다트머스 회의를 공동 개최한 4인 중 한명인 클로드 섀넌이 벨 연구소에서 체스 프로그램을 연구하고 길을 찾아가는 인공지능 쥐 테세우스를 개발한 것은 AI라는 용어가 만들어지기도 전인 1952년이었다. 43년이 흐른 이후인 1995년, 벨 연구소에서는 현재까지 많이 활용되는 2가지의 중요한 머신러닝 알고리즘이 개발 발표됐다. 그중 하나는 소련에서 온 블라디미르 뱁닉과 동료들이 개발한 ‘서포트 벡터 머신’이었으며, 또 다른 하나는 홍콩 출신으로 호 틴캄이 발표한 앙상블 기법의 하나인 ‘랜덤포레스트’였다.
블라디미르 뱁닉(Vladimir Vapnik)은 소비에트 연방의 우즈베키스탄 출신으로, 모스크바의 제어과학 연구소에서 30년간 통계학자로 일한 뒤 1990년에 미국으로 건너와 벨 연구소에서 연구를 계속했다. 그는 1960년부터 알렉세이 체르보넨키스(Alexey Chervonenkis)와 함께 통계적 학습 이론(Statistical Learning Theory)을 연구했고, 뱁닉-체르보넨키스 이론(VC, Vapnik–Chervonenkis theory)를 개발했는데, 이는 서포트 벡터 머신(SVM, Support Vector Machine)의 기반이 됐다. 1993년에 덴마크 출신의 동료 연구원 코르테스(Corinna Cortes)와 함께 SVM을 개발했고, 1995년에 논문으로 발표했다. 뱁닉과 코르테스는 얀 르쿤이 벨 연구소에서 신경망을 활용한 손 글씨 인식 시스템을 개발하던 당시의 동료들이기도 했다.
다른 방법에 비해 최근까지도 많이 사용된 SVM은 분류와 회귀에 모두 사용되는 지도 학습 모델로, 주어진 데이터를 바탕으로 비확률적 이진 선형 분류 공간으로 만들어 새로운 데이터가 어느 공간에 속할지 예측하는 알고리즘이다. 일반적으로 데이터의 특성이 2가지만 있다면 x, y축을 가진 평면상에서 경계를 만드는 선을 그어서 두 그룹으로 분류 가능하다. 그러나 특성이 3가지로 늘어나게 된다면, 데이터는 3차원 입체 공간에 분포하게 되고, 두 그룹을 분류하기 위해서는 선이 아닌 평면으로 경계를 만들어 분리해야 한다.

특성의 개수가 3가지 이상으로 늘어나게 되면, 두 그룹을 분리하는 경계도 평면이 아닌 고차원이 될 수밖에 없고 이를 ‘초평면(hyperplane)’이라고 부른다. 데이터를 분류하는 초평면은 다양한 형태로 나올 수 있는데, 경계면이 분류된 두 그룹의 학습 데이터들과 가장 멀리 떨어지게 되면 분류 오차가 적고 가장 좋은 분류가 되므로, 초평면과 가장 가까운 데이터와의 거리가 최대가 되는 초평면을 선택하는 방식으로 동작하는 알고리즘이다.
신경망이 컴퓨팅 파워, 데이터 가용성 그리고 다른 이론적 문제로 고전하던 1990년대와 2000년대의 시기에 SVM은 AI의 또 다른 돌파구로 큰 각광을 받았다. 사실 SVM의 초기 모델로, 통계적 관점에서 학습 과정을 설명하는 계산 학습 이론의 한 형태인 통계적 학습 이론은 1960년대부터 사용됐다. 이 통계적 학습 이론은 수십년 동안 많은 사람들이 수정하고 개선해 왔는데, SVM으로 표준 모델을 설계해 현재 사용되는 것이 뱁닉과 코르테스의 모델이다.
SVM은 특히 의학 및 기상 분야, 텍스트 분류, 문자 인식, 이미지 분류뿐만 아니라, 머신러닝 전반에 걸쳐 가장 많이 활용된 알고리즘이다. 머신러닝의 대표적인 알고리즘 중 하나로 정밀도가 높은 장점이 있는 반면, 데이터가 커지면 연산에 시간이 많이 걸린다는 단점도 있다.
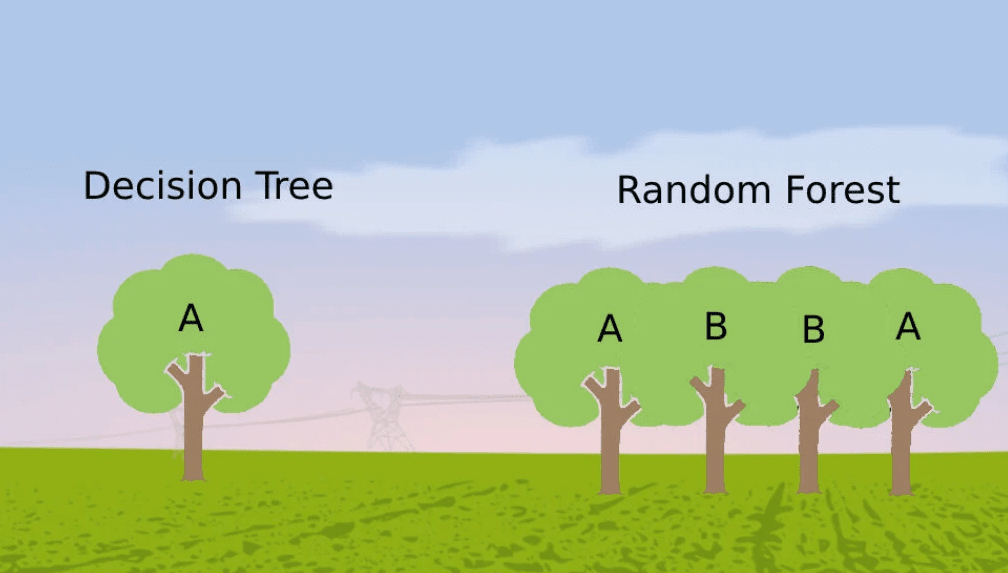
탐색 기법으로 섀넌의 마우스와 그 이후 체커와 체스 프로그램 등에도 사용됐던 ‘의사결정나무(Decision Tree)’ 알고리즘은 데이터 마이닝 분석의 대표적인 방법으로 오랫동안 사용됐다. 이는 데이터의 조건에 따라 가지를 뻗어 나가는 방식으로 결정 과정을 간단한 문제들로 이뤄진 계층 구조로 만드는 것으로, 주로 분류에 사용되며 비수치 데이터에 더 적합한 모델이다. 직관적으로 이해가 쉬운 반면에, 중간 가지에서 발생한 오류는 그 이하의 가지에 모두 영향을 미쳐 모델 전체의 성능에 큰 영향을 미친다는 단점이 있다. 이는 의사결정나무가 계층적 접근 방식이기 때문에 중간에 오류가 발생하면 다음 단계에 계속 전파, 성능 변동 폭이 크다는 의미다.
이를 개선하기 위해 고안된 것이 벨 연구소의 통계 및 학습 연구 부서를 이끌던 호 틴캄(TinKam Ho, 何天琴)이 개발한 랜덤포레스트(Random Forest, Random Decision Forest) 알고리즘이었다. 랜덤포레스트는 주어진 데이터에서 무작위로 선택된 부분 공간으로 훈련 데이터로 구성한, 다수의 의사결정나무를 만들어 분류 또는 회귀 분석해 예측치를 제공하는 방식이다.
이런 다중 트리 학습의 아이디어는 1993에 제시됐는데, 호 틴캄이 과적합 없이 높은 정확도를 얻을 수 있는 알고리즘으로 발전시켜 공개했다. 노이즈가 포함된 데이터에 대해서도 강건성을 보여주며, 간편하고 빠른 학습을 통해 정확성이 훨씬 높아지고 좋은 일반화 특성을 보여주었다.
무작위(Random)로 선택된 부분의 데이터로 훈련 데이터를 구성하고 여러 개의 의사결정 나무(Tree)를 만들어 숲(Forest)이 되었다는 의미에서 랜덤포레스트라는 이름을 갖게 됐다. 현재 널리 사용되는 랜덤포레스트 알고리즘은 호 틴캄의 알고리즘을 바탕으로, 버클리대학교의 통계학자 브레이만(Leo Breiman)이 2001년에 발표한 논문에서 제시한 ‘분류 및 회귀 트리(CART, Classification And Regression Tree)’를 사용해 포레스트를 구성하는 방법이다.

조금씩 다른 특성을 갖는 의사결정 트리 다수를 학습하는 랜덤포레스트는 대표적인 앙상블 기법 중 하나다. 이렇게 이 시기에는 다양한 머신러닝 알고리즘들이 개발되며 이들을 여러개 결합해 더욱 향상된 분류 및 예측 능력을 가진 알고리즘으로 만드는 ‘앙상블(ensemble)’ 기법도 많이 발전했다.
브레이만은 이미 1994년에 "단일 예측기의 불안정성을 극복하려면, 여러 예측기를 결합해야 한다"라고 판단, 배깅(Bagging, Bootstrap Aggregation)이라는 머신러닝 알고리즘을 개발했다. 배깅은 앙상블 학습의 실용적 시작점으로 봤는데, 앙상블 학습의 이론적 시작은 프린스턴 대학 컴퓨터 과학과 교수 샤피르(Robert Schapire)가 1990년에 발표한 ‘부스팅(Boosting)’기법이다. 여러 개의 약한 학습 모델을 순차적으로 결합해서 하나의 강력한 머신러닝 모델로 만드는 부스팅은 머신러닝과 통계학에 상당한 영향을 미쳤다. 이를 기반으로 1997년에 샤피르가 개발한 ‘Adaboosting’을 비롯해 1999년에는 유연한 확장이 가능한 ‘GBM(Gradient Boosting)’이 개발됐고 이후 ‘Logic boosting’, ‘LPBoosting’ 등 다양한 알고리즘으로 진보했다.
1990년대 전반 단순한 모델을 조합해 성능 향상의 가능성을 입증하고 이론적 기초를 마련한 앙상블 알고리즘들은 1990년대 후반 부스팅과 배깅이 독립적으로 발전하며 머신러닝 성능을 크게 높이고 실제 적용 분야를 크게 확대했다. 특히 2006년부터 넷플릭스가 100만달러 상금을 걸고 실시한 추천 알고리즘 대회 ‘넷플릭스 프라이즈(Netflix Prize)’에서 2009년 최종 우승한 팀이 채택되고, 캐글(Kaggle) 머신러닝 대회에서 주요 전략이 되는 등 앙상블은 머신러닝의 표준도구로 자리 잡았다.
문병성 싸이텍 이사 moonux@gmail.com
