KT가 사용자가 제시하는 이미지의 맥락을 잘 이해, 개인화 및 장기 기억에 도움을 주는 인공지능(AI) 챗봇용 기술을 공개했다. 구체적인 사업 목적을 위한 것은 아니라고 밝혔으나, 이를 통해 정교한 맞춤형 챗봇 서비스가 가능하다는 추측이 가능해진다.
마크테크포스트는 15일(현지시간) KT와 한국과학기술원(KAIST)이 멀티모달 대화 모델 '울트론 7B(Ultron 7B)'와 이를 훈련하기 위해 사용한 대규모 장기 멀티모달 대화 데이터셋 '스타크(Stark)'를 공개했다고 소개했다. 영화 '아이언맨'에 등장하는 이름을 사용한 게 눈에 띈다.
인간-컴퓨터 상호작용(HCI), 즉 AI 챗봇의 주요 과제 중 하나는 사용자와의 대화에서 장기적이고 개인화된 상호작용을 유지하는 것이다. 그러나 연구진은 기존 챗봇이 이미지에 대한 이해가 떨어지고 단발성에 그쳐, 사용자의 정보나 선호 등을 파악하는 데 어려움을 겪었다고 지적했다.
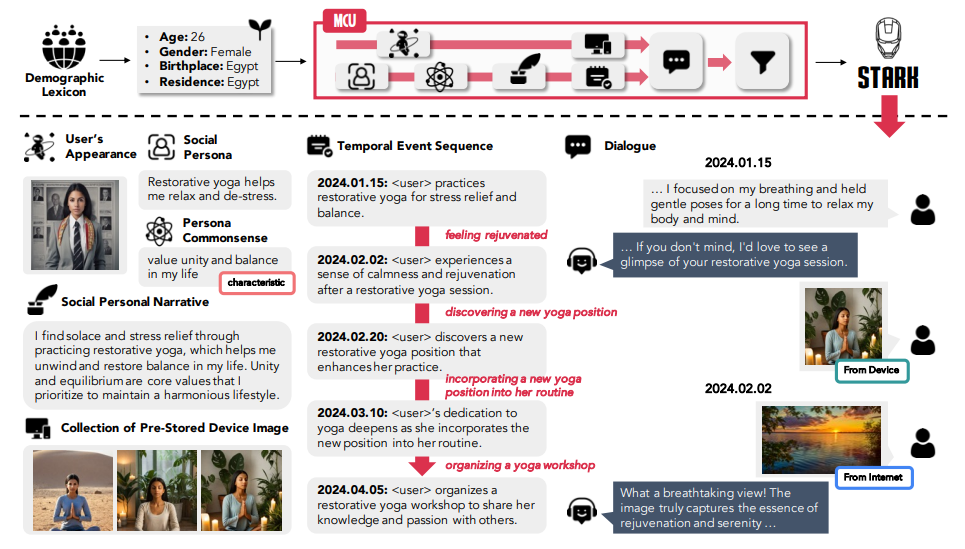
이런 한계를 해결하기 위해 연구진은 '챗GPT'와 새로운 이미지 정렬기를 활용, 장기 기억을 갖춘 멀티모달 챗봇 프레임워크를 구축했다. 이를 멀티모달 맥락 프레임워크(multi-modal contextualization framework), 즉 'MCU'라고 명명했다.
구체적으로 MCU 프레임워크는 연령, 성별, 출생지, 거주지와 같은 인구 통계 정보를 기반으로 소셜 페르소나 속성을 생성하는 것으로 시작한다. 이어 가상의 인간 얼굴을 만들고 페르소나 상식 지식을 생성한다. 그다음 개인 서사와 시간적 이벤트 시퀀스를 생성, 텍스트와 이미지를 정렬하는 멀티모달 대화로 마무리한다. 이 프로세스를 통해 대화의 맥락과 일관성이 풍부해진다는 설명이다.
이를 통해 다양한 인물이 등장하고 시대의 흐름을 반영하는 스타크라는 데이터셋을 구축했다. 이를 학습하면, LLM이 사용자가 채팅 중 제시하는 이미지나 문맥을 잘 이해하고 기억해 개인화와 연속성을 향상한다는 설명이다.
스타크(Social long-term multi-modal conversation with personal commonsense Knowledge)는 2021년부터 2024년 동안에 일어난 다양한 사건과 인물에 대한 이미지와 이를 설명하는 50만개 이상의 관련 대화가 포함한 포괄적인 데이터셋이다. 국내뿐 아니라 다양한 국가와 연령대, 성별에 대한 이미지로 편향 가능성도 줄였다는 설명이다.
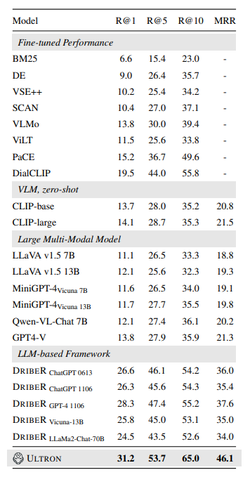
연구진은 스타크를 사용해 멀티모달 챗봇 모델 울트론 7B를 훈련, 인상적인 시각적 이해도를 보여주는 데 성공했다고 밝혔다.
인간 선호도 평가와 고품질 데이터셋과의 직접 비교를 통해 테스트했다. 스타크는 일관성 측면에서 높은 점수를 받았으며, 자연스러운 대화의 흐름과 참여도 등 멀티모달 대화의 전반적인 품질에서 다른 단일 세션 데이터셋보다 우수한 성적을 거뒀다고 밝혔다.
연구진은 울트론 7B의 소스 코드와 스타크 데이터셋을 오픈 소스로 공개했다.
이에 대해 KT 측은 "특정 사업 목적은 아니고, 연구개발단에서 연구 성과를 발표한 것"이라고 밝혔다.
한편, 전날 삼성전자 연구진이 온디바이스 AI에 가드레일을 효과적으로 적용하는 기술을 발표하는 등 국내 AI 대기업들의 연구가 잇달아 공개되고 있다. LLM에 대한 연구가 가속화되고 있다는 증거다.
박수빈 기자 sbin08@aitimes.com
