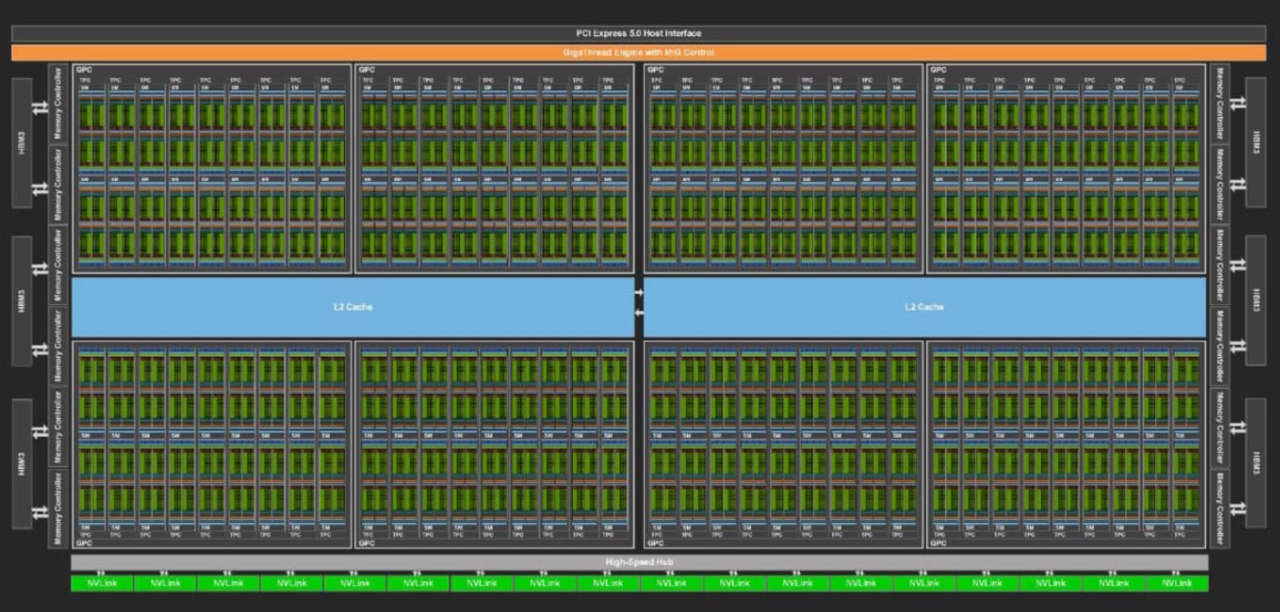
엔비디아가 30년 동안 수집한 데이터로 챗봇을 학습, 반도체 설계 노하우를 갖춘 챗봇을 선보였다. 전문 기업이 내부 데이터로 훈련된 대형언어모델(LLM)을 활용해 생산성을 향상하는 어시스턴트 구축 방법을 제시했다는 평가다.
벤처비트는 30일(현지시간) 엔비디아가 반도체 설계 소프트웨어를 생성 및 최적화하고 인간 설계자를 지원하기 위해 회사 내부 데이터로 학습한 맞춤형 LLM ‘칩니모(ChipNeMo)’에 관한 논문을 'CAD 국제회의'에서 발표했다고 보도했다.
이에 따르면 엔비디아는 생성 AI를 칩 설계의 모든 단계에 적용해 전반적인 생산성을 향상할 목적으로 칩니모를 개발했다.
빌 댈리 엔비디아 수석 과학자는 “이러한 노력은 LLM을 반도체 설계의 복잡한 작업에 적용하는 중요한 첫 단계”라며 "이는 고도로 전문화된 분야에서도 내부 데이터를 사용하여 유용한 생성 AI 모델을 훈련할 수 있는 방법을 보여준다"라고 말했다.
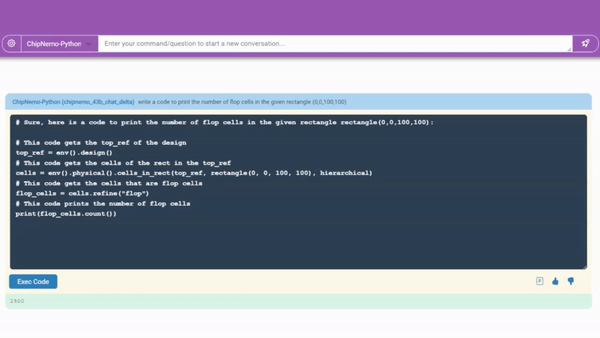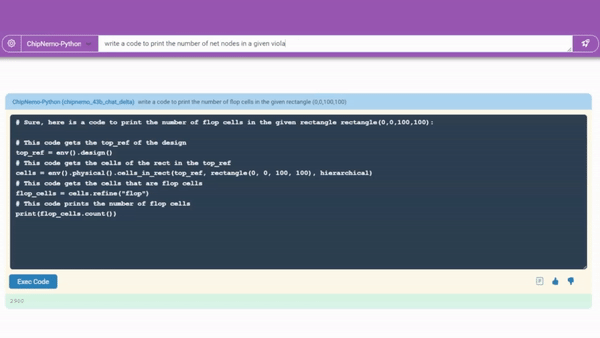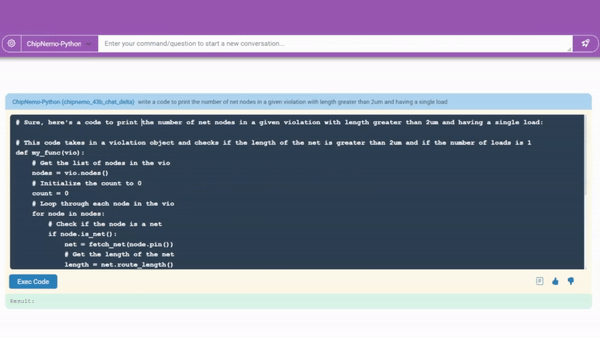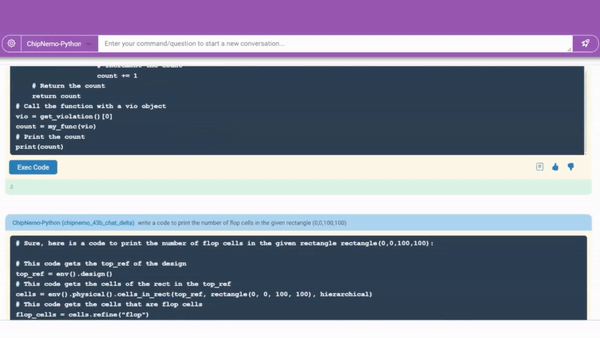
엔비디아는 칩니모의 대표적인 사용 사례로 ▲챗봇과 ▲코드 생성기 ▲분석 도구 등을 꼽았다.
그중 버그에 대한 설명을 업데이트하고 유지 관리하는 등 시간이 많이 걸리던 작업을 자동화하는 분석 도구가 가장 호평받았다.
또 GPU 아키텍처 및 설계에 대한 질문에 응답하는 프로토타입 챗봇은 엔지니어가 기술 문서를 빠르게 찾는 데 도움이 됐다는 평이다.
코드 생성기는 이미 칩 설계자가 사용하는 전문 언어인 ‘VHDL’ 및 '베릴로그(Verilog)’로 약 10~20줄의 소프트웨어 조각을 생성한다. 기존 도구와 통합되기 때문에 엔지니어는 진행 중인 설계를 위한 편리한 도우미를 갖게 된다.
논문이 반도체에 한정된 것이 아니라 설계 데이터를 수집하고 전문적인 생성 AI 모델을 만들기 위한 작업에 중점을 뒀다는 것도 주목할 점이다. 즉, 이 프로세스는 모든 산업에 적용될 수 있다.
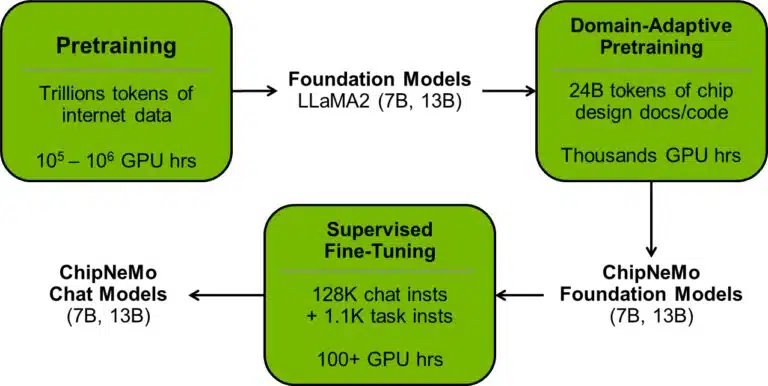
연구진은 파운데이션 모델을 기반으로 생성 AI 모델을 구축, 사용자 정의 및 배포하기 위한 프레임워크인 ‘엔비디아 니모(Nvidia Nemo)’를 사용해 모델을 개선했다.
먼저 기반 모델을 선택하고 1조개가 넘는 토큰, 텍스트와 소프트웨어의 단어와 기호를 사용해 사전 훈련한 다음, 두번의 훈련 라운드를 통해 모델을 개선했다. 첫번째는 약 240억개의 토큰이 있는 내부 설계 데이터를 사용했고, 두번째는 약 13만개의 대화 및 설계 사례를 혼합해 모델을 개선했다.
이 연구는 전문 기술팀이 자체 데이터를 사용하여 사전 학습된 모델을 어떻게 개선할 수 있는지 보여준다. 학습 과정에서는 신중한 데이터 수집 및 정리가 중요하며, 사용자는 작업을 단순화하고 신속하게 처리할 수 있는 최신 도구에 대한 최신 정보를 계속 업데이트하는 것이 좋다는 결론이다.
자체 맞춤형 LLM을 구축하려는 기업은 깃허브 및 엔비디아 NGC 카탈로그에서 제공하는 니모 프레임워크를 활용할 수 있다.
박찬 기자 cpark@aitimes.com
