할 수 있다고 주장했다.
실험에서 연구진은 gzip과 친칠라를 사용하여 조건을 지정한 후 데이터 시퀀스에서 다음에 무엇이 나올지 예측함으로써 텍스트, 이미지, 오디오 등 다양한 형식에 걸쳐 새로운 데이터를 생성하는 실험을 수행했다. 그 결과 gzip은 무의미한 출력을 생성하는 반면, 언어 처리를 위해 특별히 설계한 친칠라는 일관성 있는 데이터를 생성하는 데 훨씬 더 나은 성능을 보였다.
AI 언어 모델 압축에 관한 딥마인드 논문은 데이터를 다양한 형식으로 압축하는 데 중요한 역할을 할 수 있음을 보여준다. 압축과 지능의 관계는 계속해서 연구되고 있는 분야이며, 앞으로 이 주제에 대한 추가 연구가 기대된다.
박찬 기자 cpark@aitimes.com
