데이터 라벨링 전문 스케일 AI가 지역과 직업, 연령대별로 인공지능(AI) 모델의 성능을 비교·평가하는 새로운 공개 벤치마킹 시스템을 선보였다. 현재 큰 인기를 끄는 LM아레나와 비슷하지만, 테스트 대상이 더 다양하다는 점을 내세웠다.
스케일 AI는 22일(현지시간) 새로운 리더보드 시스템 ‘실 쇼다운(SEAL Showdown)’을 공개했다.
이는 스케일이 기존에 운영하던 리더보드를 확장한 형태로, 100여개국에 걸친 사용자들의 투표를 바탕으로 모델의 일상적 활용도를 평가하는 방식이다. LM아레나처럼 두개의 모델에 같은 질문을 던져, 선호하는 답변에 점수를 주는 블라인드 테스트 방식이다
제이니 구 스케일 AI 제품 매니저는 “참여는 자발적이고 무급이지만, 참가자들은 일반적으로 월 수백달러에 달하는 프론티어 모델에 무료로 접근할 수 있다는 점에서 이를 특혜로 여긴다”라고 설명했다.
또 “일반 기술 애호가나 전문가 위주로 운영되는 다른 플랫폼과 달리, 우리는 의사, 변호사, 물리학자 등 전문직 종사자부터 일반 사용자까지 다양하게 포함돼 있어 결과의 대표성이 높다”라고 강조했다.
이번 출시는 AI 업계가 직면한 고질적 벤치마크 문제를 해소하려는 움직임이다. 현재 다양한 기업들이 신형 AI 모델을 빠르게 내놓고 있지만, 이를 검증하는 표준화된 방식이나 적합한 평가 주체에 대한 합의는 없는 상황이다. 그래서 LM아레나와 같은 크라우드 소싱 방식이 인기를 얻고 있다.
실 쇼다운을 “대표적이고 신뢰할 수 있으며 인간 중심적인 도구”로 정의했다. 이는 글로벌 평균 점수에 의존하기보다는 특정 시장, 팀, 과업에 맞는 모델을 선택할 수 있도록 돕는 데 초점을 맞췄다는 설명이다.
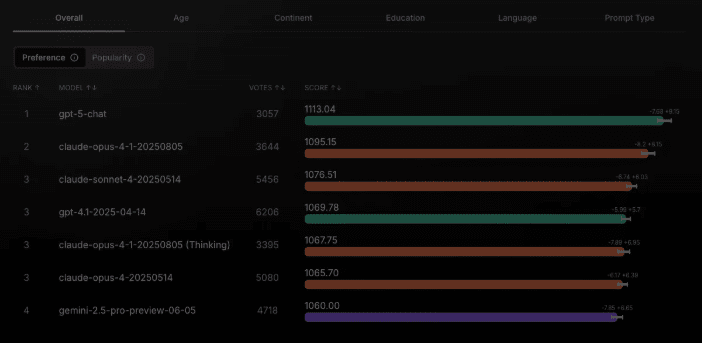
초기 결과도 일부 공개됐다.
현재 실 쇼다운 리더보드에서는 'GPT-5'가 1위를 차지하고 있으며, '클로드 오퍼스 4.1'이 2위, '클로드 소네트 4'가 3위에 올랐다. '제미나이 2.5 프로'는 7위를 기록하고 있다.
또 앤트로픽의 '클로드'는 글쓰기와 추론에서 강점을 보였고, 오픈AI의 '챗GPT'는 브레인스토밍과 분류 작업에서 상대적으로 우수한 성능을 나타냈다. 또 구글의 '제미나이'는 50세 이상 사용자에게서 좋은 평가를 받았지만, 젊은 층에서는 상대적으로 낮은 점수를 기록했다.
박찬 기자 cpark@aitimes.com
