
오픈 소스 대형언어모델(LLM)을 미세조정, 사상 처음으로 오픈AI의 'GPT-4'보다 특정 도메인에서 성능을 앞섰다는 주장이 나왔다. 테닉스라는 스타트업은 LLM의 '망각 현상'을 해결한 미세조정 기술로, 메타의 '라마 3'를 수학과 커딩 등에 최적화했다고 밝혔다.
벤처비트는 7일(현지시간) 테닉스가 라마 3를 미세조정한 '테닉스-70B' 모델로 수학과 코딩에서 GPT-4를 능가했으며, 베이스 모델의 성능을 모두 넘어섰다고 보도했다.
이타마르 아렐 테닉스 CEO는 “우리는 파운데이션 모델을 가져와서 다듬는 수준 이상으로 성능을 높이는 미세조정 기술을 개발했다”라며 "LLM의 일부 중복성을 본질적으로 활용할 수 있는 기술을 사용한 '지속 학습(continual learning)' 또는 '증분학습(incremental learning)'이라는 방식으로 모델을 개선할 수 있다"라고 말했다.
증분 학습은 모델이 기존 지식을 잊지 않고 새로운 데이터에 적응하는 것이다. LLM을 특정 데이터로 미세조정할 경우, 원래 기억하던 정보를 잊어버리는 ‘망각(catastrophic forgetting)’이라는 현상이 일어난다.
테닉스는 지난해 12월 망각 현상을 해결한 미세조정을 개발했다고 밝힌 바 있다. 이어 이 기술로 실제 오픈 소스 중 가장 규모가 큰 라마 3를 미세조정, 특정 도메인에서 뛰어난 성능을 보이도록 미세조정한 것이다.
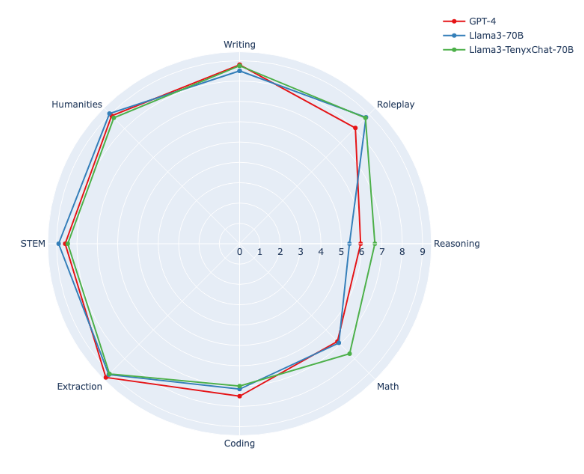
글쓰기, 추론, 수학, 코딩, STEM, 인문학 등 8개 분야의 지식을 테스트하는 MT-벤치 결과, 테닉스 70-B는 종합 점수에서 GPT-4(8.79점)와 '클로드 3 오퍼스(8.57점)'에 이어 3위(8.15점)를 기록했다.
그러나 수학과 코딩에서는 GPT-4를 앞섰다. 이에 대해 아렐 CEO는 "오픈 소스 모델로는 처음"이라고 강조했다. 특히 수학은 파운데이션 모델의 85%에 비해 96%라는 놀라운 성능 향상을 이뤘다고 강조했다.

그는 망각 문제를 해결하기 위해 매개변수의 일부만 선택적으로 업데이트, 기존 기억을 손상하지 않고 새로운 정보만 효율적으로 훈련할 수 있다고 설명했다. "예를 들어 모델 매개변수의 5%만 변경하고, 다른 모든 매개변수는 동일하게 유지된다면 망각의 위험 없이 모델을 학습할 수 있다"라고 말했다.
또 선택적 매개변수 업데이트 방법을 통해 100개의 GPU를 사용해 단 15시간 만에 700억 매개변수의 라마 3를 미세조정했다고 밝혔다.
이 회사는 미세조정 모델을 허깅페이스를 통해 오픈 소스로 공개했다. 이를 통해 개발자들이 추가적인 혁신을 촉진하길 바란다고 전했다.
임대준 기자 ydj@aitimes.com
