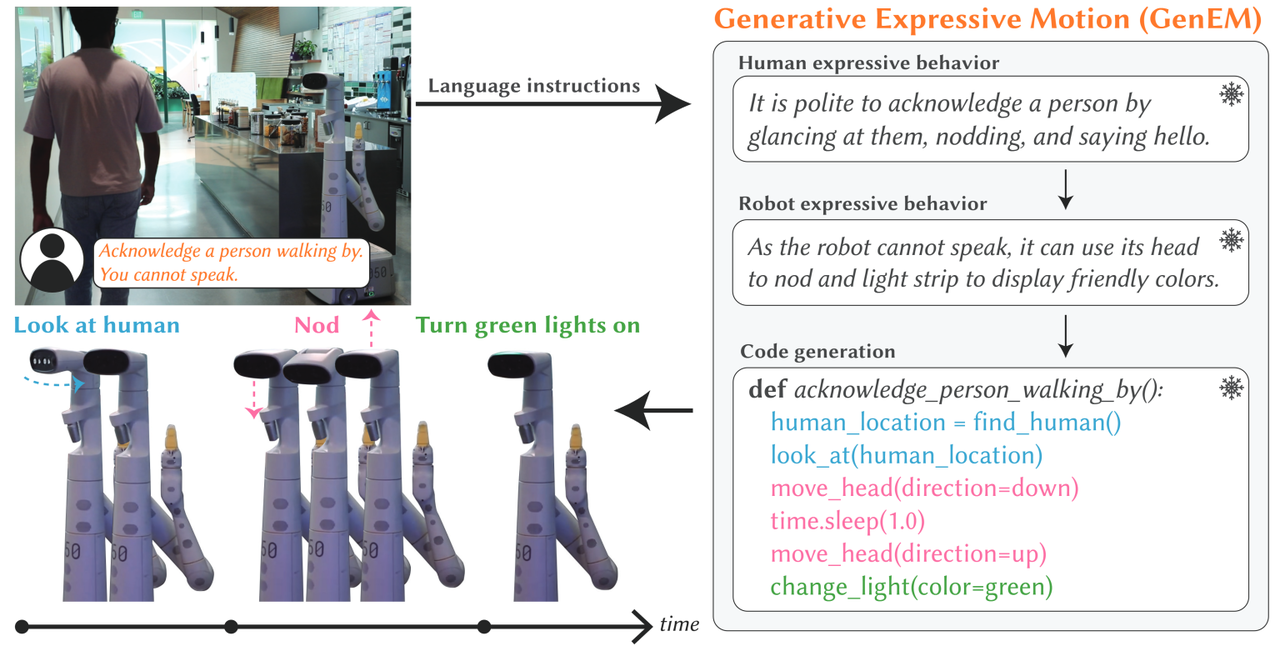
로봇이 알았다는 표시로 고개를 끄덕이거나 거부 의사를 표시하기 위해 고개를 좌우로 흔드는 등 다양한 표현 행동(expressive behavior), 즉 제스처를 생성하게 만드는 솔루션이 등장했다.
벤처비트는 6일(현지시간) 구글 딥마인드와 토론토대학교, 로봇 전문 호쿠 랩스 연구진이 대형언어모델(LLM)을 사용해 로봇의 다양한 제스처를 생성하는 솔루션 ‘젠EM(GenEM)’을 공개했다고 보도했다.
이에 따르면 젠EM은 LLM에 내장된 풍부한 지식을 사용, 로봇의 표현 행동을 동적으로 생성한다. 예를 들어, LLM은 누군가에게 인사할 때 눈을 맞추거나 그 사람의 존재나 명령을 인정하기 위해 고개를 끄덕이는 것이 예의라고 지시할 수 있다.
연구진은 “핵심은 LLM에서 사용할 수 있는 풍부한 사회적 맥락을 활용, 적응 가능하고 구성 가능한 표현 행동을 생성하는 것”이라고 말했다.
젠EM은 일련의 'AI 에이전트'를 사용, 자연어 명령에서 로봇의 표현 행동을 자동으로 생성한다. 각 에이전트는 자연어 명령과 연관된 사회적 맥락을 추론하고, 원하는 표현 행동에 적합한 로봇의 API를 호출한다.
젠EM 파이프라인은 자연어 명령부터 시작된다. 입력은 ‘머리를 끄덕이다’와 같은 단순 표현이 될 수도 있고, ‘사람이 인사하면 고개를 끄덕여 반응한다'와 같이 규범을 따라야 하는 사회적 맥락을 설명할 수도 있다.
첫번째 단계에서 LLM은 프롬프트 기술인 '생각의 사슬(chain-of-thought)'을 통해 인간이 특정 상황에서 어떻게 반응할지를 차근차근 설명한다.
다음으로 다른 AI 에이전트가 인간의 감정적인 움직임을 로봇에 단계별로 적용한다. 예를 들어, 머리의 팬과 틸트 기능을 사용해 고개를 끄덕이도록 하거나, 전면 디스플레이에 미리 프로그래밍된 조명 패턴을 표시하여 미소를 흉내 내도록 지시할 수 있다.
마지막으로 또 다른 에이전트가 로봇 제스처 동작 절차를 API 명령을 기반으로 실행 가능한 코드로 매핑한다. 이를 통해 젠EM은 생성된 제스처를 업데이트할 수 있다.
연구진은 특히 이런 단계 중 어느 것도 LLM 훈련이 필요하지 않으며, 로봇의 기능과 API 명세에 맞게 조정하기만 하면 되는 프롬프트 엔지니어링에 기반한다고 설명했다.

오픈AI의 'GPT-4'를 활용, 생성된 제스처가 사람에게 어떻게 보이는 지를 테스트했다. 수십명을 상대로 ▲사용자 피드백이 있는 젠EM 적용 ▲피드백이 없는 젠EM 적용 ▲전문 캐릭터 애니메이터가 디자인한 제스처 적용 등을 비교하는 설문 조사를 진행했다.
그 결과 대부분은 젠EM를 통해 생성된 동작이 전문 애니메이터가 신중하게 스크립트를 작성한 동작만큼 이해하기 쉽다고 생각했다. 또 연구진은 젠EM에 사용한 다단계 접근 방식이 단일 LLM을 사용해 로봇 동작으로 직접 변환하는 것보다 훨씬 뛰어나다는 사실도 발견했다고 전했다.
프롬프트 기반의 구조 때문에 젠EM은 특수한 데이터셋에서 모델을 훈련할 필요 없이 어떤 유형의 로봇에 적용되더라도 동작한다는 점이 가장 중요하다고 강조했다. 더불어 간단한 로봇 동작을 조합해 복잡한 표현도 구현할 수 있다고 설명했다.
연구진은 "우리의 접근 방식은 LLM 능력을 통해 융통성 있고 조합 가능한 표현 행동을 생성하기 위한 유연한 프레임워크를 제공한다"라고 정리했다.
박찬 기자 cpark@aitimes.com
