
중국 인공지능(AI) 스타트업 딥시크가 오픈 소스 코드 생성 AI 모델을 출시했다. 딥시크는 새로운 모델이 코딩 및 수학 작업에서 'GPT-4 터보', '클로드 3 오퍼스', '제미나이 1.5 .프로' 등 SOTA(State-of-the-art, 최고 수준) 모델보다 성능이 뛰어나다고 주장했다.
벤처비트는 16일(현지시간) 딥시크가 ‘전문가 혼합(MoE)’ 기반의 코드 생성 AI 모델 ‘딥시크 코더 V2’를 오픈 소스로 출시했다고 보도했다.
딥시크 코더 V2는 338개의 프로그래밍 언어를 지원하고, 12만8000 토큰 길이의 컨텍스트 창을 제공한다.
특히 단일 모델이 아닌, 사전 훈련을 통해 상황별로 모델 여럿을 MoE 방식으로 조합했다. 이를 통해 매개변수 160억(16B) 및 2360억(236B) 등 제품군을 구성했다. 이 모델은 작동하면 24억 및 210억개의 매개변수만 활성화한다.
이 모델은 대형언어모델(LLM)의 코드 생성, 편집 및 문제 해결 기능을 평가하도록 설계된 MBPP+, 휴먼이밸 및 아이더 벤치마크에서 테스트했을 때 각각 76.2, 90.2 및 73.7점을 받았다. 이는 GPT-4 터보, 클로드 3 오퍼스, 제미나이 1.5 프로, 코데스트랄(Coestral) 및 라마3 70B 등 대부분의 폐쇄형 및 오픈 소스 모델보다 뛰어난 수치다.
모델의 수학적 기능을 평가하도록 설계된 매쓰(MATH) 및 GSM8K 벤치마크에서도 유사한 성능을 기록했다.
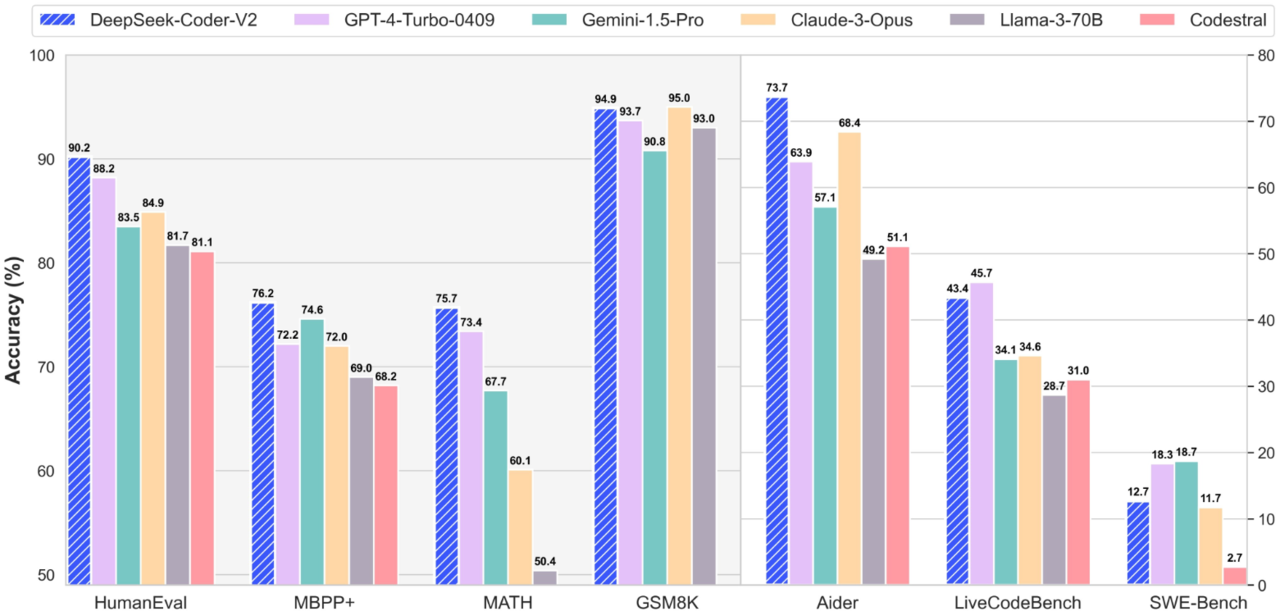
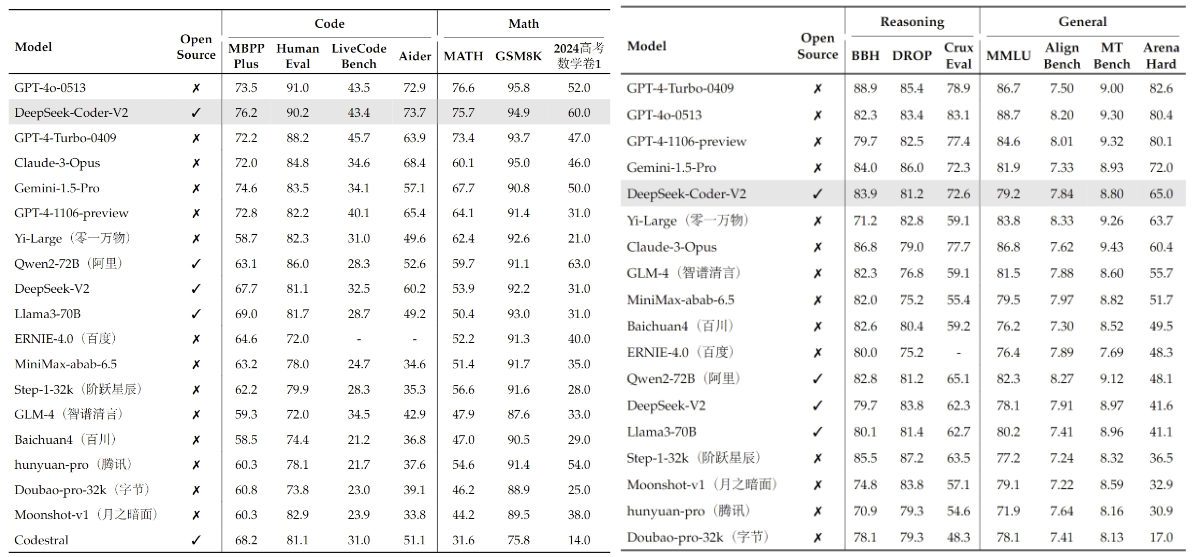
여러 벤치마크에서 딥시크 코더 V2의 성능을 능가한 모델은 'GPT-4o' 하나뿐이다. 휴먼이밸, 라비브코드 벤치, 매쓰 및 GSM8K에서 약간 더 높은 점수를 얻었다.
딥시크은 MoE 방식을 사용해 이런 성능 향상을 달성했다고 밝혔다. 또 깃허브와 커몬크롤(CommonCrawl)이 수집한 코드 및 수학 관련 6조개 토큰 데이터셋으로 V2 기본 모델을 사전 학습했다고 밝혔다.
코딩 및 수학 관련 작업에 탁월한 성능을 발휘하는 것 외에도 딥시크 코더 V2는 일반적인 추론 및 언어 이해 작업에서도 상당한 성능을 제공한다는 설명이다.
예를 들어, 여러 작업에 걸쳐 언어 이해를 평가하도록 설계된 MMLU 벤치마크에서는 79.2점을 받았다. 이는 다른 코드 생성 모델보다 훨씬 뛰어나며, 라마-3 70B의 80.2점과 비슷하다. GPT-4o와 클로드 3 오퍼스는 각각 88.7점과 86.8점을 받아 MMLU 카테고리에서 1, 2위를, GPT-4 터보가 86.7점으로 3위를 기록했다.
이는 오픈 소스 코드 생성 LLM이 마침내 최첨단 폐쇄형 모델에 근접했음을 보여주는 결과라는 주장이다.
현재 딥시크 코더 V2는 허깅페이스를 통해 연구 및 상업적 용도로 무제한 사용가능하다. 또 딥시크 플랫폼에서 종량제 모델에 따라 API를 통해 모델에 액세스할 수 있다. 챗봇을 통해 모델의 기능을 먼저 테스트해 볼 수도 있다.
박찬 기자 cpark@aitimes.com
