
오픈AI가 'GPT-4'가 생성한 코드의 오류를 식별하는 모델을 공개했다. 이를 통해 인공지능(AI)의 성능 향상으로 사람들이 평가하기 어려울 수 있는 AI 출력 문제까지도 감지할 수 있게 됐다.
오픈AI는 27일(현지시간) GPT-4를 활용해 GPT-4가 생성한 코드에서 오류를 식별하는 모델인 ‘크리틱GPT(CriticGPT)’에 관한 논문을 소개했다.
크리틱GPT는 인간 트레이너가 대형언어모델(LLM)의 출력을 평가하는 ‘인간 피드백 강화학습(RLHF)’ 과정에 통합, 인간이 발견하지 못하는 오류나 환각을 식별한다.
추론 및 모델 행동이 향상됨에 따라 '챗GPT'는 더 정확해지고 실수는 더 미묘해져서 감지하기 쉽지 않다. 인간 트레이너가 부정확한 부분을 식별하기 어렵게 만들 수 있으며, RLHF 작업을 훨씬 더 어렵게 만든다.
이는 RLHF의 근본적인 한계로, 모델이 점차 피드백을 제공할 수 있는 어느 누구보다 더 많은 지식을 갖추게 됨에 따라 모델 정렬(alignment)을 더 어렵게 만들 수 있다. 정렬은 AI 분야에서 AI 시스템을 인간이 의도한 목표, 선호도 또는 윤리적 원칙에 맞게 조정하는 것을 의미한다.

이 문제를 해결하기 위해 오픈AI는 챗GPT의 답변에서 부정확성을 강조하는 비평을 작성하도록 크리틱GPT를 훈련goT다.
오픈AI는 크리틱GPT가 소프트웨어에 자주 나타나는 다양한 코딩 오류를 인식하고 표시하는 방법을 배우도록, 의도적인 버그가 포함된 코드 샘플 데이터셋으로 훈련했다.
훈련 과정에서 인간 트레이너들에게 챗GPT가 작성한 코드에 수동으로 오류를 삽입하고, 마치 자신이 실제로 버그를 발견한 것처럼 샘플 피드백을 작성하도록 요청했다. 이를 통해 크리틱GPT가 수동으로 삽입된 버그와 자연적으로 발생하는 챗GPT 버그를 모두 잡아낼 수 있는지 연구했다.
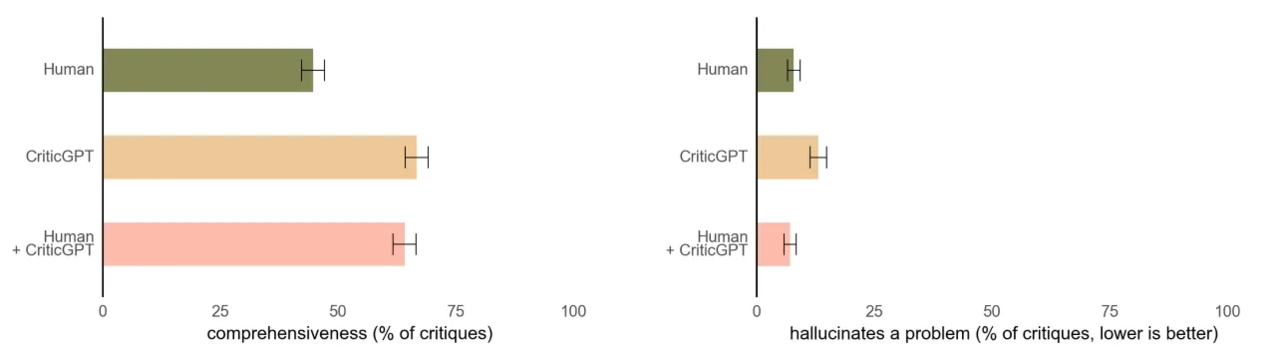
그 결과, 크리틱GPT는 인간 트레이너들이 작성하는 것보다 더 포괄적인 비평을 작성하도록 도와주는 것으로 나타났다. 또 인간 트레이너와 크리틱GPT으로 작성한 비평이 크리틱GPT만으로 작성한 비평보다 환각을 덜 발생시키는 것으로 나타났다.
인간 트레이너들은 인간이 작성한 비평보다 크리틱GPT가 작성한 비평을 63% 더 선호했다. 오픈AI에 따르면, 이는 부분적으로 크리틱GPT가 사소한 불만을 덜 제기하고 잘못된 답을 옳다고(false positive) 잘못 지적하는 일이 적기 때문이다.
또 크리틱GPT는 인간 주석자가 ‘완벽하다’고 표시한 훈련 데이터셋에 대해서도 여전히 24%의 데이터셋에서 버그와 오류를 발견했다.
더 복잡해지는 AI 시스템을 정렬하려면 더 나은 도구가 필요하다는 설명이다. 오픈AI는 크리틱GPT를 RLHF 파이프라인에 통합하고 확장해 실용화할 계획이다.
박찬 기자 cpark@aitimes.com
