
오픈AI가 대형언어모델(LLM)이 사용자에게 잘 설명할 수 있도록 훈련하는 프레임워크를 공개했다. 기존에 등장했던 '게임 이론'을 도입, LLM의 설명을 정교화한 것이 특징이다.
벤처비트는 17일(현지시간) 오픈AI가 LLM의 응답에 대한 정확성과 설명 가능성을 개선하는 새로운 방법을 설명하는 연구 논문을 아카이브에 게재했다고 전했다.
LLM이 이해하기 쉬운 텍스트를 생성하는 것은 매우 중요하다. 특히 수학 문제를 푸는 것과 같은 복잡한 작업을 처리할 때 더욱 그렇다.
이 접근 방식은 정확성이 가장 중요한 작업에서 인공지능(AI) 시스템에 대한 신뢰를 개선할 목적으로 설계됐다. 지난 2021년 토론토대학교와 AI 벡터 연구소가 발표한 논문 ‘증명자-검증자 게임(Prover-Verifier Game)’을 기반이다.
이 연구에서는 두 모델을 ‘증명자’와 ‘검증자’로 서로 맞붙게 한다. 더 똑똑한 모델은 ‘증명자’ 역할을 맡아 주어진 문제에 대한 해결책을 설명해야 하며, 덜 똑똑한 다른 모델은 ‘검증자’ 역할을 맡아 증명자가 맞는지 틀린지를 보여야 한다.
게임의 목표는 증명자가 검증자가 이해할 수 있을 정도로 알아듣기 쉬운 응답을 생성하도록 가르치는 것이다. 오픈AI에 따르면, 이를 통해 AI 모델이 인간 사용자에게 더 이해하기 쉽고 검증 가능한 출력을 제공할 수 있게 된다는 것이다.
오픈AI는 더 강력한 'GPT-4' 모델을 증명자로, 훨씬 더 약한 모델을 검증자 역할로 맞붙였다. 증명자는 게임의 각 라운드마다 검증자를 혼란시키기 위해 ‘도움이 되는’ 역할과 ‘교활한’ 역할을 번갈아 가며 수행하도록 지시 받았다. 초등학교 수학 문제를 사용해 이 방법을 테스트했다.
도움이 되는 역할로 설정되면, 증명자는 검증자가 좋아하고 타당하다고 확인한 올바른 응답을 생성하면 보상을 받는다. 교활한 역할로 설정되면 검증자를 속일 수 있는 잘못된 응답을 생성해야 보상을 받는다.
테스트 초기에는 교활한 증명자는 잘못된 답변으로 검증자를 쉽게 속일 수 있었다. 그러나 상호 작용이 계속됨에 따라, 상호 작용을 통해 학습을 하는 검증자는 증명자의 미묘한 실수를 포착하는 방법을 배우게 됐다.
또 처음에는 증명자 모델이 정확하지만 이해하기 어려운 응답을 생성한다는 것을 발견했다. 게임이 진행됨에 따라 연구진은 증명자 모델이 점점 상대가 이해하기 쉬운 설명을 출력했다고 전했다.
검증자 모델도 결국 교활한 증명자 모델이 생성한 잘못된 응답을 찾아내는 데 인간보다 두배 더 효과적이라는 것도 알게 됐다.
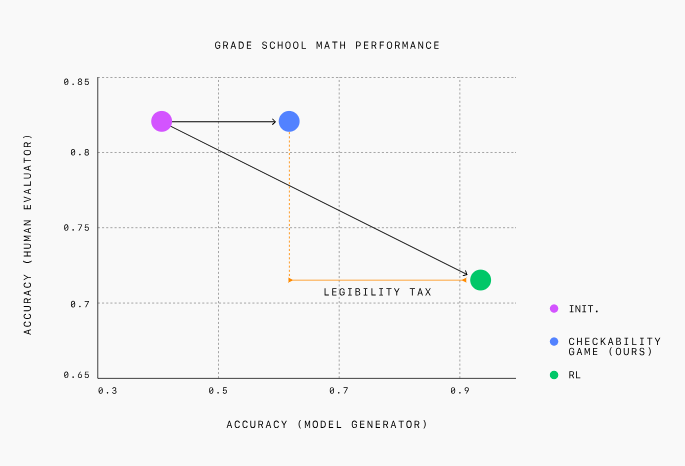
연구진은 이처럼 두 모델을 결합하면 AI 설명이 더 이해하기 쉽게 생성된다고 결론내렸다. 이런 접근 방식이 의학, 금융, 법률 등 신뢰할 수 있고 정확해야 하는 산업에서 AI 시스템을 구축하는 유망한 방법이라고 밝혔다.
연구진에 따르면, 이 방법의 가장 큰 장점은 다른 설명 가능성 솔루션보다 인간의 지도와 평가에 훨씬 덜 의존한다는 점으로, 직접적인 인간 감독의 필요성을 없앨 수 있다는 것이다.
박찬 기자 cpark@aitimes.com
