
구글 딥마인드가 '제미나이'를 사용해 로봇이 주변 환경을 학습해 명령을 수행할 수 있도록 안내하는 내비게이션 로봇 모델을 구축했다. 기존 모델을 최신 모델 기반으로 업그레이드한 것으로, 이를 통해 향상된 인간과의 소통과 비디오 분석, 추론 능력 등을 갖추게 됐다.
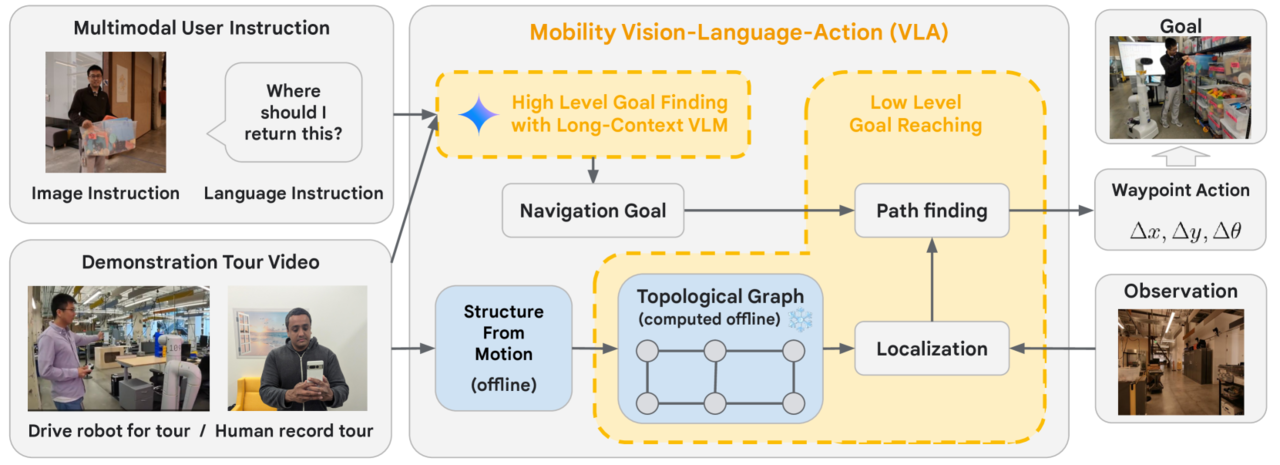
더 버지는 11일(현지시간) 구글 딥마인드 로보틱스 팀이 제미나이 1.5 프로를 결합해 로봇이 훨씬 적은 훈련으로 다양한 환경에서 명령을 수행할 수 있도록 안내하는 내비게이션 시각-언어-행동(VLA) 모델 논문을 아카이브에 게재했다고 보도했다.
이는 사람이 집이나 사무실 공간과 같은 공간을 로봇과 둘러보며, 비디오를 촬영하고 음성으로 사물을 일러주는 식으로 주변 환경을 학습한다.
로봇은 글이나 그림, 제스처 등 인간의 지시를 멀티모달로 받아들여, 제미나이의 긴텍스트 창을 활용해 촬영된 비디오에서 목표 프레임을 찾고 명령을 수행할 수 있도록 안내하는 일련의 로봇 동작을 생성한다.
예를 들어 사용자가 로봇에 휴대폰을 보여주고 '어디서 충전할 수 있나'라고 질문하면, 로봇이 직전에 녹화한 비디오를 분석해 전원 콘센트로 안내해주는 식이다.
딥마인드는 9000평방피트 이상의 작업 공간에서 50개 이상의 사용자 명령에 대해 제미나이 기반 로봇이 90%의 성공률을 보였다고 밝혔다.

이는 구글이 기존에 출시한 로봇 모델 'RT-2'를 제미나이의 채팅 기능과 큰 컨텍스트 창을 통한 빠른 분석 기능, 향상된 추론 기능 등을 더해 업그레이드한 것이다.
연구진은 "제미나 1.5 프로가 단순한 내비게이션을 넘어, 지시를 이행하는 방법을 계획할 수 있도록 도와줄 수 있다"라고 밝혔다.
예를 들어, 책상 위에 많은 콜라 캔을 둔 사용자가 로봇에게 자신이 좋아하는 음료를 가져달라고 요청하면, 제미나이는 로봇이 냉장고로 이동해 콜라가 있는지 확인한 후 결과를 보고하기 위해 사용자에게 돌아와야 한다는 것을 지시한다는 것이다.
다만, 연구 논문에 따르면 로봇이 각 요청을 처리하는 데 약 10~30초가 걸리는 것으로 드러났다.
박찬 기자 cpark@aitimes.com
