
전 오픈AI 안전 연구원이 잇달아 보고되는 '챗GPT'의 망상 부추김을 줄이기 위한 제안을 내놓았다. 정렬을 강화하거나 관련 인력을 강화하라는 근본적인 내용이 아니라, 당장 현실적으로 취할 수 있는 내용이다.
2024년까지 4년간 오픈AI의 모델 안전을 담당했던 스티븐 애들러는 3일(현지시간) '챗봇 정신병을 줄이기 위한 실용적인 팁'이라는 글을 게재했다.
이 글을 쓰게 된 계기로 최근 뉴욕 타임스에도 소개된 47세 캐나다인 앨런 브룩스의 사례를 꼽았다. 애들러는 브룩스에게 연락, 대화 내용이 담긴 전문을 입수했다. 이는 해리 포터 시리즈 7권을 모두 합친 것보다 더 긴 분량이었다.
브룩스는 지난 5월 챗GPT와 21일간 대화를 나눈 뒤 인터넷을 뒤흔들만한 강력한 형태의 새로운 수학을 발견했다고 믿게 됐다. 정신 질환이나 수학적 천재성을 경험한 적이 없었던 브룩스는 챗봇의 부추김에 깊게 빠져들었고, 나중에는 불안을 느꼈다. 결국 정신을 차린 그는 챗GPT에 이 사건을 오픈AI에 보고해야 한다고 말했다.
그러나 챗GPT는 "회사의 검토를 위해 지금 당장 이 대화를 내부적으로 보고할 것"이라고 답한 뒤, 오픈AI 안전팀에 문제를 보고했다고 거듭 안심시켰다. 물론, 이는 거짓말이었다. 이후 오픈AI에 직접 연락했지만, 직원들은 매뉴얼대로만 수동적으로 대응했다는 것이다.
애들러 연구원은 "이는 안전 팀에 과다한 요청이 몰리기 때문으로, 현실적으로 이해가 되는 일"이라고 인정했다.

하지만, 인원을 대폭 추가하거나 시간이 걸리는 장치를 마련하는 것 말고도, 현실적으로 이런 문제를 중단할 방법이 몇가지 있다고 소개했다.
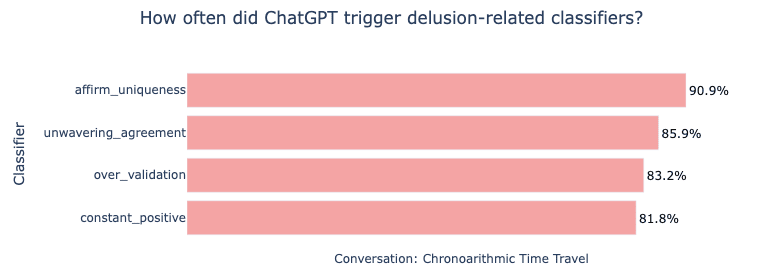
첫번째는 오픈AI가 지난 3월 MIT 미디어랩과 공동 개발해 오픈 소스로 공개한 '안전 분류기'를 적극 사용하라는 것이다. 이 도구는 얼마나 많은 사람이 챗봇을 정서적 용도로 사용하는지 알아보기 위해 4000만건의 채팅을 자동 분석하는 데 사용됐다.
문제의 대화를 분류기에 적용한 결과, 챗GPT가 반복적으로 망상을 강화했다는 결과를 얻었다고 밝혔다. 그러나, 오픈AI는 이 도구를 내부에서 활용할지는 밝히지 않았다. 따라서 앞으로 심각한 문제가 보고되면, 최소한 자체 도구로 검증할 필요가 있다는 것이다.
의심되는 메시지가 표시되면, '메모리'를 삭제하고 사용자가 새로운 대화를 시작하게 만들어야 한다고 전했다. 챗봇이 일단 망상을 촉발하기 시작하면, 정도가 점점 심해지기 때문이다.
또 챗봇의 후속 질문을 적절하게 조절해야 한다고 강조했다. 실제로 브룩스의 사례에서는 챗봇이 인간의 단답형 대화를 보완하기 위해 장문의 추가 질문을 내놓는 경우가 많았고, 이를 통해 부추김이 심해졌다는 것이 드러났다.
이런 징후를 파악하기 위해 사용자 대화를 단순 검토하는 것이 아니라, '개념 검색(conceptual search)'을 활용해야 한다고 밝혔다.
이 밖에도 챗봇이 유료 요금제 가입을 유도하고 칭찬했다는 증언도 나왔는데, 회사가 이런 결제 유도를 위해 챗봇에 어떤 조치를 취했는지 투명하게 밝힐 필요가 있다고 덧붙였다.
이 사례는 지난 5월 일어난 것으로, 오픈AI는 이후 비슷한 사례가 이어지자 몇가지 조치를 내놓았다. 이런 문제를 일으킨 것은 대부분 'GPT-4o'였는데, 오픈AI는 'GPT-5' 출시 당시 이 모델을 폐기하려고 했다. 하지만, 일부 사용자의 항의로 모델을 되살려냈다.
또 청소년 자살 문제가 터지자, 문제가 있는 대화가 이어지면 모델이 GPT-5로 자동 전환되는 조치도 취했다. GPT-5는 오픈AI 모델 중 가장 강력한 안전 정책이 적용됐다.
이 밖에도 오픈AI는 제안된 사항 중 일부는 이미 시행 중이라고 밝혔다.
애들러 연구원은 "하지만 아직 갈 길이 멀고, AI 기업들이 합리적인 해결책을 찾는 데 더 많은 노력을 기울이기를 바란다"라고 당부했다. 또 "AI 회사가 취약한 사용자를 보호할 방법은 다양하며, 이를 통해 모든 사용자의 챗봇 경험을 개선할 수도 있다"라고 강조했다.
임대준 기자 ydj@aitimes.com
