
MIT 연구진이 다양한 소스에서 얻은 방대한 양의 이질적인 데이터를 하나의 시스템에 결합, 로봇이 다양한 작업을 훈련할 수 있도록 하는 모델을 개발했다.
MIT 연구진은 2일(현지시간) 다양한 모달리티와 도메인 데이터를 통합하는 트랜스포머 기반의 인공지능(AI) 모델 ‘이질적 사전훈련 트랜스포머(HPT, Heterogeneous Pretrained Transformers)’에 관한 논문을 아카이브에 게재했다.
새로운 로봇 훈련용 모델 HPT는 'GPT-4'와 같은 대형언어모델(LLM) 훈련 방식을 모방하는 것이 특징이다.
LLM은 방대한 양의 다양한 언어 데이터를 사용해 사전훈련된 후, 소량의 특정 작업 데이터를 입력해 미세조정한다. LLM은 모든 데이터가 단순히 문장이기 때문에 이 과정이 쉽다.
그러나 로봇 데이터는 카메라 이미지와 언어 지시, 깊이 지도 등 다양한 형태다. 또 로봇마다 팔과 그리퍼, 센서의 개수와 종류가 다르며, 각 데이터는 기계적인 특성을 가지고 있으며 수집 환경도 매우 다양하다.
연구진은 "이처럼 언어모델과 달리 로봇 데이터는 이질성이 크기 때문에, LLM과 유사한 방식으로 사전 훈련을 하기 위해서는 새로운 아키텍처가 필요하다"라고 설명했다.
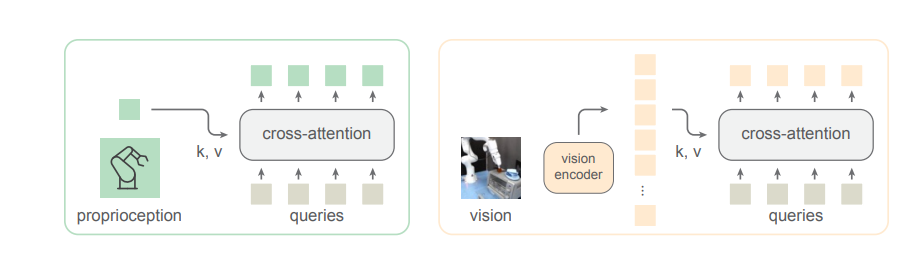
이를 위해 LLM의 핵심인 트랜스포머 아키텍처를 HPT 모델의 중심에 배치하고 여기에 로봇의 시각 및 고유 감각 입력을 처리했다.
연구진은 시각과 고유 감각 데이터를 '토큰' 입력으로 정렬해 트랜스포머가 이를 처리할 수 있도록 했다. 즉, 모든 입력은 고정된 수의 토큰으로 표현된다.
트랜스포머는 이를 하나의 공유 공간으로 매핑, 더 많은 데이터를 처리하고 학습하면서 거대한 사전훈련 모델로 성장한다. 트랜스포머가 커질수록 성능은 더 좋아진다.
사용자는 HPT에 로봇 작업에 대한 소량의 데이터만 입력하면 된다. 그러면 HPT는 사전훈련 동안 트랜스포머가 얻은 지식을 활용해 새로운 작업을 학습한다.
결국 이번 접근법은 매번 처음부터 훈련을 시작하지 않고도 로봇이 다양한 작업을 수행하도록 훈련할 수 있다는 장점이 있다.
연구진은 HPT 개발의 가장 큰 과제로 트랜스포머를 사전훈련하기 위한 방대한 데이터셋을 구축하는 것을 꼽았다.
인간 시연 영상과 시뮬레이션을 포함한 네 가지 범주의 52개 데이터셋과 20만개 이상의 로봇 궤적을 포함했다.
또 다양한 센서에서 얻은 고유 감각 신호를 트랜스포머가 처리할 수 있는 토큰으로 변환하기 위한 방법을 개발했다. 고유 감각은 다양한 움직임을 가능하게 하는 핵심 요소로, 입력 토큰 수가 항상 동일한 HPT에서는 고유 감각에 시각과 동일한 중요성을 부여한다.
이를 통해 HPT를 테스트한 결과, 매번 처음부터 훈련하는 방식보다 시뮬레이션 및 실제 작업에서 로봇 성능이 20% 이상 향상됐다. 작업이 사전훈련 데이터와 매우 다른 경우에도 HPT가 성능을 개선했다고 밝혔다.
이처럼 HPT는 다양한 분야의 데이터와 비전 센서, 로봇 팔 위치 인코더 같은 여러 모달리티 데이터를 AI 모델이 처리할 수 있는 공통 언어로 정렬함으로써, 여러 형태의 로봇에 단일 정책을 훈련하는 새로운 접근 방식을 제공한다.
연구진은 "이를 통해 다양한 데이터셋을 활용한 훈련이 가능해지며, 로봇 학습 방법이 훈련할 수 있는 데이터셋의 규모를 크게 확장할 수 있다"라고 강조했다. 또 "새로운 로봇 설계가 지속적으로 등장함에 따라 모델이 새로운 로봇 형태에 신속하게 적응할 수 있게 해준다"라고 덧붙였다.
이에 대해 데이비드 헬드 카네기멜론대학교 로봇공학 연구소 교수는 "우리의 꿈은 아무런 훈련 없이도 다운로드해 사용할 수 있는 보편적인 로봇 두뇌를 갖는 것”이라며 “아직 초기 단계지만, LLM처럼 로봇 분야에서도 획기적인 진전이 이뤄지길 기대한다"라고 말했다.
박찬 기자 cpark@aitimes.com
