
'딥시크-R1'이 벤치마크 문제를 해결하는 과정에서 난관에 부딪히자 “짜증 난다(frustrated)”고 말해 관심을 끌고 있다.
테크크런치는 16일(현지시간) 웰즐리 칼리지 등 연구진이 NPR의 선데이 퍼즐 퀴즈를 활용해 개발한 인공지능(AI) 벤치마크의 테스트 결과를 발표했다고 보도했다.
이 벤치마크에는 약 600개의 선데이 퍼즐 문제가 포함돼 있으며, 오픈AI의 'o1'과 R1 같은 추론 모델들이 다른 모델들보다 우수한 성능을 보였다.
그런데 o1을 포함한 일부 추론 모델들은 때때로 추론을 ‘포기’하고 틀린 답을 제출하는 현상을 보였다.
특히, R1은 일부 문제에서 자신이 틀린 답을 알고 있음에도 불구하고 이를 제시하는 경우가 있었다. 심지어 “포기한다”는 문구와 함께 무작위로 선택된 잘못된 답을 내놓기도 했는데, 이는 인간이 자포자기한 모습과 유사한 형태로 눈길을 끌었다.

또 모델들은 예상치 못한 행동을 보이기도 했다. 예를 들어, 잘못된 답을 낸 후 바로 이를 철회하고 더 나은 답을 찾으려 했지만, 다시 실패하는 경우가 생겼다.
또 끝없이 ‘생각’에 빠져 아무 결론도 내리지 못하거나, 정답을 즉시 찾아놓고도 불필요하게 추가적인 답을 고려하는 모습도 관찰됐다.
연구진은 “어려운 문제에서 R1이 실제로 ‘짜증 난다’고 말한 것이 흥미로웠다”라며 “모델이 인간이 할 법한 반응을 보이는 것이 인상적이었다. 다만 이러한 ‘짜증’이 추론 과정과 결과의 품질에 어떤 영향을 미치는지는 아직 명확하지 않다”라고 설명했다.
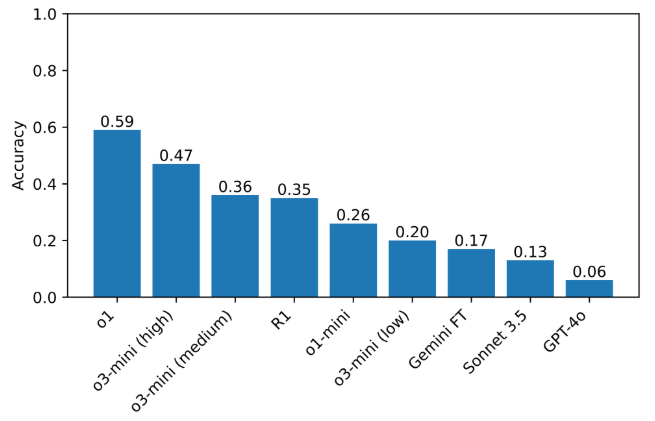
현재 이 벤치마크에서 가장 높은 점수를 기록한 모델은 59%의 성능을 보인 o1이며, 그 뒤를 47%를 기록한 'o3-미니'가 따르고 있다. R1의 점수는 35%였다.
연구진은 향후 추가적인 추론 모델을 대상으로 테스트를 진행해, 모델 성능을 개선할 수 있는 영역을 식별하는 것을 목표로 삼고 있다.
박찬 기자 cpark@aitimes.com
