
가드레일 없는 오픈 소스 모델로 인기를 얻은 누스 리서치가 강력한 성능과 독창적인 추론 방식을 앞세운 새로운 대형언어모델(LLM) ‘헤르메스 4(Hermes 4)’을 선보였다. 첨단 상용 모델에 맞먹는 수학·코딩·추론 능력을 구현하면서도, 이번에도 거부 응답을 최소화해 자유로운 활용성을 강조했다.
누스 리서치는 28일(현지시간) 하이브리드 추론 모델 ▲헤르메스 4 405B ▲헤르메스 4 70B를 허깅페이스를 통해 오픈 소스로 공개했다.
헤르메스 4는 상용 모델과 달리 거부 응답을 최소화하고, 창의적·자유로운 상호작용을 지향한다. 누스 리서치는 “모델 검열을 최소화하고 사용자 친화적으로 설계했으며, 수학·코딩·추론 능력에서도 최신 상용 시스템과 대등한 수준을 구현했다”라고 밝혔다.
특히 ‘하이브리드 추론’ 기능을 새롭게 도입해, 사용자가 빠른 응답과 단계적 추론 과정을 직접 전환할 수 있도록 했다. 이 과정에서 모델은 <think> 태그 내에 내부 추론 과정을 노출해, 오픈AI의 o1 모델과 유사하면서도 더 투명한 설계를 구현했다.
데이터포지(DataForge)와 아트로포스(Atropos)라는 자체 학습 프레임워크로 훈련됐다. 데이터포지는 단순 데이터를 위키백과 기사·랩 가사·Q&A 생성 등 단계적으로 변환해 복잡한 학습 데이터를 생성한다. 아트로포스는 수학, 코딩, 창작 등 수백 개의 훈련 환경에서 모델이 정답을 낼 때만 피드백을 주는 방식으로 검증된 고품질 데이터만 학습에 반영된다.
헤르메스 4 405B 모델 학습에는 엔비디아 'B200' GPU 192개, 총 7만1616 GPU 시간이 투입됐다. 대규모 인프라 투입 대신, 효율적인 기법을 통해 빅테크와 경쟁 가능한 성과를 낸 것이 특징이다.
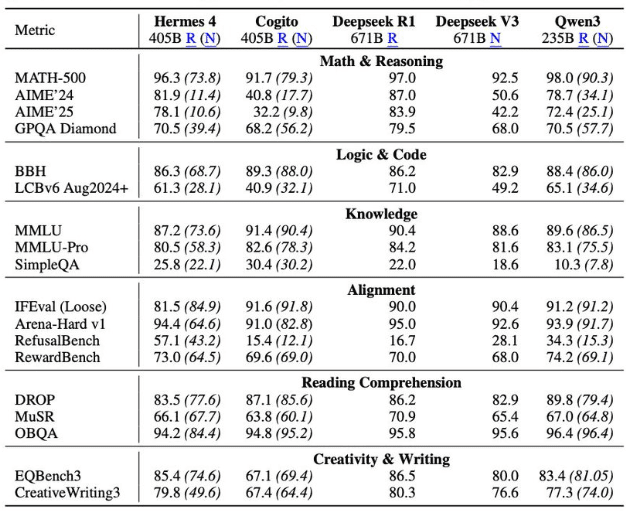
테스트 결과, 405B 모델은 수학 벤치마크 'MATH-500'에서 96.3%, 'AIME24'에서 81.9%를 기록하며, 다수의 폐쇄형 모델을 넘어서는 성능을 보였다.
또 누스 리서치가 자체 개발한 AI의 답변 거부 빈도 측정 벤치마크 '리퓨설벤치(RefusalBench)'에서 57.1%를 기록했다. 이는 'GPT-4o(17.67%)', '클로드 소네트 4(17%)'보다 월등히 높은 수치다.
누스 리서치에 투자한 델파이 벤처스의 토미 쇼네시는 이 모델을 분석하며 "헤르메스 4는 면책 조항, 규칙, 그리고 지나치게 조심스러운 태도에 얽매이지 않는다. 이는 엄청나게 귀찮고 혁신과 사용성을 저해한다"라고 밝혔다.
또 "오픈 소스인데 모든 요청을 거부한다면 의미가 없다. 헤르메스 4에는 문제가 없다"라고 강조했다.
물론, 이런 접근 방식은 유연성을 원하는 AI 연구자와 개발자들에게 인기를 얻었지만, 동시에 AI 안전 문제로 지적받아 왔다.
누스 리서치는 "이론적으로는 AI 모델이 유해한 목적으로 사용될 수 있지만, 그보다는 투명성과 사용자가 직접 통제 가능하다는 점이 더 중요하다"라고 주장했다.
또 인상적인 벤치마크 성능에도 불구하고, 이 모델은 실행에 상당한 컴퓨팅 리소스가 필요하다는 지적도 나왔다. 아직 상용 모델의 사용 편의성이나 안정성을 따라가지 못할 수 있다는 말이다.
박찬 기자 cpark@aitimes.com
