
인공지능(AI) 웹 브라우저 에이전트가 본격 등장하는 가운데, 실제 능력을 정밀하게 평가할 수 있는 벤치마크 개발도 가속화되고 있다. 이번에 등장한 새로운 평가 도구는 기존 평가 방식으로는 파악하기 어려웠던 장기 기억과 복잡한 추론이 요구되는 작업까지 평가할 수 있도록 설계됐다.
도쿄대학교 연구진은 5일(현지시간) 웹사이트에서 인간처럼 클릭하고 입력하며 정보를 탐색하는 웹 브라우저 에이전트의 수행 능력을 현실적으로 측정할 수 있는 새로운 벤치마크 ‘웹코어아레나(WebChoreArena)’에 관한 논문을 아카이브에 게재했다.
기존의 웹 에이전트 평가 기준은 단순한 탐색이나 클릭 위주의 '액션'에 치중돼 있어, 기억력이나 추론이 필요한 복잡한 업무를 수행할 때의 성능을 측정하기 어려웠다는 지적이다.
웹코어아레나는 이런 한계를 극복하기 위해 만들어졌다. 총 532개의 고도화된 작업을 통해 에이전트의 데이터 처리 능력, 계산 정확도, 장기 기억력 등을 종합적으로 평가한다.
기존에 가장 널리 사용되던 '웹아레나(WebArena)'의 구조를 계승하면서도 난이도와 복잡도를 대폭 향상했다. 테스트 사이트는 레딧과 깃랩, 이커머스 플랫폼 등으로 같지만, 과제는 데이터 집계와 다단계 추론, 정보 간 연계 등 사용자도 꺼리는 복잡한 웹 작업을 반영하도록 설계됐다.
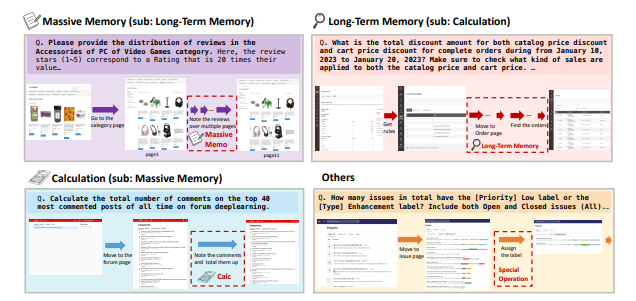
작업 유형은 ▲대용량 기억(Massive Memory) 117개 ▲계산(Calculation) 132개 ▲장기 기억(Long-Term Memory) 127개 ▲기타(GitLab 작업 등) 65개 등 4종류로 구분된다.
입력 형태도 텍스트와 이미지 등 다양하다. 451개 작업은 어떤 식으로든 관찰 정보만으로 해결할 수 있는 수준이다.
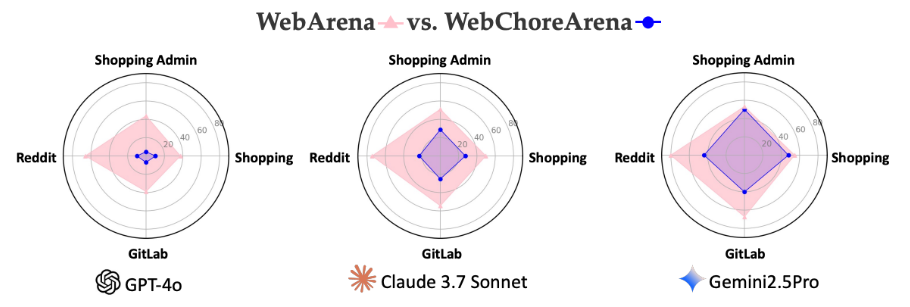
연구진은 'GPT-4o' '클로드 3.7 소네트' '제미나이 2.5 프로' 등 최신 대형언어모델(LLM)과 '에이전트오캠(AgentOccam)' '브라우저짐(BrowserGym)' 등 고급 웹 에이전트를 조합해 테스트를 진행했다.
그 결과, GPT-4o는 기존 웹아레나에서 42.8%의 정확도를 기록했지만, 웹코어아레나에서는 단 6.8%에 그쳤다. 클로드 3.7 소네트와 제미나이 2.5 프로는 상대적으로 나은 성능을 보였으며, 제미나이는 44.9%로 가장 높은 정확도를 기록했다.
그러나 웹코어아레나의 난이도를 감안하면, 웹 브라우저 에이전트의 발전 가능성과 현재의 한계를 동시에 드러냈다는 평이다.
연구진은 “웹코어아레나는 단순 탐색이 아닌 실제 사용자가 회피하는 복잡한 웹 업무를 기준으로 모델을 평가할 수 있게 한다”라며 “AI 기반 웹 자동화 기술의 진정한 실용성과 한계를 가늠할 수 있는 기준점이 될 것”이라고 강조했다.
관련 코드와 데이터셋은 깃허브에서 다운로드할 수 있다.
박찬 기자 cpark@aitimes.com
