
딥시크에 이어 중국의 대표 인공지능(AI) 스타트업 문샷 AI도 긴 컨텍스트를 효율적으로 처리하는 기술을 공개했다. 이번 방식은 토큰 처리에 '전문가 혼합(MoE)' 방식의 원리를 적용했다는 점에서 관심을 끌고 있다.
문샷 AI와 칭화대학교, 저장대학교 연구진은 18일 '블록 어텐션 혼합(MoBA, Mixture of Block Attention)'이라는 논문을 온라인 아카이브에 게재했다.
이는 최근 대형언어모델(LLM)의 도입이 가속화되고 산업 현장에서 긴 문서 분석에 대한 수요가 늘어나며, 장문 컨텍스트 처리에 대한 연구가 부쩍 늘어나는 가운데 등장한 것이다. 딥시크는 지난 16일 '네이티브 희소 어텐션(NSA)'이라는 방법을 공개한 바 있다.
즉, 트랜스포머 기반 LLM에서 컨텍스트 창이 커질수록 어텐션(attention) 메커니즘에 따른 메모리 사용량과 계산 시간이 급격히 증가하는 문제를 해결하는 기술이다.
트랜스포머 아키텍처는 입력 정보를 병렬로 처리하는 어텐션 메커니즘으로 인해 텍스트 시퀀스가 길어질수록 계산 시간과 메모리 비용이 기하급수적으로 증가하는 단점이 있다. 예를 들어, 입력 크기를 1000개에서 2000개로 확장하면 계산 시간과 메모리 요구 사항이 두배가 아니라 네배로 늘어난다.
트랜스포머 기본 구성 요소 중 하나인 히든 스테이트(hidden state)는 긴 데이터 목록으로, 트랜스포머가 처리한 내용을 기억하고 이를 조회 테이블처럼 사용하는 역할을 한다. 하지만 히든 스테이트는 트랜스포머의 계산 효율성을 제한하는 요소로, 새로운 정보를 처리할 때마다 이전 데이터를 다시 스캔하기 때문에 계산 부하가 커진다.
이 문제를 해결하기 위해 MoBA는 입력 데이터를 여러개의 블록으로 나누고, 각 쿼리 토큰이 가장 중요한 블록을 선택해 집중 학습한다. 이를 통해 긴 문장이나 데이터를 더 효율적으로 처리할 수 있다.
특히 '자동 선택(gating)' 메커니즘을 통해 쿼리 토큰과 각 블록 간의 유사도(affinity) 점수를 계산, 각 쿼리 토큰이 필요한 정보만 있는 블록을 선택하도록 설계됐다. 덕분에 불필요한 계산을 줄이고, 효율적인 처리가 가능하다.
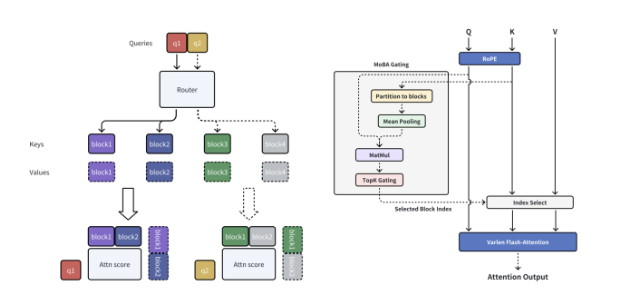
또 MoBA는 미리 정해진 규칙 없이 유연하게 작동한다는 것이 특징이다. 즉, 어떤 토큰들이 서로 영향을 주고받아야 하는지를 사람이 미리 설정하는 것이 아니라, 모델이 스스로 결정하도록 설계됐다.
이 때문에 MoBA의 어텐션 구조는 기존 트랜스포머보다 훨씬 간결하면서도, 필요한 경우에는 멀리 떨어진 정보에도 유연하게 접근할 수 있다. 예를 들어, 문장의 끝부분에서 나온 질문이 앞부분의 정보를 참고해야 할 경우, MoBA의 자동선택 메커니즘은 중요한 초기 블록을 자동으로 선택할 수 있다.
이처럼 블록 단위의 비교를 통해 토큰 간 비교 횟수를 크게 줄임으로써, 문장이나 대용량 데이터를 처리할 때 효율적인 성능을 발휘한다.
즉, 비용과 시간을 줄이기 위해 LLM을 수학, 코딩, 물리, 생물 등 각 분야를 담당하는 작은 전문 모델(Expert)로 나누고 질문에 따라 관련 없는 전문 모델은 제외하고 관련 있는 모델만을 활성화하는 ‘희소 전문가 혼합(SMoE)’ 개념을 토큰에 적용한 방식이다.
이를 통해 희소 어텐션(sparse attention)과 전체 어텐션(full attention)을 원활하게 전환, LLM의 성능을 떨어뜨리지 않고 효율성을 높인다는 결론이다.
방식은 다르지만, 결론은 딥시크와 같다. 딥시크의 NSA는 토큰 그룹을 압축, 전체 데이터를 처리하지 않고도 패턴을 인식하는 네이티브 희소 어텐션(native sparse attenmmtion) 방식이다.

테스트 결과, MoBA는 다양한 작업에서 전체 어텐션과 유사한 성능을 보이면서도 긴 시퀀스를 처리할 때 연산 비용을 크게 절감할 수 있었다. 특히, 100만 토큰을 처리할 때 기존의 전체 어텐션보다 약 6배 빠르게 동작했다.
언어 모델링 실험에서는 MoBA의 '퍼플렉시티(perplexity)' 성능은 8192~3만2768 토큰 길이에서도 전체 어텐션 트랜스포머와 성능이 거의 비슷했으며, 컨텍스트를 12만8000토큰 이상으로 늘려도 여전히 강력한 문맥 이해력을 유지했다. 퍼플렉시티는 모델이 다음 단어를 예측할 때 몇개의 후보를 고려하는지를 측정하는 지표로, 후보가 많을수록 모델이 정답을 예측하기 어려운 것을 의미한다.
또 연구진은 ‘후반부 토큰’ 평가를 통해, 긴 프롬프트의 끝부분에 있는 토큰을 예측하는 능력을 측정했다. 기존 어텐션 트랜스포머는 이 부분에서 성능이 떨어지지만, MoBA는 끝부분의 토큰도 정확하게 예측하며 성능 저하 없이 처리했다.
문샷은 "이미 키미챗의 긴 컨텍스트 요청을 지원하기 위해 MoBA를 적용했으며, LLM 효율에서 상당한 진전을 보였다"다"라고 밝혔다. 키미챗은 문샷의 소비자용 챗봇으로, 중국에서 3번째로 많은 사용자를 보유하고 있다.
현재 MoBA 코드는 깃허브에서 다운로드할 수 있다.
박찬 기자 cpark@aitimes.com
